JDK1.8 HashMap
Posted mougg
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JDK1.8 HashMap相关的知识,希望对你有一定的参考价值。
背景
HashMap 是集合框架中最重要的类之一:
- LinkedHashMap 直接继承 HashMap
- ConcurrentHashMap 的实现就是 HashMap + 分段锁
- HashSet 底层是 HashMap
- TreeMap 的红黑树在 HashMap 也有实现
JDK1.8 java.util.HashMap#table 注释说 "length is always a power of two",为什么?
哈希冲突(Hash Collision)
哈希表解决冲突的方式有两种:
- 开放地址法(open addressing),一个萝卜一个坑,没坑了就扩容。
- 链地址法(chaining)
Java 中的实现是链地址法,底层是 数组、链表、红黑树。这个数组其实就是算法常用的 hash table,定义如下:
transient Node<K,V>[] table;
这个 Node 就是链表,在长度超过8的时候会转换为 TreeNode。
注意下,Node 会在第一次计算元素 hash 值后,把 hash 记录下来,扩容时可以复用。
是 mask,不是 mod
在看 java.util.HashMap#put 源码之前,我以为会用 mod 计算元素在 table 中的索引:
i = hash % n
// hash:通过 hash() 计算出来的哈希值
// n:table.length
然而实际情况是 i = (n-1) & hash,网上很多说法这是用二进制实现的高性能取余。究竟是不是,试一下就知道:
int[] ns = new int[]{16, 15};
for (int n : ns) {
System.out.println("----" + n + "----");
System.out.println(100 % n);
System.out.println(100 & n - 1);
}

结论很明显,这不是一般的取余,而是当 n 为 power of 2 恰好表现为取余。
联想一下子网掩码的工作原理,答案就出来了:这是把 n - 1 作为一个 mask 来计算索引。
为什么恰好是 n - 1 呢,可以看一个案例:
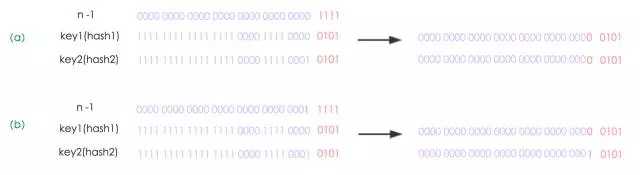
(a) 是 resize 之前的情况,key1 的索引是 0101,key2 的坐标是 0101,很好,这俩属于同一个 bucket;
(b) 是 resize 之后的情况,由于 "length is always a power of two",n - 1 扩容后只需要简单左移1位,这会儿 mask 一下你会发现,扩容后 key1 的新坐标是 0101,key2 的新坐标是 1101,它们只是新增了一个最高位。
上文我们提到,Node 会把 hash 记录下来,现在扩容,只需看看hash值中对应 mask 最高位:0则索引不变,1则 新索引 = 原索引 + oldCap。
java.util.HashMap#hash 也很讲究
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
Java 的 hashCode 是一个int类型,占用4字节,即32位,分为高16位,低16位。
计算索引的公式是 (n - 1) & hash,当 table 还没扩容时,n - 1 很小,& 只能对低位有效果。
为了保证 hashcode 的高低位都能参与到索引计算中,hash() 将 hashCode 高16位 和 低16位 做异或运算,同时控制了开销。
结论
(n - 1) & hash不是为了高性能取余,而是对 hash 做 mask 计算索引- resize 不需要 rehash,所以性能上来了
Reference
[1]Java8系列之重新认识HashMap
[2]散列表-哈希冲突
以上是关于JDK1.8 HashMap的主要内容,如果未能解决你的问题,请参考以下文章