在100,000个核心集群上运行100万个作业
Posted 容器技术爱好者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了在100,000个核心集群上运行100万个作业相关的知识,希望对你有一定的参考价值。
随着客户在更大的环境中部署OpenLava。可扩展性,吞吐量和性能变得越来越重要。为了满足这些领域的客户需求,OpenLava 提供了一些重要的增强功能:o 并行化作业事件处理以加速集群启动并最小化停机时间。
o 增强的守护进程间通信,提高效率和性能。
o 其他调整参数,为集群管理员提供其他工具,以提高性能,响应速度和可扩展性。
在发布OpenLava之前,天云软件使用HPC Cluster-as-a-Service在100,000个内核组成的集群上进行了大规模测试,这是我们迄今为止进行过的最大的测试。
测试的目的是证明:
- OpenLava可以管理大规模工作负载 – 1,000,000个作业跨越近100,000个内核。
- OpenLava可以处理EDA(电子设计自动化)仿真环境(平均运行时间大约为4分钟)中常见的大型工作负载模式类型。
- OpenLava可以快速调度作业并响应用户命令,即使在负载非常高的时段。
- OpenLava可以大规模实施复杂的资源共享策略(例如,fairshare),以增加现实性。
- OpenLava可以可靠地运行大型工作负载,而无需丢失作业,这是业务关键型模拟环境的基本要求
测试环境
为了进行测试,使用HPC Cluster-as-a-Service产品在Amazon Web Services上提供了由大约100,000个核心组成的1,000个节点集群。使用HPC集群可以大幅节省时间和精力。使用Amazon c4.xlarge计算机类型(4个vCPU,内存为7.5 GB)配置主主机,其余999个计算主机均配置为t2.micro实例(1个vCPU,1 GB RAM),以降低成本。
每个t2.micro主机在OpenLava下配置了100个作业插槽,使其从OpenLava调度程序的角度看来与具有100个核心的鲁棒计算主机相同。
此外,在更稳健的主机上配置了20个作业插槽,以允许作业运行。
由于在大型环境中,AWS提供的三个主机无法启动。而不是花费时间排除类似于AWS瞬态错误的失败主机,总共99,620内核进行了测试:
- 每个计算主机有100个插槽,共99,600个模拟核心。
- 主机上有20个可用内核。
在AWS上自动配置OpenLava集群后,对OpenLava配置文件进行了其他更改以支持测试。
Begin UserGroup
GROUP_NAME GROUP_MEMBER USER_SHARES
G(all)([default,1])
ga(u0 u1 u2)([u0,1] [u1,2] [u2,3])
gb(u3 u4 u5)([default,1])
gc(ga u6)([ga,1] [u6,1])
gd(u7)([default,1])
End UserGroup
为上面引用的八个用户(u0到u7)中的每一个创建了操作系统级别登录帐户,并且帐户被配置为在登录时获取OpenLava环境。
此外,在lsb.queues中,与正常队列定义相关联的FAIRSHARE行未注释和更改,以反映所需的共享策略。请注意,组A被排除在共享策略外,因为共享策略中的组C引用组A的成员。
正常队列定义:
FAIRSHARE = USER_SHARES [[gb,2] [gc,1] [gd,1]]
在lsb.queues文件中配置的其他4个队列(优先级,所有者,短和空闲)中,指定了相等的共享:
优先级,所有者,短队列和空闲队列的队列定义:
FAIRSHARE = USER_SHARES [[default,1]]
进行这些更改后,群集已重新配置。
下面的脚本包括实际测试。测试包括代表八个指定用户提交工作,这八个指定用户是上面定义的四个组的成员。该脚本执行一个循环,涉及提交200个作业数组,每个数组由1000个元素组成。在每次迭代中,八个用户之一向五个队列中的每个队列提交一个1,000元素作业数组,总共有5000个作业。
在完成脚本后,将提交20万个工作,每个队列有40,000个工作。该脚本在8个操作系统级用户中平均分配20万个作业,以便每个用户运行25,000个作业。在该示例中,通过睡眠命令来模拟工作负荷,工作量的持续时间在三到五分钟之间变化。
$ RANDOM在bash中引用时,返回0到32767之间的整数,因此脚本中显示的值$ RANDOM%120(模数)返回0到119秒之间的值。在下面的脚本中,对于每个作业的180到299秒(大约3-5分钟)之间的范围,将所得到的随机数加到180秒的值中。
就调度器与主机的关联而言,sleep命令表示与可能在生产中运行的计算密集型任务相同的工作负载。
下面的脚本运行了五次,共产生了1,000,000个作业,每个作业的运行时间在三到五分钟之间。
#!/bin/bash
u=0
um=7
j=1
jm=200
QLIST=”normal owners priority idle short”
while true; do
# echo user: u${u}
for queue in $QLIST; do
n=`expr 180 + $RANDOM % 120`
su u${u} -c “bsub -q $queue -J test[1-1000] /bin/sleep $n”
done
u=$((u+1))
if [ $u -gt $um ]; then
u=0
fi
j=$((j+5))
if [ $j -gt $jm ]; then
break
fi
sleep 1
done
结果
图1显示了工作量随时间的推移。x轴表示时间,曲线表示已提交作业的数量,已完成作业的数量和待处理作业的数量。提交的工作数量中明显的五个“步骤”表明该脚本运行了五次,每次运行额外增加了20万个作业。
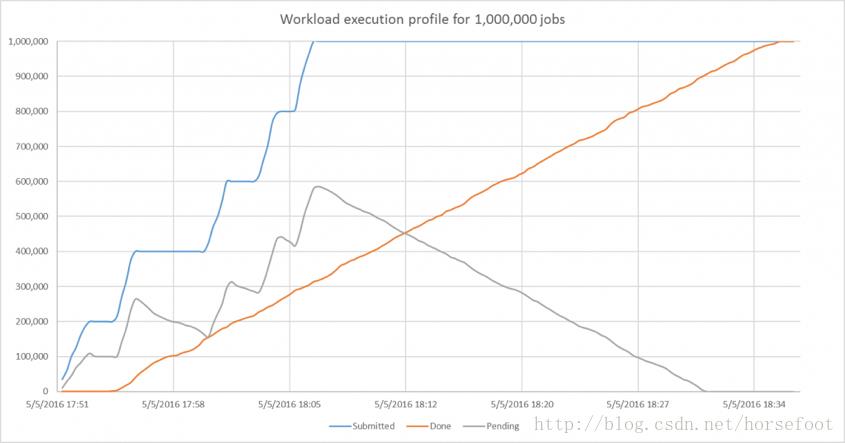
图1 – 1,000,000个工作基准的工作负载配置文件
我们的997节点群具有同时运行996 * 100 + 20 = 99,620个作业的理论容量。因为每个作业平均持续时间为4分钟,所以集群的理论吞吐量为每分钟24,905个作业。在这个理论层面,完成1,000,000需要1,000,000 / 24,905或略超过40分钟。实际上,大约需要花费41分钟能够达到时隙调度利用率约99%。
考虑到调度器还每秒平均接受400个新作业,同时基于涉及五个队列和八个用户的合理复杂的公平共享策略分派作业,图2所示的99%的时隙利用率已经达到非常高的水平。
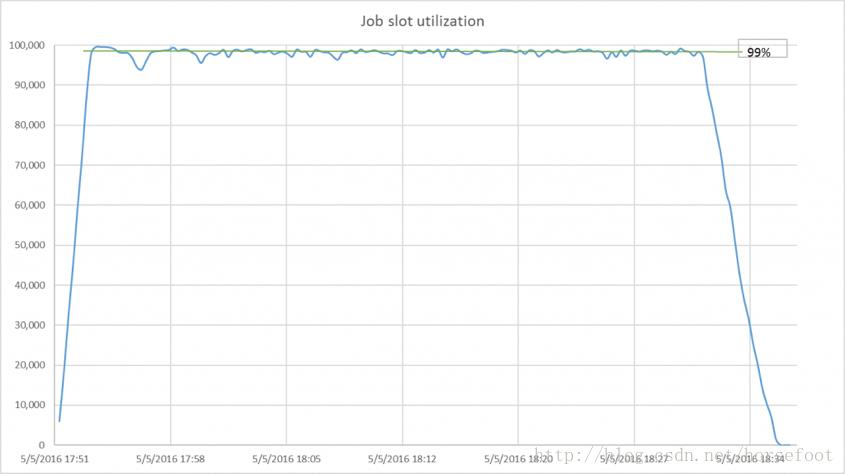
图2 – 99%的效率
图3显示了在测试中的OpenLava Enterprise Edition Web仪表板的视图。
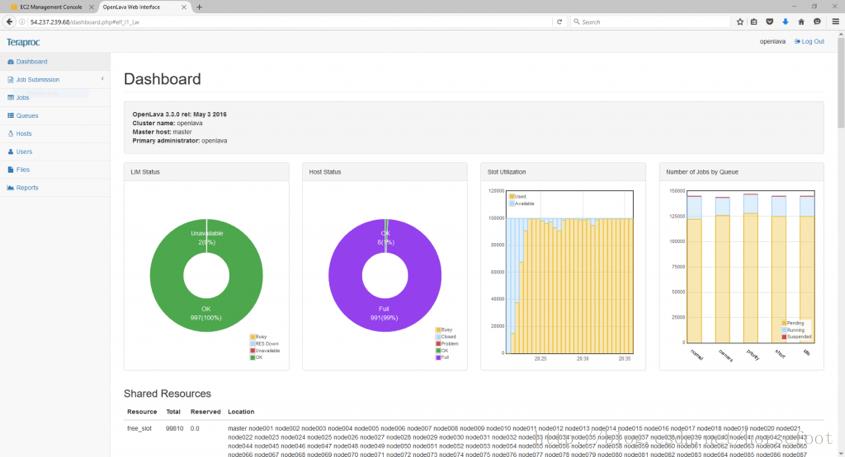
图3 – OpenLava Enterprise Edition Web信息中心
图4是OpenLava企业版生成的报告,用于演示在运行期间如何强制执行fairshare。
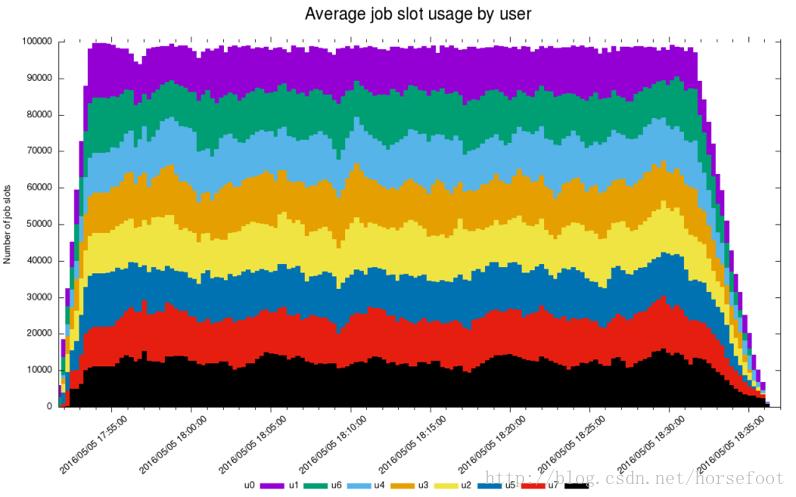
图4 – 用户在100,000个核心群集上的平均作业插槽使用情况
下面的OpenLava lshosts命令显示每个主机的配置。主主机是具有4个vCPU和7.5 GB内存的c4.xlarge。其他主机是如上所述的AWS t2_micro实例。
HOST_NAME type model cpuf ncpus maxmem maxswp server RESOURCES
master linux IntelI5 100.0 4 7492M – Yes ()
node001 linux IntelI5 100.0 1 994M – Yes ()
node002 linux IntelI5 100.0 1 994M – Yes ()
node003 linux IntelI5 100.0 1 994M – Yes ()
node004 linux IntelI5 100.0 1 994M – Yes ()
node005 linux IntelI5 100.0 1 994M – Yes ()
node006 linux IntelI5 100.0 1 994M – Yes ()
node007 linux IntelI5 100.0 1 994M – Yes ()
node008 linux IntelI5 100.0 1 994M – Yes ()
node009 linux IntelI5 100.0 1 994M – Yes ()
node010 linux IntelI5 100.0 1 994M – Yes ()
node011 linux IntelI5 100.0 1 994M – Yes ()
node012 linux IntelI5 100.0 1 994M – Yes ()
node013 linux IntelI5 100.0 1 994M – Yes ()
node014 linux IntelI5 100.0 1 994M – Yes ()
…
node998 linux IntelI5 100.0 1 994M – Yes ()
node999 linux IntelI5 100.0 1 994M – Yes ()
结论
通过运行1,000,000个作业和99,620个内核的测试,OpenLava已经证明它能够满足大多数HPC环境的需求,同时提供良好的调度效率。研究结果如下:
- OpenLava能够运行1,000,000个工作,每个工作平均运行时间为99,620个内核,平均运行时间为4分钟,同时遵守具有99%插槽使用效率的调度策略。
- 即使在调度器完全加载时,OpenLava也能在所有情况下响应命令。
-
OpenLava执行可靠,不会丢失任何工作。
以上是关于在100,000个核心集群上运行100万个作业的主要内容,如果未能解决你的问题,请参考以下文章