爬取百度热搜榜并把数据可视化
Posted libao123
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬取百度热搜榜并把数据可视化相关的知识,希望对你有一定的参考价值。
1.目标爬取百度热搜榜(百度热搜榜网址:https://top.baidu.com)
2.对爬取的数据进行清洗和分析
爬取网站的“关键词”“相关链接”“搜索指数”
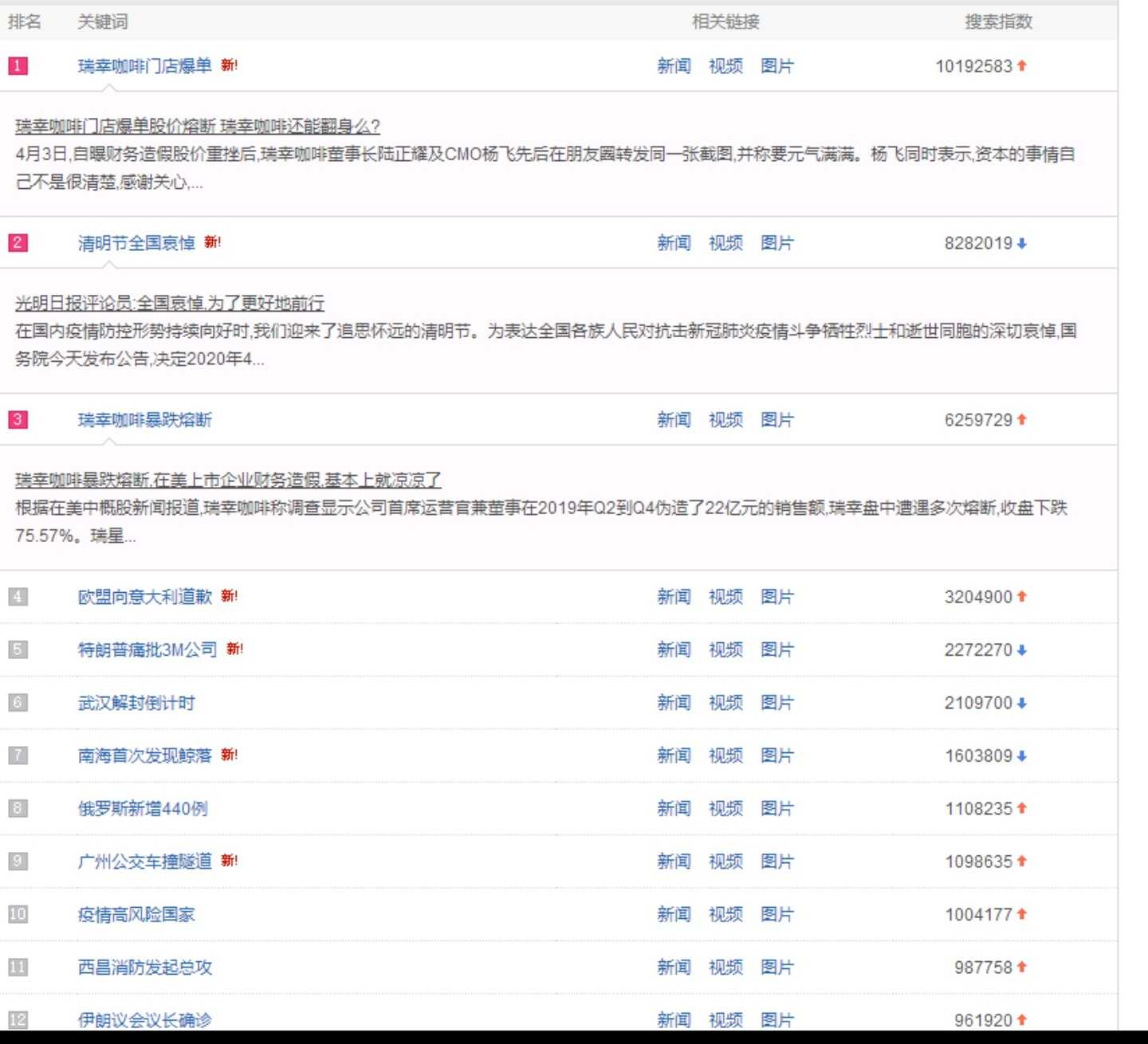
3.进行数据可视化
实现思路:1.到该网页使用f12查看源代码,查找所要爬取的数据。
2.使用get或post进行数据爬取。
3.提取有用的数据。
4.使用pandas库将数据转化为二维表。
5.使用pandas库进行数据的清洗
6.使用matplotlib库进行数据可视化。
技术难点:爬取数据以及对数据的转化。
1.源代码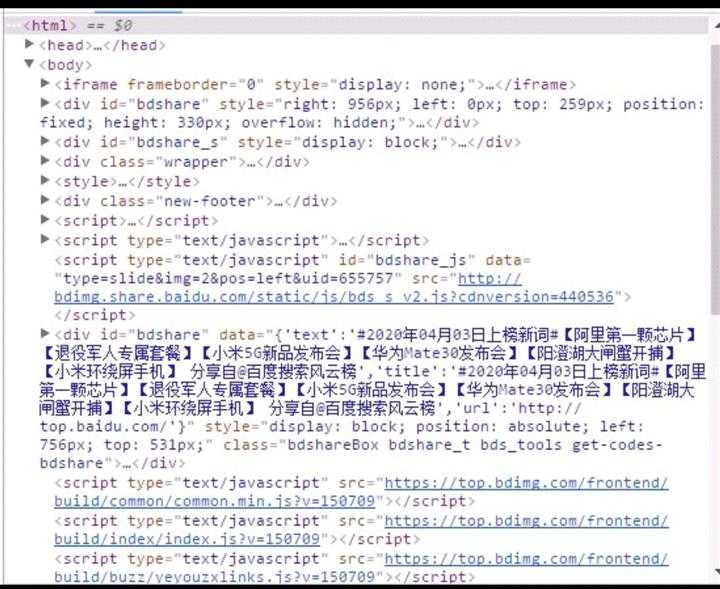
URL:http://top.baidu.com.
2爬取代码如下
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
from scipy.optimize import leastsq
import requests
from bs4 import BeautifulSoup
import pandas as pd
import csv
import jieba
import wordcloud
import requests
from lxml import etree
head = {}
url = "http://top.baidu.com/buzz?b=341&fr=topindex
head["User-Agent"] = "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:63.0) Gecko/20100101 Firefox/63.0"
head["Accept"]= "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8"
head["Accept-Language"]= "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2"
head["Connection"] = "keep-alive"
def main():
print("百度热搜top:
res = requests.get(url , headers = head)
with open("html.txt", "wb") as f:
f.write(res.content)
html = etree.parse(‘html.txt‘ , etree.HTMLParser(encoding=‘gbk‘)
top_list = html.xpath(‘//a[@class="list-title"]/text()‘
num_search = html.xpath(‘//span[@class="icon-rise"]/text()‘
for i , j in zip(top_list[:10] , num_search[:10]):
print(i ,"搜索指数为:" , j )
if __name__ == ‘__main__‘
main()
对数据进行清洗:
1 import pandas as pd 2 kugou=pd.DataFrame(pd.read_excel(‘data.xls‘)) 3 kugou.head() 4 kugou.drop(1,axis=0,inplace=True) 5 kugou.head()
以上是关于爬取百度热搜榜并把数据可视化的主要内容,如果未能解决你的问题,请参考以下文章