7.逻辑回归实践
Posted a131452
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了7.逻辑回归实践相关的知识,希望对你有一定的参考价值。
1.逻辑回归是怎么防止过拟合的?为什么正则化可以防止过拟合?(大家用自己的话介绍下)
逻辑回归是通过正则化来防止过拟合的;
正则化可以防止过拟合是:因为过拟合的时候,拟合函数的系数往往非常大,而正则化是通过约束参数的范数使其不要太大,所以可以在一定程度上减少过拟合情况。
正规化背后的思路就是:如果我们的参数值对应一个较小值的话(参数值比较小),那么往往我们会得到一个形式更简单的假设。
正则化因子,也就是里面的那个lamda,如果它变大了,说明目标函数的作用变小了,正则化项的作用变大了,对参数的限制能力加强了,这会使得参数的变化不那么剧烈。
对于房屋价格预测我们可能有上百种特征,如果我们有一百个特征,我们并不知道如何选择关联度更好的参数,如何缩小参数的数目等等。因此在正则化里,我们要做的事情,就是把减小我们的代价函数(例子中是线性回归的代价函数)所有的参数值,因为我们并不知道是哪一个或哪几个要去缩小。因此,我们需要修改代价函数,在这后面添加一项,就像我们在方括号里的这项。当我们添加一个额外的正则化项的时候,我们收缩了每个参数。
2.用logiftic回归来进行实践操作,数据不限。
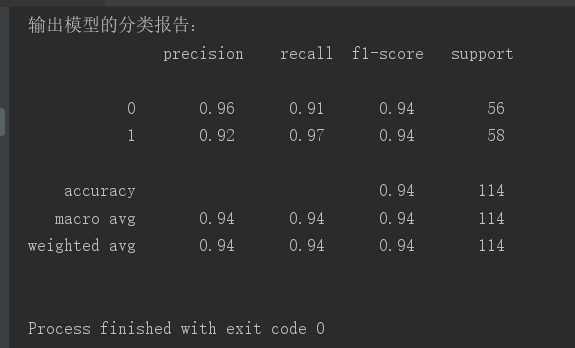
from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.metrics import classification_report # 获取乳腺癌数据 data = load_breast_cancer() # 把数据划分为属性值x和结果集y x=data[‘data‘] y=data[‘target‘] # 对数据进行划分测试集和训练集,并制定随机种子 x_tr,x_te,y_tr,y_te=train_test_split(x,y,test_size=0.2,random_state=6) # 初始化逻辑函数模型 lr = LogisticRegression() # 对模型进行训练 lr.fit(x_tr,y_tr) # 对模型进行预测 pre = lr.predict(x_te) # 输出数据 print(‘训练的得分:‘,lr.score(x_tr,y_tr)) print(‘测试的得分:‘, lr.score(x_te,y_te)) print(‘输出模型的分类报告: ‘,classification_report(y_te,pre))
实验截图:

以上是关于7.逻辑回归实践的主要内容,如果未能解决你的问题,请参考以下文章