树二叉树查找算法总结
Posted dornawe
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了树二叉树查找算法总结相关的知识,希望对你有一定的参考价值。
一、思维导图
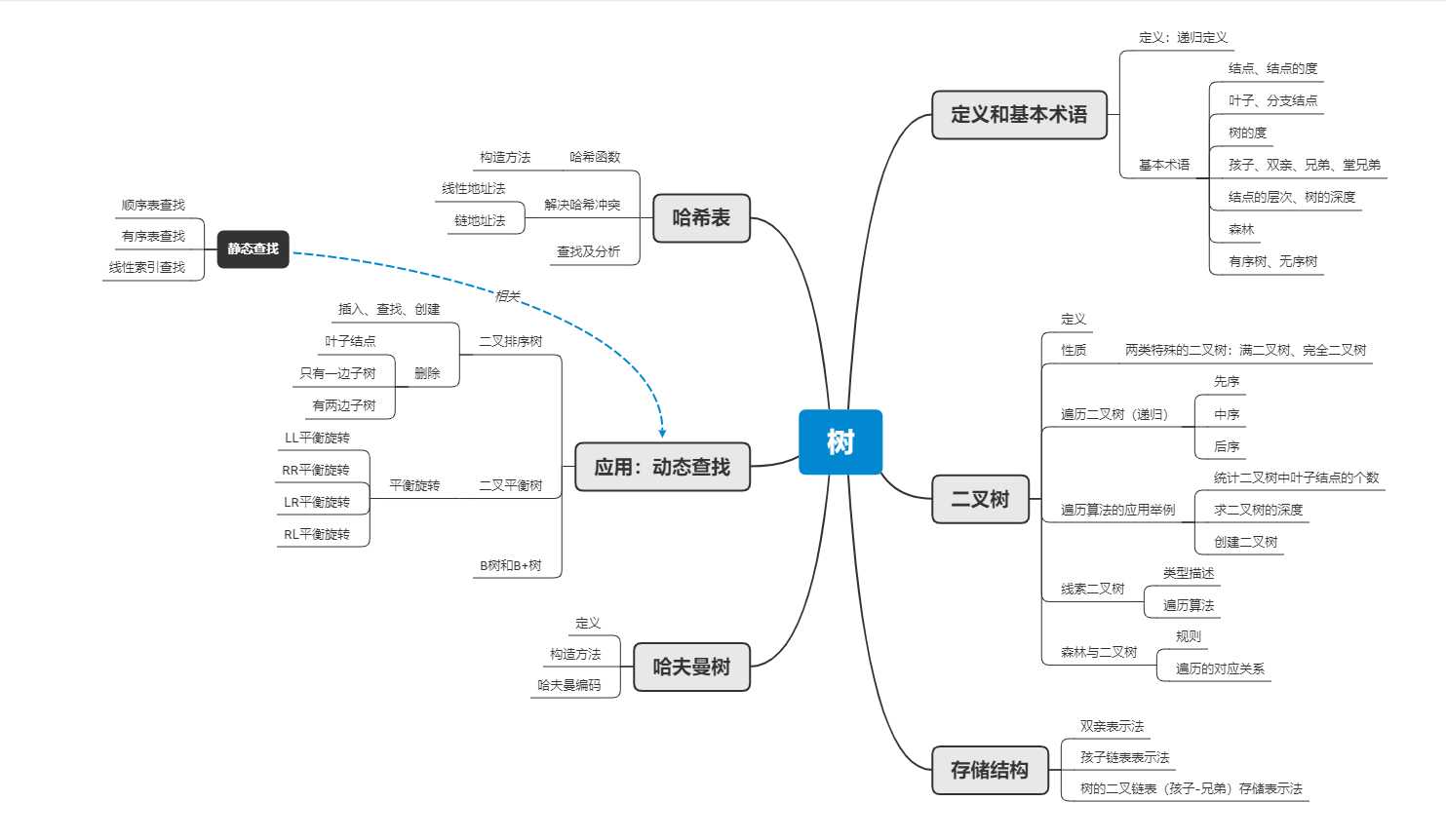
二、重要概念
一、树
1.定义:n(n>=0)个结点的有限集合T
对于非空树:
·有且仅有一个特定的称为根的结点;
·当n>1时,其余结点可分为m(m>0)个互不相交的有限集T1.T2...Tm,其中每个集合本身又是一颗树,称为根的子树。
·树的定义是一个递归定义。
2.基本术语:
·结点
·结点的度
·叶子(或终端)结点
·分支(或非终端)结点
·树的度
·结点的孩子、双亲、兄弟、堂兄弟
·结点的层次
·树的深度
·森林
·有序树、无序树
二、二叉树
1.定义
? 是n(n>=0)个结点的有限集合,它或为空树(n=0),或由一个根节点和至多两颗称为根的左子树和右子树的互不相交的二叉树组成。
2.性质
·在第i层上的最多结点个数
·已知深度的最多结点个数
·两种特殊的二叉树:满二叉树与完全二叉树
3.存储结构
1)顺序存储结构
根据完全二叉树的结点位置进行编号和存储,
2)链式存储结构
typedef struct BiTNode
{
TELemType data;
struct BiTNode *lchild,*rchild;
}BiTNode,*BiTree;
三、遍历二叉树和线索二叉树
1.遍历二叉树
·先序:访问根节点、先序遍历左子树、先序遍历右子树
void Preorder(BiTree T)
{
if(T)
{
cout<<T->data;
Preorder(T->lchild);
Preorder(T->rchild);
}
}
·中序:中序遍历左子树、访问根节点、中序遍历右子树
void Inorder(BiTree T)
{
if(T)
{
Inorder(T->lchild);
cout<<T->data;
Inorder(T->rchild);
}
}
·后序:后序遍历左子树、后序遍历右子树、访问根节点
void Aftorder(BiTree T)
{
if(T)
{
Aftorder(T->lchild);
Aftorder(T->rchild);
cout<<T->data;
}
}
·因为树的定义是一种递归的定义,所以对树的相关操作也是递归的操作或者是用栈的操作。
2.线索二叉树
·用途:找到先序/中序/后序遍历的下一节点
·类型描述
typedef struct BiThrNod{
TElemType data;
struct BiThrNode *lchild,*rchild;
int LTag,RTag;
}BiThrNode,*BiThrTree;
·遍历算法:
void InOrderTraverse_Thr(BiThrTree T)
{
p=T->lchild;
while(p!=T){
while(p->LTag==0) p=p->lchild;
cout<<p->data;
while(p->RTag==1&&p->rchild!=T){
p=p->rchild;
cout<<p->data;
}
p=p->rchild;
}
}
四、树与森林
1.树的存储结构
·双亲表示法
·孩子链表表示法
树的二叉链表(孩子-兄弟)存储表示法
typedef struct CSNode
{
Elem data;
struct CSNode *firstchild,*nextsibling;
}CSNode,*CSTree;
2.森林和二叉树的转换
·和树对应的二叉树:左是孩子,右是兄弟
·树的遍历和二叉树的遍历的对应关系:
树的先跟遍历顺序与森林先序遍历以及二叉树的先序遍历顺序一致
树的后跟遍历顺序与森林中序遍历以及二叉树的中序遍历顺序一致
五、哈夫曼树及其应用
1.最优二叉树(哈夫曼树)
在所有含n个叶子结点、并带相同权值的m叉树中,必存在一棵其带权路径长度取最小值的树,称为“最优树”。
·构造方法:
1)根据给定的n个权值{W1,W1,...,Wn},构造n棵二叉树的集合F={T1,T2,...Tn},(其中每棵二叉树中均只含一个带权值为Wi的根节点,其左、有子树为空树;
2)在F中选取其根结点的权值最小的两棵二叉树,分别作为左、右子树构造一棵新的二叉树,并置这棵新的二叉树根结点的权值为其左、右子树根结点的权值之和;
3)从F中删去这两棵树,同时加入刚生成的新树;
4)重复 (2) 和 (3) 两步,直至 F 中只含一棵树为止。
2.哈夫曼编码
·编码方式为前缀编码
六、查找
1.静态查找
1)顺序表查找:按顺序遍历表
·ASL(平均查找长度)的计算。
2)有序表查找:可以进行折半查找
3)线性索引查找:
·分块索引
·倒排索引
·稠密索引
2.动态查找
1)二叉排序(查找)树
·查找
BTree SearchBST(BTree T, int key)
{
if (T)
{
if (T->data==key)
{
return T;
}
else if(T->data<key)
{
T=SearchBST(T->lchild,key);
}
else
{
T=SearchBST(T->rchild,key);
}
}
else
{
return NULL;
}
}
·插入
void InsertBST(BTree &T, int key)
{
if (!T)
{
T = new BTNode;
T->data = key;
T->lchild = T->rchild = NULL;
}
else
{
if (T->data==key)
{
return;
}
else if(T->data>key)
{
InsertBST(T->lchild, key);
}
else
{
InsertBST(T->rchild, key);
}
}
}
·创建
void CreateBST(BTree &T)
{
int x;
cin >> x;
T = new BTNode;
T->data = x;
T->lchild = T->rchild = NULL;
for(int i=0;i<11;i++)
{
cin >> x;
InsertBST(T, x);
}
}
2)二叉平衡树
·LL平衡旋转:若在A的左子树的左子树上插入结点,使得A的平衡因子从1增加到2,需要进行一次顺时针旋转。
·RR平衡旋转:若在A的右子树的右子树上插入结点,使得A的平衡因子从-1增加至-2,需要进行一次逆时针旋转。
·LR平衡旋转:若在A的左子树的右子树上插入结点,使A的平衡因子从1增加至2,需要选转换为LL,再进行旋转。
·RL平衡旋转:若在A的右子树的左子树上插入结点,使A的平衡因子从-1增加到-2,需要转换为RR,再进行旋转。
3)B树
·定义:所有结点平衡因子均等于0的多路查找树。
·特点
·添加、删除:分裂、合并
4)B+树
·与B树的差异
·结构特点
3.哈希表
1)哈希函数
建立关键字与记录在表中的存储位置之间的函数关系,以f(key)作为关键字为key的记录在表中的位置,通常称这个函数f(key)为哈希函数。
·哈希表的定义:
将一组关键字映像到一个有限、地址连续的地址集(区间)上,并以关键字在地址集中的"像"作为相应记录在表中的存储位置,如此构造所得的查找表称之为“哈希表”。
2)哈希函数的构造方法:
·直接定址法
·数字分析法
·平方取中
·折叠
·除留余数
H(key)=key MOD p
其中p<=m(表长)并且p应为不大于m的素数或者不含20以下的质因子
3)处理冲突的方法
a.开放定址法
·di=c*i
·di=+1^1,-1^1,+2^2,-2^2,……+i^i,-i^i(i<=m/2)
b.链地址法
4)结论
·对哈希表技术具有很好的平均性能,优于一些传统的技术;
·链地址法优于开地址法;
·除留余数法作哈希函数优于其他类型函数。
三、疑难问题
1.哈希表的ASL求解
1)线性探测:
·查找成功的ASL:次数和除于有记录在表中的元素和;
·查找不成功的ASL:按表以此每个元素到下一个空元素的查找次数之和除于表中所有元素和。
2)链地址法
·查找成功的ASL:按列来算:每一列不为空的元素相加除于有记录在表中的元素和。
·查找成功的ASL:按行来算:每一行的不为空数值相加除于表中所有元素和。
eg:

以上是关于树二叉树查找算法总结的主要内容,如果未能解决你的问题,请参考以下文章