bs4爬取笔趣阁小说
Posted smart-zihan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了bs4爬取笔趣阁小说相关的知识,希望对你有一定的参考价值。
参考链接:https://www.cnblogs.com/wt714/p/11963497.html
模块:requests,bs4,queue,sys,time
步骤:给出URL--> 访问URL --> 获取数据 --> 保存数据
第一步:给出URL
百度搜索笔趣阁,进入相关网页,找到自己想要看的小说,如“天下第九”,打开第一章,获得第一章的URL:https://www.52bqg.com/book_113099/37128558.html
第二步:访问URL
def get_content(url): try: # 进入主页 # https://www.52bqg.com/ # 随便搜索一步小说,找出变化规律 # https://www.52bqg.com/book_110102/ headers = { ‘User-Agent‘: "" } res = requests.get(url=url, headers=headers) res.encoding = "gbk" content = res.text return content except: s = sys.exc_info() print("Error ‘%s‘ happened on line %d" % (s[1], s[2].tb_lineno)) return "ERROR"
返回的是此页面的内容
第三步:获取数据
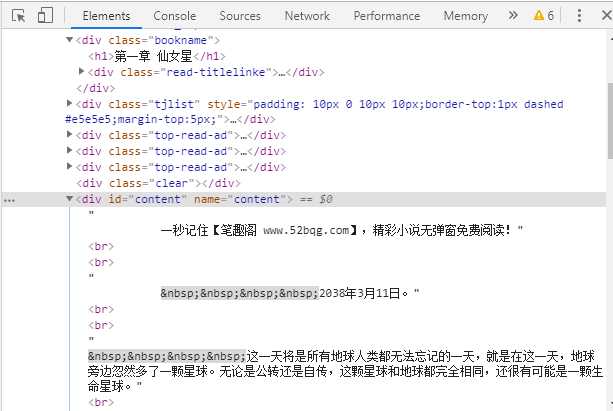
def parseContent(first_url, content): soup = BeautifulSoup(content, "html.parser") chapter = soup.find(name=‘div‘, class_="bookname").h1.text content = soup.find(name="div", id="content").text
chapter获取的就是每一章的名称,例如:第一章 仙女星
content获取的就是每一章的内容,例如:这一天将是所有地球。。。。
第四步:保存数据
def save(chapter, content): filename = 文件名字 f = open(filename, "a+", encoding="utf-8") f.write("".join(chapter) + " ") f.write("".join(content.split()[2:]) + " ") f.close()
以上就是爬取数据的一般步骤,介绍了一章是如何爬取下来的,那么一本小说,有很多很多章,全部爬取下来的话,就将上面的步骤一次又一次的进行就好了。
这里采取的方法是队列形式,首先给出第一章的url,存放到一个队列中,然后从队列中提取url进行访问,在访问过程中找到第二章的url,放入队列中,然后提取第二个url访问,依次类推,直到将小说所有章节爬取下来,队列为空为止。文件名字这一块,也是通过访问小说的url获取到小说名字,然后以小说名字命名txt的名字。
完整代码如下:


#!/usr/bin/env python # _*_ coding: UTF-8 _*_ """================================================= @Project -> File : Operate_system_ModeView_structure -> get_book_exe.py @IDE : PyCharm @Author : zihan @Date : 2020/4/25 10:28 @Desc :爬取笔趣阁小说: https://www.52bqg.com/ 将url放入一个队列中Queue 访问第一章的url得到第二章的url,放入队列,依次类推 =================================================""" import requests from bs4 import BeautifulSoup import sys import time import queue # 获取内容 def get_content(url): try: # 进入主页 # https://www.52bqg.com/ # 随便搜索一步小说,找出变化规律 # https://www.52bqg.com/book_110102/ headers = { ‘User-Agent‘: "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36" } res = requests.get(url=url, headers=headers) # 获取小说目录界面 res.encoding = "gbk" content = res.text return content except: s = sys.exc_info() print("Error ‘%s‘ happened on line %d" % (s[1], s[2].tb_lineno)) return "ERROR" # 解析内容 def parseContent(q, first_url, content): base_url_list = first_url.split("/") html_order = base_url_list[-1] last_number = first_url.find(html_order) base_url = first_url[:last_number] soup = BeautifulSoup(content, "html.parser") chapter = soup.find(name=‘div‘, class_="bookname").h1.text content = soup.find(name="div", id="content").text save(base_url, chapter, content) # 如果存在下一个章节的链接,则将链接加入队列 next1 = soup.find(name=‘div‘, class_="bottem").find_all(‘a‘)[3].get(‘href‘) if next1 != base_url: q.put(next1) # print(next1) return q def save(base_url, chapter, content): book_name = get_book_name(base_url) filename = book_name + ".txt" f = open(filename, "a+", encoding="utf-8") f.write("".join(chapter) + " ") f.write("".join(content.split()[2:]) + " ") f.close() # 获取书名 def get_book_name(base_url): content = get_content(base_url) soup = BeautifulSoup(content, "html.parser") name = soup.find(name=‘div‘, class_="box_con").h1.text return name def main(): first_url = input("请输入小说第一章的链接:") start_time = time.time() # 进入主页 # https://www.52bqg.com/ # 随便搜索一步小说,找出变化规律 # https://www.52bqg.com/book_110102/ q = queue.Queue() # 小说第一章链接 # first_url = "https://www.52bqg.com/book_110102/35620490.html" q.put(first_url) while not q.empty(): content = get_content(q.get()) q = parseContent(q, first_url, content) end_time = time.time() project_time = end_time - start_time print("下载用时:", project_time) if __name__ == ‘__main__‘: main()
欢迎大家分享一些新发现。
以上是关于bs4爬取笔趣阁小说的主要内容,如果未能解决你的问题,请参考以下文章