如何查看及分析网站IIS日志文件
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何查看及分析网站IIS日志文件相关的知识,希望对你有一定的参考价值。
1、进入服务器的管理之后,打开“Internet 信息服务(IIS)管理器”,2、双击信息服务(IIS)管理器,进入管理以后打开信息服务(IIS)管理器,选中要查看的网站,在网站栏目那里右键单击,选择“属性”,
3、在弹出的窗口里面,点击“网站”栏目,查看日志记录中的“属性”,
4、通过日志记录属性栏目,即可看到日志文件目录了,
上面的日志文件目录即是iis的文件存放位置了,IIS日志文件便在C:\\WINDOWS\\system32\\LogFiles\\文件夹内。
IIS日志文件存储格式是后缀名为log的文本文件,如下面这些文件就是网站的iis日志了。
要查看对应站点的IIS日志,只需要打开对应IIS日志文件夹找到相对应日志文件即可,也可借助IIS日志分析工具提供查看IIS日志的效率!
三、如何分析IIS日志?
知道了IIS日志的位置了,也看到了IIS日志的文件了,接下来我们就应该对日志文件进行分析了,那么,我们该如果分析IIS日志呢?
1、如何查看IIS日志信息
IIS日志可以用IIS日志分析工具去大概的去查一查,一般工具都能查出有各种蜘蛛来到网站的总数,以及有没有失败,不会把各种的信息都给你,工具分析只是简单的告诉你一个概况,马海祥在此就拿出一条信息来为大家具体的分析一下,如下面的截图所示:
我们可以分段对这个IIS日志进行分析:
2010-10-22 05:04:53 表示的是时间;
W3SVC151800 P-0YMR9WW8YX4U9是机器编号;
222.76.213.49为网站的IP;
GET是触发事件;
80是端口号;
61.135.186.49是搜索引擎蜘蛛的IP;
Baiduspider是百度的蜘蛛(另外,谷歌蜘蛛:Googlebot;360搜索蜘蛛:360Spider,更多的可查看马海祥博客《解读iis日志中搜索引擎蜘蛛名称代码及爬寻返回代码》的相关介绍);
200 0 0是访问成功的返回代码;
41786 193 6968是蜘蛛与网站对话的时间与下载的数据以及花了多少时间。
连在一起就是2010.10.22的早上5点4分53秒的时候一个编号为W3SVC151800 P-0YMR9WW8YX4U9的蜘蛛通过80端口进入网站成功访问并下载了47186B的数据,花费了193MS。
2、用excel表格分析网站的iis日志
先新建一个excel表格,把刚才的ex121129.log文件里的文件粘贴到新建的excel表格里面,,如下图所示:
复制之后,选定A,在工具栏里选择数据→分列,如下图所示:
选择分隔符号,点击下一步:
选择空格,去掉Tab键前面的钩,点击完成,如下图所示:
网站的iis日志就这样被拆分出来了,之后自己再调整一下表格的列宽、升降序等即可。
四、详解IIS日志参数
一般情况下,IIS日志文件代码格式如下所示:
#Software: Microsoft Internet Information Services 6.0
#Version: 1.0
#Date: 2009-11-26 06:14:21
#Fields: date time s-sitename s-ip cs-method cs-uri-stem cs-uri-query s-port cs-username c-ip cs(User-Agent) sc-status sc-substatus sc-win32-status
2009-11-26 06:14:21 W3SVC692644773 125.67.67.* GET /index.html - 80 - 123.125.66.130 Baiduspider+(+http://www.baidu.com/search/spider.htm) 200 0 64
2009-11-26 06:14:21 W3SVC692644773 125.67.67.* GET /index.html - 80 - 220.181.7.116 Baiduspider+(+http://www.baidu.com/search/spider.htm) 200 0 64
在此,马海祥也为大家详细的解说一下IIS日志参数:
date:发出请求时候的日期。
time:发出请求时候的时间,注意:默认情况下这个时间是格林威治时间,比我们的北京时间晚8个小时,下面有说明。
c-ip:客户端IP地址。
cs-username:用户名,访问服务器的已经过验证用户的名称,匿名用户用连接符-表示。
s-sitename:服务名,记录当记录事件运行于客户端上的Internet服务的名称和实例的编号。
s-computername:服务器的名称。
s-ip:服务器的IP地址。
s-port:为服务配置的服务器端口号。
cs-method:请求中使用的HTTP方法,GET/POST。
cs-uri-stem:URI资源,记录做为操作目标的统一资源标识符(URI),即访问的页面文件。
cs-uri-query:URI查询,记录客户尝试执行的查询,只有动态页面需要URI查询,如果有则记录,没有则以连接符-表示,即访问网址的附带参数。
sc-status:协议状态,记录HTTP状态代码,200表示成功,403表示没有权限,404表示找不到该页面,具体说明在下面。
sc-substatus:协议子状态,记录HTTP子状态代码。
sc-win32-status:Win32状态,记录Windows状态代码。
sc-bytes:服务器发送的字节数。
cs-bytes:服务器接受的字节数。
time-taken:记录操作所花费的时间,单位是毫秒。
cs-version:记录客户端使用的协议版本,HTTP或者FTP。
cs-host:记录主机头名称,没有的话以连接符-表示。马海祥提醒大家注意:为网站配置的主机名可能会以不同的方式出现在日志文件中,原因是HTTP.sys使用Punycode编码格式来记录主机名。
cs(User-Agent):用户代理,客户端浏览器、操作系统等情况。
cs(Cookie):记录发送或者接受的Cookies内容,没有的话则以连接符-表示。
cs(Referer):引用站点,即访问来源。
五、搜索引擎蜘蛛爬寻返回代码
HTTP协议状态码的含义,协议状态sc-status,是服务器日记扩展属性的一项,下面是各状态码含义:
"100" :Continue,客户必须继续发出请求。
"101" :witching Protocols,客户要求服务器根据请求转换HTTP协议版本。
"200" :OK,交易成功。
"201" :Created,提示知道新文件的URL。
"202" :Accepted,接受和处理、但处理未完成。
"203" :Non-Authoritative Information,返回信息不确定或不完整。
"204" :No Content,请求收到,但返回信息为空。
"205" :Reset Content,服务器完成了请求,用户代理必须复位当前已经浏览过的文件。
"206" :Partial Content,服务器已经完成了部分用户的GET请求。
"300" :Multiple Choices,请求的资源可在多处得到。
"301" :Moved Permanently,删除请求数据。
"302" :Found,在其他地址发现了请求数据。
"303" :See Other,建议客户访问其他URL或访问方式。
"304" :Not Modified,客户端已经执行了GET,但文件未变化。
"305" :Use Proxy,求的资源必须从服务器指定的地址得到。
"306" :前一版本HTTP中使用的代码,现行版本中不再使用。
"307" :Temporary Redirect,申明请求的资源临时性删除。
"400" :Bad Request,错误请求,如语法错误。
"401" :Unauthorized,请求授权失败。
"402" :Payment Required,保留有效ChargeTo头响应。
"403" :Forbidden,请求不答应(具体可查看马海祥博客《403 Forbidden错误的原因和解决方法》的相关介绍)。
"404" :Not Found,没有发现文件、查询或URl(具体可查看马海祥博客《404 Not Found错误页面的解决方法和注意事项》的相关介绍)。
"405" :Method Not Allowed,用户在Request-Line字段定义的方法不答应。
"406" :Not Acceptable,根据用户发送的Accept拖,请求资源不可访问。
"407" :Proxy Authentication Required,类似401,用户必须首先在代理服务器上得到授权。
"408" :Request Time-out,客户端没有在用户指定的饿时间内完成请求。
"409" :Conflict,对当前资源状态,请求不能完成。
"410" :Gone,服务器上不再有此资源且无进一步的参考地址。
"411" :Length Required,服务器拒绝用户定义的Content-Length属性请求。
"412" :Precondition Failed,一个或多个请求头字段在当前请求中错误。
"413" :Request Entity Too Large,请求的资源大于服务器答应的大小。
"414" :Request-URI Too Large,请求的资源URL长于服务器答应的长度。
"415" :Unsupported Media Type,请求资源不支持请求项目格式。
"416" :Requested range not satisfiable,请求中包含Range请求头字段,在当前请求资源范围内没有range指示值,请求也不包含If-Range请求头字段。
"417" :Expectation Failed,服务器不满足请求Expect头字段指定的期望值,假如是代理服务器。
"500" :Internal Server Error,服务器产生内部错误。
"501" :Not Implemented,服务器不支持请求的函数。
"502" :Bad Gateway,服务器暂时不可用,有时是为了防止发生系统过载。
"503" :Service Unavailable,服务器过载或暂停维修。
"504" :Gateway Time-out,关口过载,服务器使用另一个关口或服务来响应用户,等待时间设定值较长。
"505" :HTTP Version not supported,服务器不支持或拒绝支请求头中指定的HTTP版本。 参考技术A
第一种方法:
1、登录你的网站空间,ISS日志下载地址:如图:
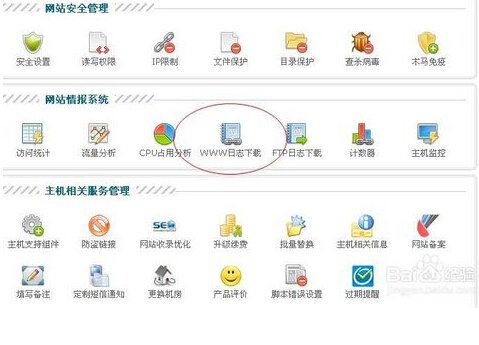
点击下载WWW日志下载,进入下载
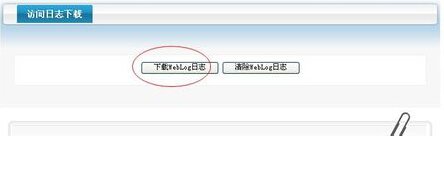
第二种方法:
通过ftp登陆到网站空间,找到根目录下的LogFiles这个文件夹,然后把里面的日志文件通过ftp下载下来。
网站日志分析要注意404、500这样的代码,
"404" :Not Found,没有发现文件、查询或URl
"500" :Internal Server Error,服务器产生内部错误。
出现这两种代码对网站的优化不利。
参考技术B 1.进入服务器的管理之后,打开“Internet 信息服务(IIS)管理器”2.进入管理以后打开服务器(本地计算机)
3.双击服务器(本地计算机),在网站栏目那里右键单击选择属性。
在弹出的窗口里面,网站栏目点击属性
上面的日志文件目录即是iis的文件存放位置了,在C:\WINDOWS\system32\LogFiles\W3SVC20110218打开文件夹。
这些文件就是网站的iis日志了。
知道了IIS日志的位置了,接下来我们就应该对日志文件进行分析了,那么如果分析呢?
1. IIS日志后可以用IIS日志分析工具去大概的去查一查IIS日志。一般工具都能查出有各种蜘蛛来到网站的总数,以及有没有失败,不会把各种的信息都给你。并不是工具分析没有出现失败的我们就不用一条一条看了,工具分析只是简单的告诉你有没有失败,没有失败当然是皆大欢喜了,但是来是一条一条的去分析。我们拿出这样子的一条信息来分析一下
首先是时间:2010-10-22 05:04:53 机器编号为W3SVC151800 P-0YMR9WW8YX4U9 222.76.213.49是网站的IP GET是触发事件, 80是端口号,61.135.186.49是蜘蛛的IP,Baiduspider是百度的蜘蛛,200 0 0访问成功, 41786 193 6968 是蜘蛛与网站对话的时间与下载的数据以及花了多少时间。连在一起就是2010.10.22的早上5点4分53秒的时候一个编号为W3SVC151800 P-0YMR9WW8YX4U9的蜘蛛通过80端口进入网站成功访问并下载了47186B的数据,花费了193MS。
百度的蜘蛛名字:Baiduspider、google蜘蛛名字:googlebot 、有道的蜘蛛名字:YoudaoBot、yahoo的蜘蛛的名字:slurp。
IIS日志基本上都是这样子的,区别在于上面那个是成功抓取:200 0 0
一下是FTTP状态码:
404(未找到)服务器找不到请求的页面
304 (未修改)自从上次请求后,请求的页面未修改过,服务器返回此响应时,不会返回网页内容
503 (服务不可用)服务器目前无法使用(由于超时或停机维护)
301 永久重定向
302 临时重定向
基本上我们要了解的就是这些FTTP状态码,如果你的网站出现了404,那你就要立刻用robots进行屏蔽,404是死链接,如果出现了404的话搜索引擎会认为你欺骗用户,会对你作出处罚。大面积出现304的话那就要注意了,网站没有更新,一二条关系不大,但是多了就会让搜索引擎认为你网站没有人管理,时间长了就会导致网站快照不更新,关键词的波动;出现了503是你无法解决的,你就要找服务器供应商。如果是连续同一时间出现503的时候我建议你去换一个服务器,因为他在那个时候判断服务器导致蜘蛛进不去,蜘蛛不能进你的网站,搜索就不会了解,就会降低信任度,降权也随之开始了。301是永久重定向,是网站改换了使用的,可以从这里判断你的301做的怎么样,成功了没有。302临时的重定向,当做策划什么活动的时候可以使用。
2. 用excel表格分析网站的iis日志。
先新建一个excel表格,把刚才的ex121129.log文件里的文件粘贴到新建的excel表格里面。
复制之后,选定A
在上面的工具栏里选择数据→分列
选择分隔符号,点击下一步
选择空格,去掉Tab键前面的钩,点击完成。
网站的iis日志就这样被拆分出来了,之后自己再调整一下表格的列宽、升降序等即可。
以上是关于如何查看及分析网站IIS日志文件的主要内容,如果未能解决你的问题,请参考以下文章