分析函数实验学习
Posted nadian-li
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分析函数实验学习相关的知识,希望对你有一定的参考价值。
第一章 概述
分析函数是oracle816引入的一个全新的概念,为我们分析数据提供了一种简单高效的处理方式.在分析函数出现以前,我们必须使用自联查询,子查询或者内联视图,甚至复杂的存储过程实现的语句,现在只要一条简单的sql语句就可以实现了,而且在执行效率方面也有相当大的提高.
此文档用一些例子记录自己的学习过程。
第二章 分析函数窗口研究
2.1窗口概述
ROWS/RANGE:窗口子句,是在分组(PARTITION BY)后,组内的子分组(也称窗口),此时分析函数的计算范围窗口,而不是PARTITON。窗口有两种,ROWS和RANGE;
ROWS/RANGE窗口的计算, 必须在分析函数中指定ORDER BY子句。
行比较分析函数lead和lag无window(窗口)子句
2.2rows的使用
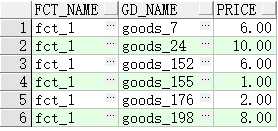
使用的数据 ID为1的工厂所有的产品和价格
select f.fct_name, g.gd_name, g.price
from lw_factory f, lw_rel_fct_gd r, lw_goods g
where f.fct_id = 1
and f.fct_id = r.fct_id
and
r.gd_id = g.gd_id;
例:
with t as
(select
f.fct_name, g.gd_name, g.price
from lw_factory f, lw_rel_fct_gd r, lw_goods g
where f.fct_id =1
and f.fct_id = r.fct_id
and r.gd_id = g.gd_id)
select t.*,
SUM(price) over(ORDER BY price ROWS BETWEEN unbounded preceding AND CURRENT ROW) rows_unbound_sum,
SUM(price) over(ORDER BY price ROWS BETWEEN 1 preceding AND 2 following)
rows_sum
from t;
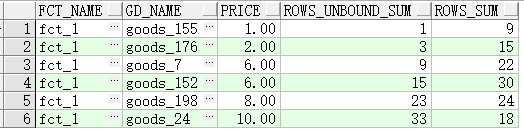
l rows是物理窗口,即根据order by 子句排序后,取的前N行及后N行的数据计算(与当前行的值无关,只与排序后的行号相关)
ROWS BETWEEN unbounded preceding AND CURRENT ROW 代表取当前行和之前所有行:
当price=1时rows_unbound_sum=1
当price=8时 rows_unbound_sum取值范围为1,2,6,6,8 sum(price)=1+2+6+6+8=23
ROWS BETWEEN 1 preceding AND 2 following是取前1行和后2行数据的求和,分析上例rows_sum的结果:
2.3range的使用
例:
with t as
(select
f.fct_name, g.gd_name, g.price
from lw_factory f, lw_rel_fct_gd r, lw_goods g
where f.fct_id =1
and f.fct_id = r.fct_id
and r.gd_id = g.gd_id)
select t.*,
SUM(price) over(ORDER BY price) default_sum,
SUM(price) over(ORDER BY price RANGE BETWEEN unbounded preceding AND CURRENT ROW)
range_unbound_sum,
SUM(price) over(ORDER BY price RANGE BETWEEN 1 preceding AND 2 following)
range_sum
from t;
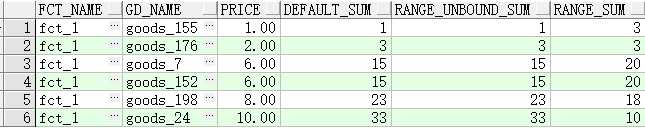
l range是逻辑窗口,是指定当前行对应值的范围取值,列数不固定,只要行值在范围内,对应列都包含在内。
l 官方文档部分介绍
if
you omit the windowing clause of the analytic clause,
itdefaults to RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW. This default sometimes returns an unexpected
value, because the last value in the window is at the bottom of the window,
which is not fixed. It keeps changing as the current row changes. For expected
results, specify the windowing_clause as RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING. Alternatively, you can specify the windowing_clause as RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING.
l 窗口子句必须和order by 子句同时使用,且如果指定了order
by 子句未指定窗口子句,则默认为RANGE
BETWEEN unbounded preceding AND CURRENT ROW,如上例结果集中的defult_sum等于range_unbound_sum;
当price=1时 price的取值范围为 1 和它之前的所有行 1
当price=6时 price的取值范围为1,2,6符合条件的行有 1,2,6,6 sum(price)就是1+2+6+6=15
l 上例中range_sum(即range 1 preceing
and 2 following)例的分析结果:
当price=1时 price取值范围就是 1-1<=ID<=1+2 (0,1,2,3) 符合条件的值有1,21+2=3
当price=8时 price取值范围就是 8-1<=ID<=8+2(7,8,9,10) 符合条件的值有 8,10 8+10=18
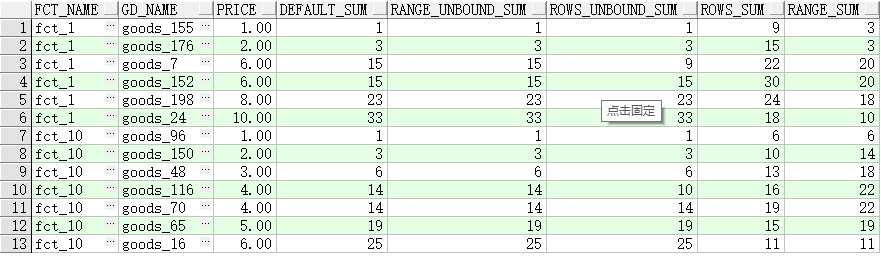
2.4partition by子句的研究
取工厂id为1和10的工厂计算他们的产品价格,partition
by 先按工厂名进行分组再执行计算,需要注意的是,后边的窗口函数是在partition by分完组后再每个分组中进行范围限定;
with t as
(select
f.fct_name, g.gd_name,
g.price
from
lw_factory f, lw_rel_fct_gd r,
lw_goods g
where
f.fct_id in(1,10) and
f.fct_id =
r.fct_id
and
r.gd_id = g.gd_id)
select t.*,
SUM(price) over(partition by
fct_name ORDER BY
price) default_sum,
SUM(price) over(partition by
fct_name ORDER BY
price RANGE BETWEEN unbounded preceding AND CURRENT ROW)
range_unbound_sum,
SUM(price) over(partition by
fct_name ORDER BY
price ROWS BETWEEN unbounded preceding AND CURRENT ROW)
rows_unbound_sum,
SUM(price) over(partition by
fct_name ORDER BY
price ROWS BETWEEN 1 preceding AND 2 following)
rows_sum,
SUM(price) over(partition by
fct_name ORDER BY
price RANGE BETWEEN 1 preceding AND 2 following)
range_sum
from t;
第三章 分析函数
3.1分析函数类别
3.1.1汇总类
count() over(partition by ... order by ...)
max() over(partition by ... order by ...)
min() over(partition by ... order by ...)
sum() over(partition by ... order by ...)
avg() over(partition by ... order by ...)
ratio_to_report() over(partition by...order by...)---求百分比
使用:
使用的数据为上次作业已经造好的数据
with t as (select
f.fct_name,
g.gd_name,
count(*) over(partition by f.fct_name)
as "工厂产品总数",
max(g.price) over(partition by
f.fct_name) as "工厂产品最高的价格RMB",
min(g.price) over(partition by
f.fct_name) as "工厂产品最低的价格RMB",
sum(g.price) over(partition by
f.fct_name order by g.price desc ) as "工厂产品价格之和RMB",
round(avg(g.price) over(partition by
f.fct_name order by g.price desc), 1) as "工厂产品平均价格RMB",
round(ratio_to_report(g.price)
over(partition by f.fct_name) * 100, 2) || ‘%‘ as "此产品价格在所有产品中的占比"
from lw_factory f, lw_rel_fct_gd r, lw_goods g
where f.fct_id = r.fct_id
and r.gd_id = g.gd_id)
select * from t where rownum<11;
输出结果:

3.1.2排行类
row_number()
over(partition by ... order by ...) 等同于rownum;在分析函数中使用
rank()
over(partition by ... order by ...) 跳跃排序
dense_rank()
over(partition by ... order by ...) 连续排序
说明:over()在什么条件之上;
partition by 按哪个字段划分组;
order by 按哪个字段排序;
注意:
(1)使用rank()/dense_rank() 时,必须要带order by否则非法
(2)rank()/dense_rank()分级的区别:
rank(): 跳跃排序,如果有两个第一级时,接下来就是第三级。
dense_rank(): 连续排序,如果有两个第一级时,接下来仍然是第二级。
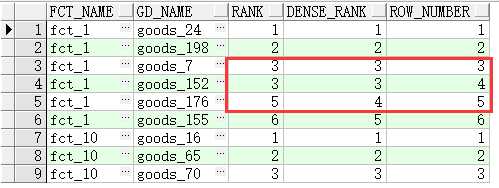
示例:查询每个工厂产品价格排序,从高到低;
select * from (select
f.fct_name,
g.gd_name,
rank() over(partition by f.fct_name order by g.price desc) rank,
dense_rank() over(partition by
f.fct_name order by g.price desc)dense_rank,
row_number() over(partition by f.fct_name
order by g.price
desc) row_number
from lw_factory f, lw_rel_fct_gd r, lw_goods g
where f.fct_id = r.fct_id
and r.gd_id = g.gd_id)
where rownum<10;
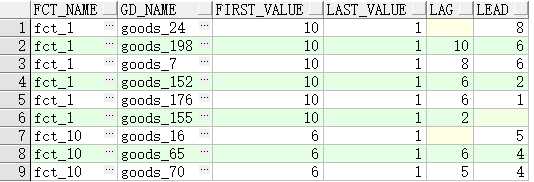
3.1.3相邻类
first_value()
over(partition by ... order by ...) 取分区后首行记录
last_value()
over(partition by ... order by ...) 取分区后尾行记录
lag()
over(partition by ... order by ...) 取本条记录前记录
lead()
over(partition by ... order by ...)取本条记录后的记录
测试:
select *
from (select f.fct_name,
g.gd_name,
first_value(g.price) over(partition by f.fct_name order by g.price desc) first_value,
last_value(g.price) over(partition
by f.fct_name) last_value, ---排序不起作用
lag(g.price) over(partition by f.fct_name order by g.price desc) lag,
lead(g.price) over(partition by f.fct_name order by g.price desc) lead
from lw_factory f, lw_rel_fct_gd r, lw_goods g
where f.fct_id = r.fct_id
and r.gd_id = g.gd_id)
where rownum < 10;
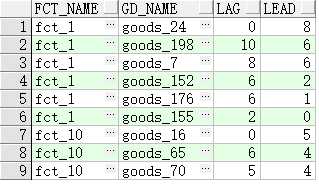
注意:
lead(列名,n,m): 当前记录后面第n行记录的<列名>的值,没有则默认值为m;如果不带参数n,m,则查找当前记录后面第一行的记录<列名>的值,没有则默认值为null。
lag(列名,n,m): 当前记录前面第n行记录的<列名>的值,没有则默认值为m;如果不带参数n,m,则查找当前记录前面第一行的记录<列名>的值,没有则默认值为null。
示例:
select *
from (select
f.fct_name,
g.gd_name,
lag(g.price,1,0) over(partition by f.fct_name order by g.price desc) lag,
lead(g.price,1,0) over(partition by f.fct_name order by g.price desc) lead
from
lw_factory f, lw_rel_fct_gd r, lw_goods g
where
f.fct_id = r.fct_id
and r.gd_id
= g.gd_id)
where rownum < 10;
第四章 小结(分析函数的作用)
分析函数是Oracle专门用于解决复杂报表统计需求的功能强大的函数,它可以在数据中进行分组然后计算基于组的某种统计值,并且每一组的每一行都可以返回一个统计值。
普通的聚集函数不能满足这样的统计:
①查找上一年度各个销售区域排名前10的员工
②按区域查找上一年度订单总额占区域订单总额20%以上的客户
③查找上一年度销售最差的部门所在的区域
④查找上一年度销售最好和最差的产品
以上是关于分析函数实验学习的主要内容,如果未能解决你的问题,请参考以下文章