巨杉Tech | 分布式数据库负载管理WLM实践
Posted sequoiadbsql
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了巨杉Tech | 分布式数据库负载管理WLM实践相关的知识,希望对你有一定的参考价值。
1前言
分布式数据库已经成为许多金融级大型企业基础数据平台的一个核心组成部分,承担着,在线交易,数据中台,历史数据管理,非结构化影像平台等多个重要业务的支撑工作。
不同于传统的应用/数据库一对一的部署方式,新一代数据平台使用一个统一的存储,对接着上层几十甚至上百个不同的应用,这种情况下,不同应用之间对于资源的调度会成为系统是否能够正常对外提供服务的重要因素。但是在像数据中台、历史数据平台这类应用中,对外提供服务的应用与对内进行分析的应用明显不应该使用相同的优先级。因此,在数据库集群中,引入一个完善的资源管理调度系统至关重要。
我们根据资源管理调度,整理了一套分布式数据库的资源负载管理的技术方案。由于企业场景中,数据平台除了分布式数据库以外还存在其他组件和模块,该资源管理调度系统可以在今后被扩展到大数据平台的多种模块,为除了巨杉数据库之外的其他模块和组件提供统一的企业级资源管理调度平台。本文就将介绍分布式数据库集群如何实现资源管理调度功能。
2设计原理和功能说明
管理对象分类
巨杉集群资源管理平台具有对被监控模块当前资源使用情况的总览、细化;定义任务组群、组群优先级、任务优先级、任务列表浏览;以及对不同任务组群、单个任务优先级的在线调节功能。
主要涉及到的管理对象分为三类:
1)资源管理
该类对象主要以监控和分配为主。系统中的资源分为CPU、IO、内存以及网络四大部分,每部分可以被分为总体、任务、业务、集群和节点几个级别。监控功能可以对每类资源的每个级别进行全局或精细化监控,实时得到当前系统的资源消耗情况。
2)任务管理
任务是对系统所执行业务的一种逻辑概括,描述一类相近的业务类型。属于同一个任务的所有业务和数据库会话均使用公平调度原则,同时所消耗资源将会被累计入该任务的总体消耗。
多种任务可以被归纳为任务组,每一个任务组可以包含多个任务与子任务组。
另一方面,任务需要与每个数据库连接一一对应。每一个数据库连接应当仅属于一个任务。任务定义可以使用用户名、连接源IP地址段等特征进行区分。
系统使用“优先级”概念对每个任务进行控制。一个高优先级的任务在同等情况下,应当优先于低优先级的任务执行。每个任务的“优先级”可以被精确指定,或者使用动态浮动的方式被系统自动调节。
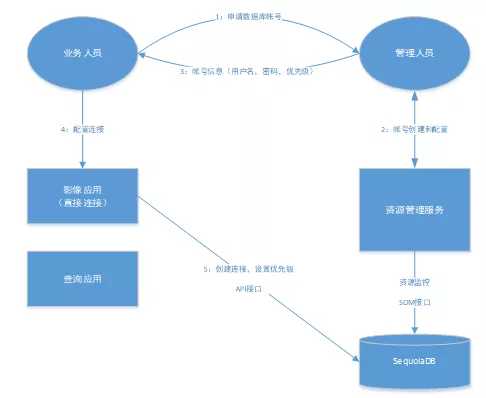
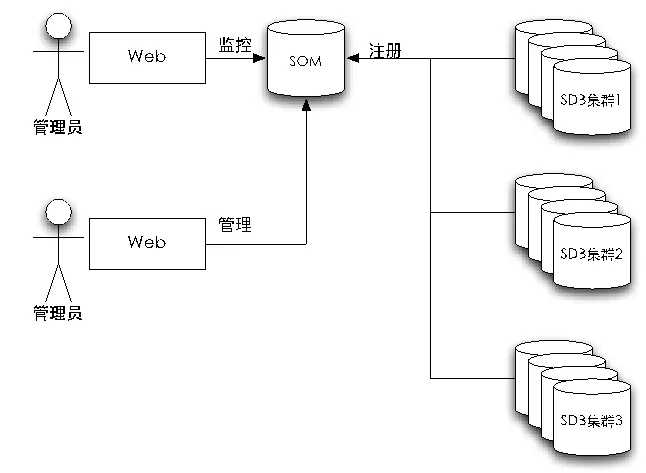
譬如影像业务直接连接巨杉数据库,需要资源管理平台提供影像业务的任务资源使用情况,影像业务的任务流程如下图所示。
3)应用管理从应用层的角度看,每一个应用直接与SequoiaSQL或协调节点通讯,执行SQL或API。SequoiaDB会引入虚拟集合的概念,将每个会话的当前任务属性作为一个虚拟表映射进SequoiaSQL表。应用程序可以通过UPDATE该虚拟表的任务ID字段,指定该连接所属于的任务。之后所有的查询、插入、更新和删除命令都会沿用该任务ID以及其优先权。
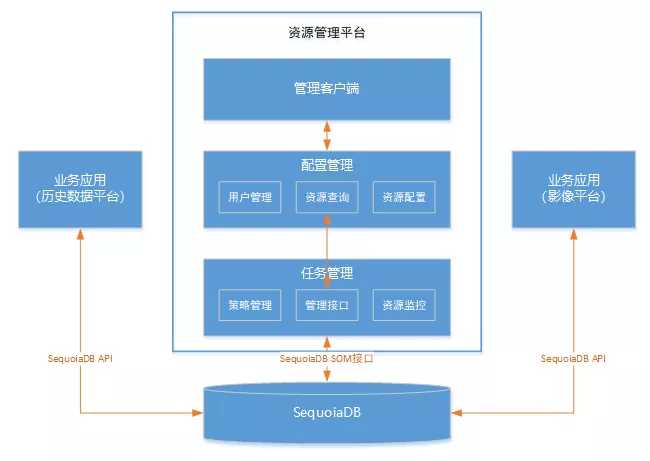
总体架构
巨杉集群资源管理平台分为三大部分,包括数据库层、任务管理层以及配置管理层。
其中数据库层为巨杉数据库的执行引擎,能够根据上层配置的业务优先级进行动态调整,保证高优先级的任务优于低优先级的任务执行。
任务管理层则是该系统的核心,保存着任务组、任务、与各种优先级规则配置的定义,以及实时监控系统以动态调整各个业务的优先级。
配置管理层则是展现界面,负责将系统中各个任务组与子任务的资源消耗情况、与用户配置的任务组依赖关系、外加任务/连接的映射关系有效地展示出来。
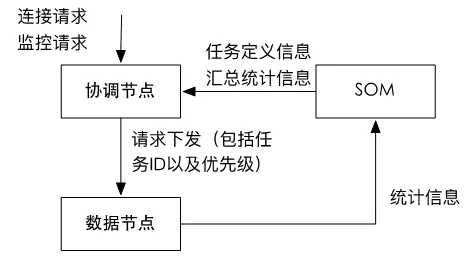
数据库层
数据库层是资源管理平台的执行部分,在这个项目中主要包含三个角色:协调节点、SAC与数据节点。
协调节点负责直接从历史数据平台应用接收连接与请求,并得到其任务ID与优先级,并将该请求转发至相应的数据节点执行。
数据节点负责执行任务并收集统计信息。每个任务的优先级与任务ID会由协调节点指定,数据节点按照优先级执行任务,并按照任务ID进行汇总其性能监控信息。
SAC负责策略管理调配以及性能数据汇总聚集。
1)协调节点协调节点作为应用程序连接的接收方,自身不存储任何数据。当应用程序请求到达时,首先协调节点会判断请求类型。如果该请求是查询任务定义信息的,则会和SAC通讯,将任务定义信息返回给查询者。如果请求是定义任务ID的,则会在内部将该会话标示相关的任务ID,并在接下来的用户任务中使用该任务ID以及相应的优先级。如果在缓存中找不到相应的任务以及优先级,则会再次与OM通讯请求相关信息,如果请求不成功则会返回错误。如果请求内容是用户查询,同时该会话已经配置了任务ID以及优先级,则将该内容作为请求的一部分下发给对应的数据节点。
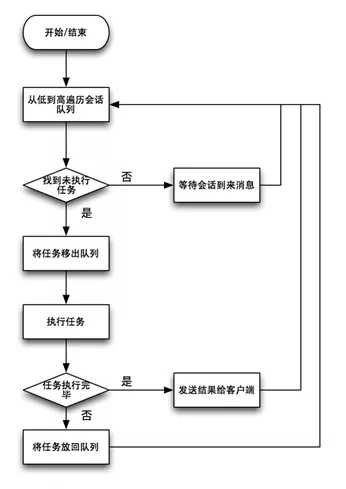
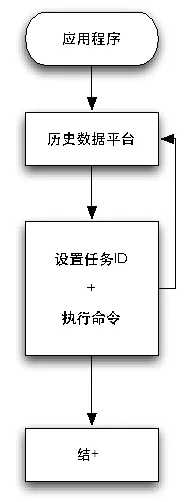
2)数据节点巨杉数据库内部每个会话(Session)均对应一个独立的应用程序连接。而每个连接则对应着各自的优先级。数据库节点内部维持一个优先级列表,从-20至19,总共40个级别。数字越大表示会话的优先级越低。默认情况下会话的的优先级为0。当应用程序连接到数据库后,可以通过API手工设置该会话的属性(setSessionAttribute)以改变当前会话的优先级。在数据库内部则会维持S2ZWz40个会话队列,每个Session按照当前的优先级存在于特定的队列中。当存在一个Agent代理线程准备执行下一个任务时,则会优先选择高优先权(数字低)队列中的等待任务。如果一个队列为空,则会尝试选择下一个优先权的队列,直到遍历完成或找到一个等待执行的任务。这种机制能够保证:
-
在系统空闲时,低优先权的任务能够得到足够多的资源执行,使得性能不产生任何下降。
-
在系统繁忙时,只有高优先权的任务完成自己的当前查询后,才能够轮到低优先权的任务执行,保证高优先权任务最先执行完毕。
任务优先级调度控制,如下图所示。
3)SAC
SAC是SDB运维管理模块。SAC对外提供REST接口,应用程序通过发收HTTP请求,从SAC节点获得当前注册进SAC的全部集群信息。
SAC中包含任务与任务组的定义,以及对数据节点性能信息定期收集的汇总结果。
当监控界面需要查询任务定义以及性能信息时,可以直接与SAC界面通讯得到最新的数据。
SAC则定期与底层的数据节点通讯得到每个数据节点的性能信息。
任务管理
任务管理分为两大部分:资源监控和策略管理。
1)资源监控
在资源监控中,整个系统的全部资源被分为几个级别:
1)整体:代表整个系统的全部资源的累加
2)任务:根据每个任务组以及子任务划分
3)集群:显示每个数据库集群所占用资源
4)节点:显示每个逻辑节点资源使用情况
整个系统的监控信息从SAC节点获得,SAC节点是SDB图形化展现方式的统一连接出口,承担着在线部署、全局监控、历史信息收集等运维相关工作。SAC对外提供REST接口,应用程序通过发收HTTP请求,可以从SAC节点获得当前注册进SAC的全部集群信息。
每一级别的监控分别监控给定级别的CPU、内存、磁盘、网络、以及数据库,具体包括:
-
CPU:User CPU、Sys CPU、Wait CPU、Idle CPU
-
内存:总内存、已用内存、Cached内存、交换空间、SwapIn、SwapOut
-
磁盘:总磁盘空间、空闲磁盘空间
-
网络:NetIn、NetOut
-
数据库:当前连接数、占用内存、占用磁盘、逻辑物理数据读写、逻辑物理索引读写、逻辑物理LOB读写
这些信息可以提供给监控者一个比较明确的视图,实时监控当前系统的运行状况。
在协调节点端,性能视图会被做成“虚拟集合”的形式,也就是对外访问的方式和使用普通集合一样,做一个查询即可。但是内部,该虚拟集合会被映射到系统中的快照信息。
而对于历史会话性能数据的收集,会将中断后的会话快照作为一个只读记录存储一个历史虚拟集合的表中,由SAC查询后归档并删除。SAC将每个数据节点中当前性能视图与历史性能视图定期收集并进行聚集,形成一个整体的性能视图表。
Web界面则直接从SAC查询,得到系统整体的性能信息。
2)策略管理
该管理平台中最基本的策略调度单元为“任务”。每个任务代表一类特性相同的数据库会话。每一个独立的数据库会话属于一个且仅一个任务。一个无法被分类的会话属于“默认任务组”中的“默认任务”。
任务可以通过会话来源的IP地址与登录用户名进行区分,用户也可以手工指定当前会话的任务ID。例如说来自192.168.0.1至192.168.0.100,且用户名为“Sam”(大小写敏感)的用户属于“任务A”。
用户也可以通过连接到协调节点或SQL引擎,通过API或SQL指定当前连接的任务ID。
一个或多个任务可以被汇总为一个任务组。用户可以针对每个任务定义其优先级,也可以直接在任务组定义优先级并指定覆盖所有包含任务的优先级。
一个任务的默认优先级为0,在不指定的情况下不会向该任务所对应的连接发送setSessionAttribute指令。
每个协调节点会缓存任务定义列表,因此如果一个会话的任务ID被动态更改,其更改任务ID后所执行的所有操作均会使用新的任务ID所对应的优先权。
SAC中优先权的变更会被通知给所有注册的协调节点(启动时配置了OM参数)
注意,策略管理模块通过调整每个任务的优先级控制该任务相对其他任务的优先程度,并不能手工限定某一种业务最多使用若干给定资源。例如,优先级机制无法保证任务A永远不会使用超过30%的CPU,但是可以保证更高优先级的任务B存在请求时永远优先执行任务B的请求。
配置管理
配置管理层指的是本系统的对外展现层,分为监控与策略定义两大部分。
监控部分分为两个维度,包括监控的内容与监控的层面。
监控的层面需要与任务管理系统中提供的层面相比配,包括:
-
整体:代表整个系统的全部资源的累加
-
任务:根据每个任务组以及子任务划分
-
集群:显示每个数据库集群所占用资源
-
节点:显示每个逻辑节点资源使用情况
其中,任务可以分为任务组,或细化到其中的具体任务。集群也分为集群与节点两层。
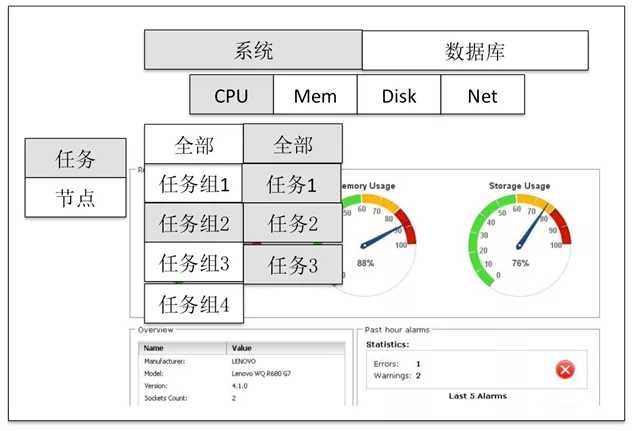
而策略定于部分则是对于任务与任务组的定义,以及指定每个任务与任务组各自的优先级。
在配置管理页面可以配置任务的优先级信息。在配置优先级时,首先需要添加一个任务,然后再在任务下配置策略规则。
1)任务配置
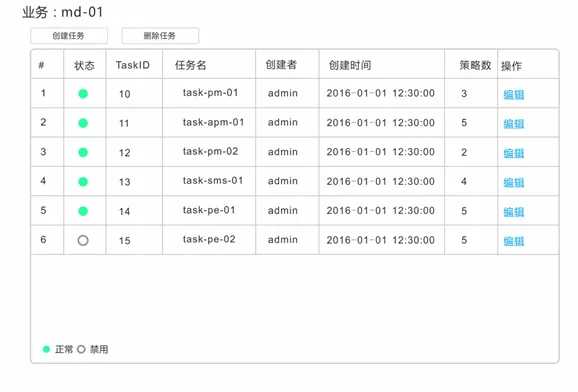
在任务配置页面,可以查看到当前系统中已经配置的任务的详细信息,其中状态字段表示该任务的配置是否生效。
通过该页面,还可新增或删除任务配置。点击编辑将打开指定任务的策略规则配置页面(见下节)。
2)策略规则配置
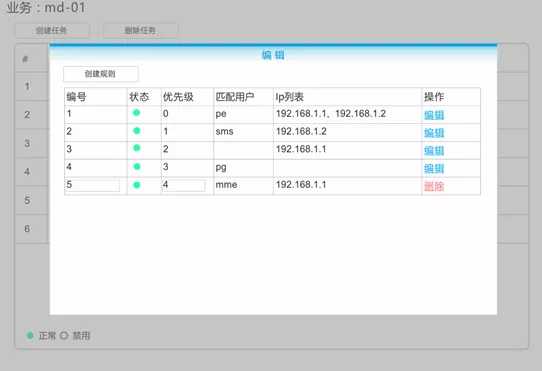
在策略规则配置页面,可以看到特定任务的策略配置信息。这些策略配置信息将按照生效顺序进行排列,排在前面的规则将优先生效。也就是说,当某个查询任务同时匹配到多条策略规则时,将优先选择排在前面的策略规则。为了降低新增配置对当前系统运行带来的影响,新增的策略规则默认放在最后生效。用户可以通过调整编号来修改策略的生效顺序。同时也可以通过修改状态来使某条策略规则暂时失效。
系统运行时序
系统运行时序完全由数据库根据每个会话的优先权决定。
每个数据节点可以配置使用若干个代理线程(Agent)作为会话的执行载体。当数据库压力繁忙时,并发执行的请求可能会远高于系统分配的代理线程数量。这种情况下,当代理线程的数量无法做到一对一满足会话的时候,会将无法执行的会话放入backlog等待队列。
等待队列分为40个子队列,每个子队列编号分别为0至39,编号越小意味着优先权越高。当代理线程执行完当前任务后,会从前向后遍历等待队列,找到下一个等待执行的任务。因此,任何高优先权的等待任务会优先于低优先权的任务执行。
当一个会话执行到中途返回时(例如表扫描扫完一个数据块,需要将部分结果集发送给客户端),则会将未执行完的会话重新放入相应优先级别的等待队列末尾,直到数据库得到下一个GetMore请求扫描下一个数据块。
针对后台任务,所有的后台任务都被设置为低优先级,在同等条件下不会与交互式任务竞争资源。
当代理线程数量大于当前会话数量时,每一个会话能够实时分配到一个代理线程,所有的任务则并发执行,不存在相互的优先关系。
关键技术
SAC对于数据库来说,仅相当与一个外部应用。数据库不主动向SAC发送数据,所有的监控数据以及优先级调整请求,都是从SAC直接向数据库发送。
SAC会根据配置,定时向所注册的数据库集群中请求快照信息,包括系统快照、数据库快照、会话快照等内容,并存入本地历史归档集合。
应用程序向SAC的监控信息请求,会被直接发送给归档集合,从性能归档集合中读取相应的信息发送给前端的应用。
同时,SAC会根据自身存放的策略信息,每次用户对当前会话设置完任务ID后,协调节点将会在其后所有的操作指定该任务所对应的优先权。该优先权信息会被下发到底层的数据节点执行,同时统计信息会被汇总到每个任务ID下,由OM定期收集。
其他注意事项
1)性能分析
正常情况下,本方案不会产生任何性能下降。当数据节点代理线程数量设置合理时,正常情况下应当小于并发执行的会话数量。这时所有的会话均可以在第一时间找到空闲的代理线程,因此可以像原先的做法一样进行并行执行。
当会话数量大于代理线程数量时,如果所有会话均使用同一优先级,性能与当前实现基本相同,也不会产生性能下降。
当会话数量大于代理线程数量时,如果会话的优先级设置不同,那么高优先级的会话在执行完片段后会被立刻放回高优先级队列等待下次执行,其优先级永远高于其他低优先级的会话,因此对于高优先级的任务会提升性能,同时低优先级的任务会下降性能。
2)安全设计
本系统由于只与SAC系统连接,SAC与数据库的通讯同样需要对用户名密码进行鉴权,因此只有拥有数据库访问权限的用户名密码,才能够与SAC进行通讯并得到数据库的监控信息。
3)接口设计
- 策略配置
策略配置信息保存在SAC中,通过对SAC提供的接口进行读取及修改策略配置。SAC提供以下两种操作接口:
-
pgsql
将SAC中的策略配置集合映射成PG的外表,提供pgsql查询接口
-
rest
通过rest接口的命令操作,对策略配置信息进行修改及读取任务优先级配置信息包括以下字段:
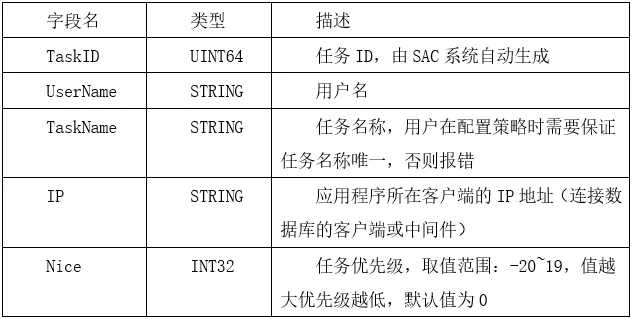
-
会话设置
设置当前会话的TaskID,系统将根据该TaskID设置当前会话的优先级以及生成统计信息。
应用程序通过使用pgsql接口,对虚表$SYS_CUR_TASK_ID进行update({$set:{TaskName:"task1"}})操作来实现设置当前会话的TaskID。
-
资源监控
资源监控信息保存在SAC中,可通过以下方案获取:
方案一:
将资源监控信息集合映射成PG的外表,通过pgsql进行查询。
方案二:
通过SAC的rest接口进行查询。考虑统计信息记录会比较多,信息无法一次性返回。rest接口需要提供query+getmore的方式获取统计信息。
统计信息包含以下字段内容:
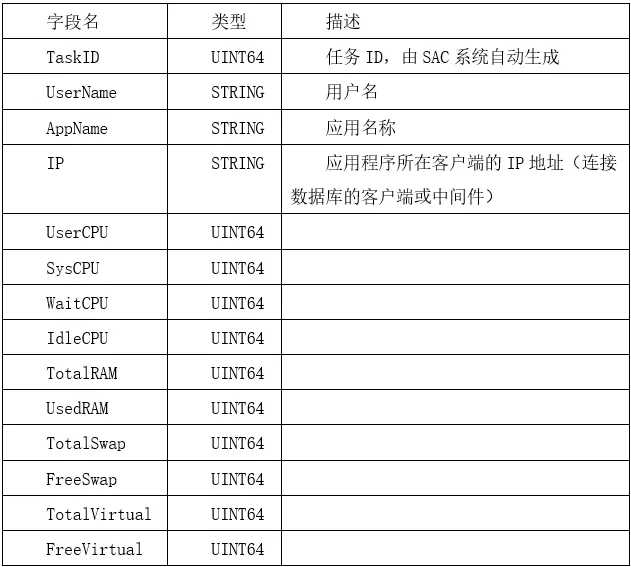
以下字段信息无法在会话中提供:
内存:Cached内存、交换空间、SwapIn、SwapOut
磁盘:总磁盘空间、空闲磁盘空间
网络:NetIn、NetOut
数据库:当前连接数、占用内存、占用磁盘、逻辑物理数据读写、逻辑物理索引读写、逻辑物理LOB读写
3实践步骤
本章介绍SequoiaDB如何通过SAC实现资源监控和资源调度功能。
通过SAC实现资源监控
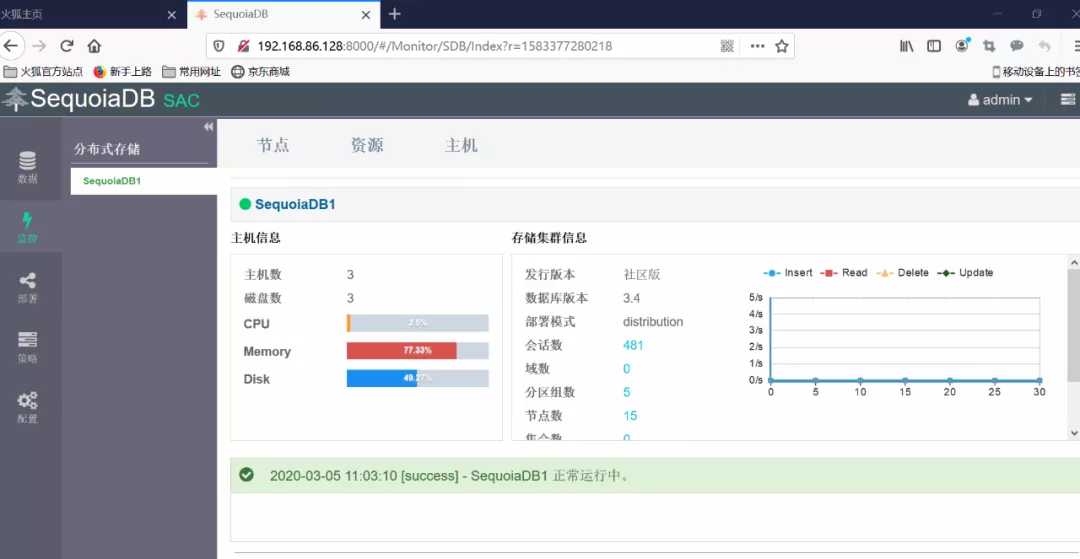
在装有SAC服务的机器上登录,用户名和密码都是admin http://地址:8000点击左侧的监控>分布式存储下面的SequoiaDB1,能看到主机信息,和存储集群总体信息,包括主机数量,磁盘数量,数据库版本,会话数,分区组数等内容。
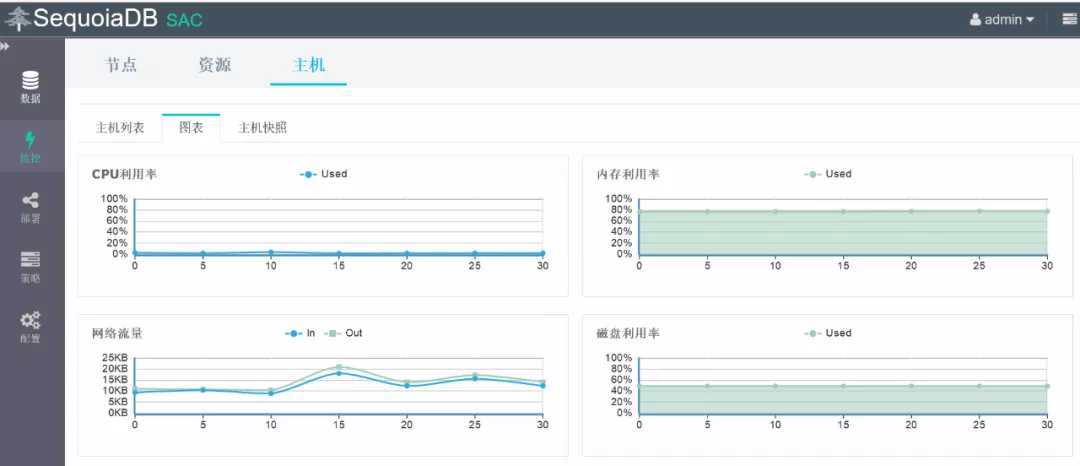
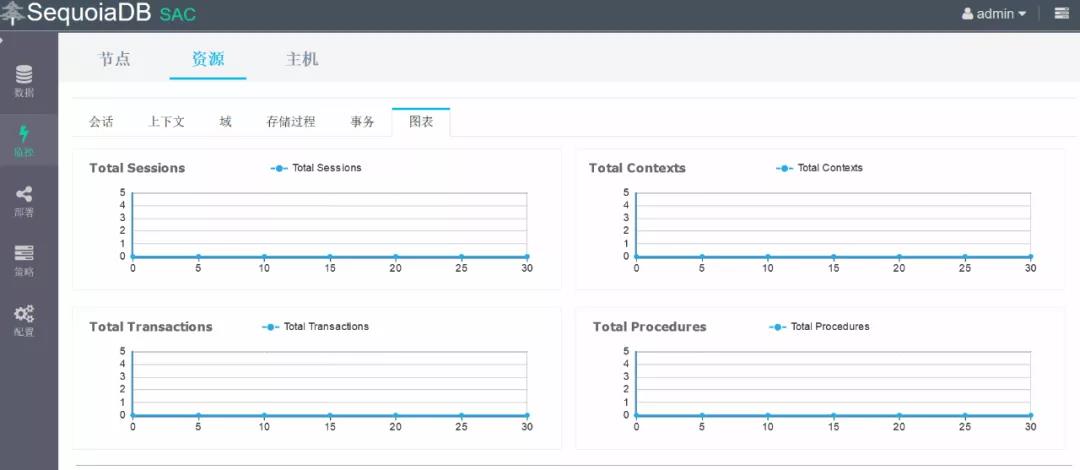
通过SAC实现资源调度
在装有SAC服务的机器上登录,用户名和密码都是adminhttp://地址:8000点击左侧的监控>分布式存储下面的SequoiaDB1
点击添加任务,添加两个任务task1和task2。

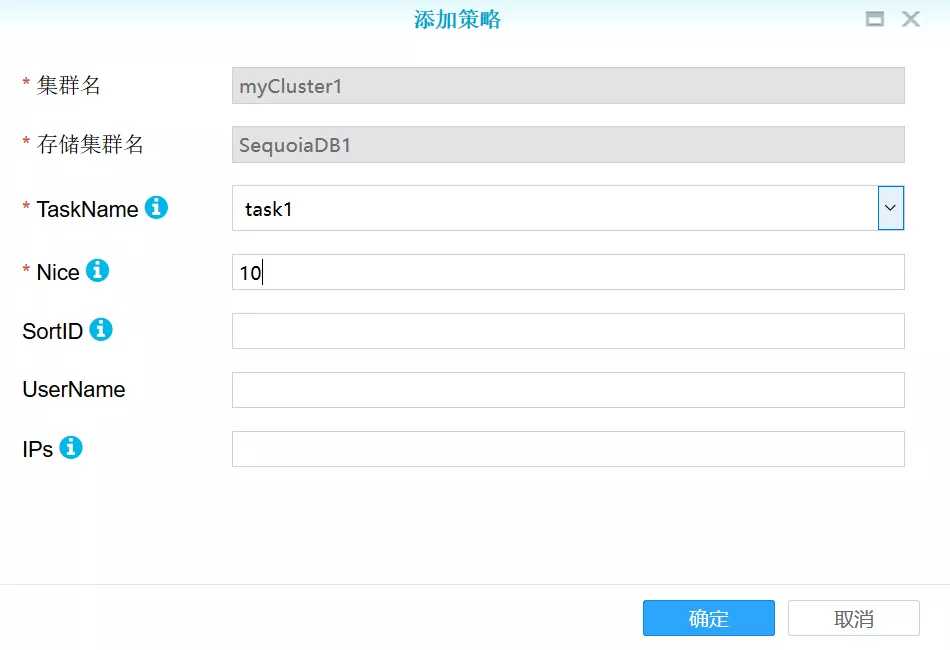
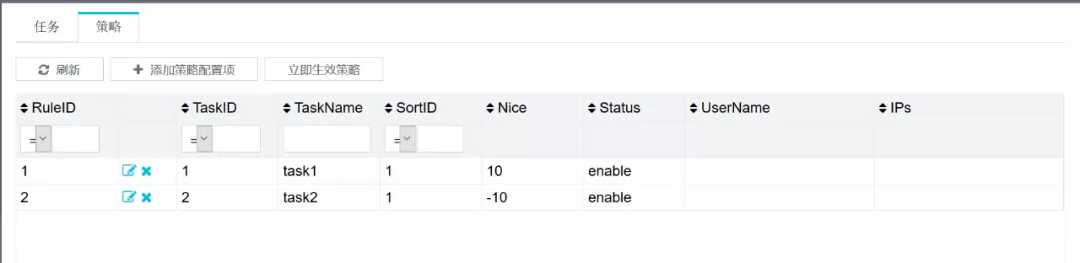
假设要使XXX系统能够使用上述策略配置规则,先创建database和foreign table,执行下面的命令:
/opt/sequoiasql/postgresql/bin/sdb_sql_ctl createdb CS_CMBC_STAT_XXX PostgreSQLInstance1/opt/sequoiasql/postgresql/bin//psql -p 5432 CS_CMBC_STAT_XXX

create extension sdb_fdw ;create server sdb_server foreign data wrapper sdb_fdw options(address ‘192.168.86.128:11810, 192.168.86.129:11810,192.168.86.130:11810‘, service ‘11810‘);create foreign table "CL_TASK_ATTR"("TaskName" text, "User" text, "IP" text) server sdb_server options(collectionspace ‘$SYS_VCS‘, collection ‘SYS_SESSION_INFO‘);

执行更新语句,将当前会话与之前设置的task1对应:
update "CL_TASK_ATTR" set "TaskName"=‘test1‘; 
在当前连接下执行SQL语句,只要会话不退出,所有在当前连接下的SQL语句都能使用task1的策略。
4小结
WLM负载管理是分布式数据库集群管理中非常重要的能力之一,文章从实践出发,总结了巨杉数据库作为分布式数据库,在数据库资源管理和负载管理方面的基础实践,希望对大家在应用分布式数据库、分布式架构时,遇到资源管理的问题也能迅速解决。
以上是关于巨杉Tech | 分布式数据库负载管理WLM实践的主要内容,如果未能解决你的问题,请参考以下文章
巨杉 Tech | SequoiaDB SQL实例高可用负载均衡实践
巨杉数据库SequoiaDB巨杉 Tech | SequoiaDB SQL实例高可用负载均衡实践
巨杉数据库SequoiaDB巨杉Tech | 分布式数据库Sysbench测试最佳实践