kaggle比赛实践M5-数据集介绍
Posted wqbin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kaggle比赛实践M5-数据集介绍相关的知识,希望对你有一定的参考价值。
M5比赛
M5竞赛是M竞赛中最新的一次,将于2020年3月2日至6月30日举行。它与前四届竞赛有五个重要方面的差异,其中一些是M4竞赛的讨论者提出的。
- 它使用沃尔玛慷慨提供的分层销售数据,从商品级别开始,再汇总到美国三个地理区域(加利福尼亚州,德克萨斯州和威斯康星州)的部门,产品类别和商店。
- 除时间序列数据外,它还包括影响价格的解释变量,例如价格,促销,星期几和特殊事件(例如超级碗,情人节和东正教复活节),这些变量用于提高预测准确性。
- 正在通过要求参与者提供有关四个指示性预测间隔和中位数的信息来评估不确定性的分布。
- 在超过42,840个时间序列中,大多数显示间歇性(零销售,包括零销售)。
- 代替具有单个竞争来估计点预测和不确定性分布,将有两个2个使用平行的轨道相同的数据集,所述第一要求28天向前指向的预测和所述第二28天提前为中位数和四个预测概率预报间隔(50%,67%,95%和99%)。
- 第一次,它着重于显示间歇性的序列,即偶发的需求,包括零。
目标
M5竞赛的目标与前四个相似:即针对需要预测并进行不确定性估计的不同类型的情况,确定最合适的方法。其最终目的是推进预测理论并提高商业和非营利组织的利用率。它的另一个目标是将ML和DL方法的准确性/不确定性与标准统计方法的准确性/不确定性进行比较,并评估可能的改进与使用各种方法的额外复杂性和更高的成本。
期望与方法内容
鉴于前四届M竞赛的成功,吸引了众多参与者,并且做出了巨大贡献,从根本上改变了预测领域,针对快速发展的数据科学的M5竞赛有望取得相似甚至更高的成就。
社区,可以轻松访问M5数据集。它将使用Kaggle平台运行,预计参与者人数将达到数千。
目标
M5预测比赛的目标是通过确定为比赛的42840个时间序列中的每个时间序列提供最准确的点预测的方法来推进预测的理论和实践。另外,为了获得尽可能精确地估计这些序列的已实现值的不确定性分布的信息。
为此,M5的参赛者被要求为所有系列比赛提供28天的提前点预测(PFs),以及相应的中位数和50%、67%、95%和99%的预测区间(PIs)。
M5在五个重要方面与前四个有所不同,M4比赛的讨论者建议如下:
- 它使用分组单位销售数据,从产品商店级别开始,汇总到产品部门、产品类别、商店和三个地理区域:加利福尼亚州(CA)、德克萨斯州(TX)和威斯康星州(WI)。
- 除了时间序列数据外,它还包括解释性变量,如销售价格、促销活动、一周中的几天,以及特别活动(如超级碗、情人节和正统复活节),这些活动通常会影响单位销售额,并可提高预测的准确性。
- 除了点预测之外,它还评估不确定性的分布,因为要求参与者提供关于九个指示性分位数的信息。
- 与单一竞争来估计点预测和不确定性分布不同,将有两条使用同一数据集的平行轨迹,第一条需要提前28天预测点,第二条需要提前28天预测中值和四个预测区间的概率预测(50%、67%、95%,以及99%。
- 它首次将重点放在显示间歇性的序列上,即包括零在内的零星需求。
时间与举办
M5将于2020年3月2日开始,同年6月30日结束。比赛将使用Kaggle平台进行。因此,我们期望所有类型的预测者,包括数据科学家、统计学家和实践者提交许多资料,扩大预测领域,并最终整合其各种方法,以提高准确性和不确定性估计。
比赛将使用同一数据集,分为两个单独的卡格尔比赛,第一个(M5预测比赛-准确度)需要提前28天进行预测,第二个(M5预测比赛-不确定度)需要提前28天进行相应中值和四个预测区间的概率预测(50%,67%,95%和99%)。
为了支持参赛者验证他们的预测方法,比赛将包括一个验证阶段,从2020年3月2日到同年5月31日。在这一阶段,参与者将被允许使用组织者最初提供的数据来训练他们的预测方法,并使用一个28天的隐藏样本来验证他们的方法的性能,该样本没有公开。通过在Kaggle平台提交他们的预测(每天最多5个条目),参与者将被告知他们提交的分数,然后将在Kaggle的实时排行榜上公布。考虑到这种即时反馈,参与者可以通过从收到的反馈中学习,有效地修改和重新提交他们的预测。
验证阶段结束后,即从2020年6月1日至同年6月30日,将向参与者提供验证阶段用于评估其绩效的28天数据的实际值。然后,他们将被要求重新估计或调整(如果需要)他们的预测模型,以便提交他们在随后28天的最终预测和预测间隔,即用于对参与者进行最终评估的数据。在此期间,将没有排行榜,这意味着在提交预测后,将不会向参与者提供有关其分数的反馈。因此,尽管参与者可以随时自由地(重新)提交他们的预测(每天最多5个条目),但他们不会知道他们的绝对预测以及他们的相对表现。参赛者的最终排名将只在比赛结束时公布,届时将公布测试数据。这样做是为了让竞争对手尽可能地模拟现实,因为在现实生活中预测者并不知道未来。
请注意,提交系统将在比赛开始时开放,这意味着参赛者将能够在2020年3月2日至2020年6月30日提交最终预测,即使是在验证阶段。然而,如前所述,完整的M5培训样本(包括用于验证阶段排行榜的28天)将于2020年6月1日才提供。因此,在验证阶段提交最终预测的任何参与者都将错过完整培训样本的最后28天。
另请注意,M5将分为两个轨道,一个需要预测点,另一个需要估计不确定性分布,每个轨道的奖金分别为50000美元。因此,在Kaggle平台上可以看到两个单独的比赛,每个比赛都有各自的排行榜。参赛者可参加比赛,并有资格获得第一、第二或两者的奖品。
数据集
由沃尔玛慷慨提供的M5数据集涉及在美国销售的各种产品的单位销售额,以分组时间序列的形式组织。更具体地说,该数据集涉及3049种产品的单位销售额,分为3个产品类别(爱好、食品和家庭)和7个产品部门,其中对上述类别进行了分类。
这些产品在三个州(加州、德克萨斯州和威斯康星州)的十家商店销售。在这方面,层次结构的底层,即产品商店单元销售,可以映射到产品类别或地理区域,如下所示:
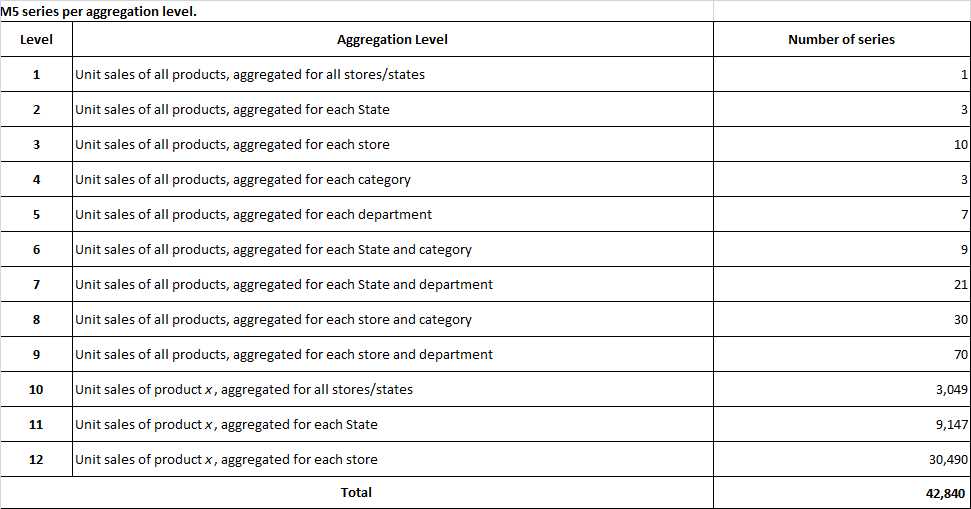
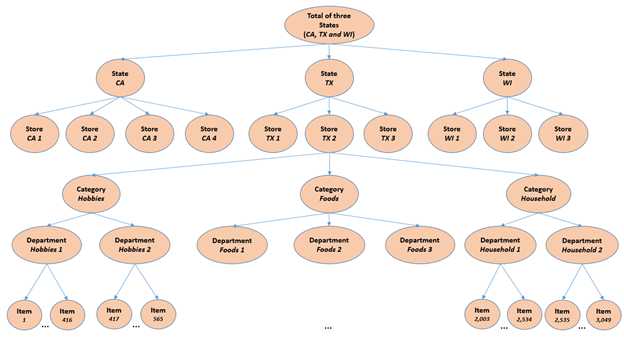
图1:M5系列如何组织的概述。
历史数据范围为2011年1月29日至2016年6月19日。因此,产品的(最大)销售历史为1941天/5.4年(不包括h=28天的测试数据)。
M5数据集由以下(3)个文件组成:
File 1: “calendar.csv”
该数据数聚包含物品得售卖时间与物品类型
- date: The date in a “y-m-d” format.
- wm_yr_wk: The id of the week the date belongs to.
- weekday: The type of the day (Saturday, Sunday, …, Friday).
- wday: The id of the weekday, starting from Saturday.
- month: The month of the date.
- year: The year of the date.
- event_name_1: If the date includes an event, the name of this event.
- event_type_1: If the date includes an event, the type of this event.
- event_name_2: If the date includes a second event, the name of this event.
- event_type_2: If the date includes a second event, the type of this event.
- snap_CA, snap_TX, and snap_WI: A binary variable (0 or 1) indicating whether the stores of CA, TX or WI allow SNAPpurchases on the examined date. 1 indicates that SNAP purchases are allowed.
File 2: “sell_prices.csv”
Contains information about the price of the products sold per store and date.
- store_id: The id of the store where the product is sold.
- item_id: The id of the product.
- wm_yr_wk: The id of the week.
- sell_price: The price of the product for the given week/store. The price is provided per week (average across seven days). If not available, this means that the product was not sold during the examined week. Note that although prices are constant at weekly basis, they may change through time (both training and test set).
File 3: “sales_train.csv”
Contains the historical daily unit sales data per product and store.
- item_id: The id of the product.
- dept_id: The id of the department the product belongs to.
- cat_id: The id of the category the product belongs to.
- store_id: The id of the store where the product is sold.
- state_id: The State where the store is located.
- d_1, d_2, …, d_i, … d_1941: The number of units sold at day i, starting from 2011-01-29.
以上是关于kaggle比赛实践M5-数据集介绍的主要内容,如果未能解决你的问题,请参考以下文章