机器学习简单介绍
Posted wuzc
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习简单介绍相关的知识,希望对你有一定的参考价值。
机器学习不是科幻电影。
机器学习目的是解放生产力。
机器学习原理
机器学习: 机器自主获取事物的规律。
要让机器可以 “学习”,必须将生活中的数据(包括但不限于图像、文字、语音)数值化,将不同事物的变化和关联转化为运算。
机器学习可以成立的原因是:概念和数值、关系和运算可以相互映射。
机器学习的种类
-
按照是否有标签划分
1、有监督
训练哈士奇就是典型的有监督学习,每一次的指令都是一个数据样本(Sample),被摸头(正确)和挨打(错误)就是数据样本的标签(Label),给数据样本打上标签的过程就叫做标注(Labeling)。
2、无监督
告诉机器一些特征(Features),例如:是否有角,是否长翅膀,让机器自己去 “聚类”, 这就是一次无监督的学习。
无监督学习没有给定事先标记过的训练示例,自动对输入的数据进行分类或分群。 根据类别未知(没有被标记)的训练样本解决模式识别中的各种问题,称之为无监督学习。
-
按照处理问题场景划分
1、分类和回归
给定一个样本特征 , 我们希望预测其对应的属性值 , 如果 是离散的, 那么这就是一个分类问题,反之,如果 是连续的实数, 这就是一个回归问题。
2、聚类
如果给定一组样本特征 , 我们没有对应的属性值 , 而是想发掘这组样本在 维空间的分布, 比如分析哪些样本靠的更近,哪些样本之间离得很远, 这就是属于聚类问题。
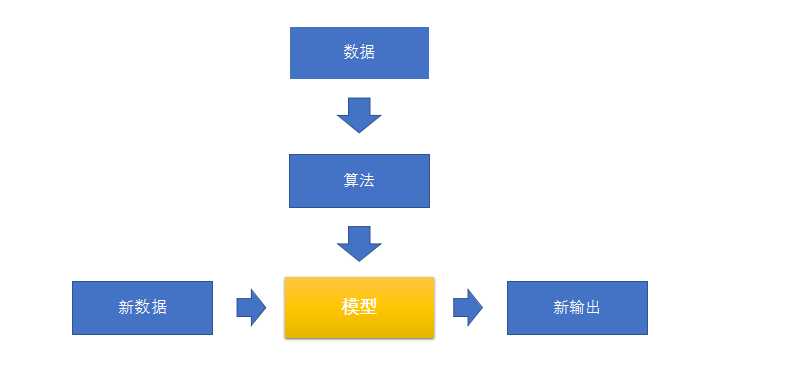
机器学习三要素——数据、模型、算法
数据
数据 也就是源数据, 指还未转换为机器可以识别的数据样本
向量空间模型(VSM, Vector Space Model): 负责将格式(文字、图片、音频、视频)转化为一个个向量。
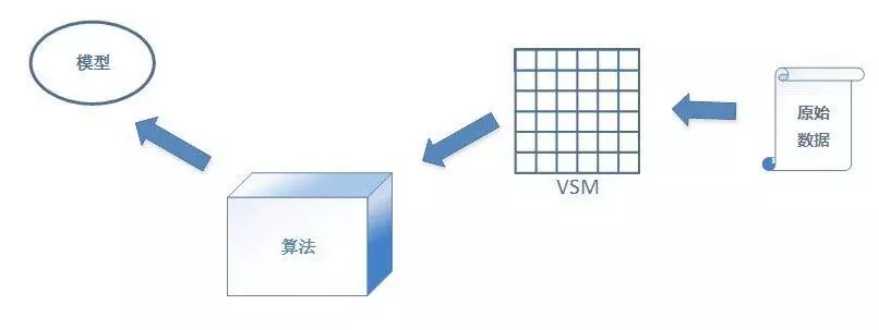

模型
1. 模型如何得到
模型是机器学习的结果,而这个学习的过程称为训练(Train) 一个训练好的模型可以被理解成一个函数:y=f(x) 这个 y 可能是一个数值(回归),也可能是一个标签(分类)
2. 什么是训练
根据已经被指定的 f(x) 的具体形式 —— 模型类型,结合训练数据,计算出其中各个参数的具体取值的过程。 比如一个线性模型:y=f(x)=ax^2+bx+c 训练就是为了找到其中 a、b、c 的值
算法
算法 :训练过程需要依据某种章法进行运算。这个章法,就是算法。
损失函数(Loss Function): 需要用一个函数来描述 y‘ 与 y 之间的差别,这个函数叫做损失函数(Loss Function)
代价函数(Cost Function): 损失函数针对一个训练数据,对于所有的训练数据,我们用代价函数来描述整体的损失 。
目标函数: 因为代价函数表示的是整个模型付出的代价,所以代价要越小越好。因此我们就得到了一个学习目标,就是找到目标函数。
优化算法: 为了让 J(Θ) 达到最小就要使用优化算法。
模型构造
数据 + 算法 = 模型
1. 数据准备
数据预处理:收集数据、清洗数据、标注数据。
构建数据的向量空间模型。
将构建好的向量空间模型分为训练集、验证集和测试集。
2. 训练
训练的核心是算法
3. 测试
测试集数据 --输入--> 模型(预测结果)--> 将预测结果与原本的预期进行比较
4. 衡量当前模型的质量
按照一定的规则计算模型质量的衡量指标(Precision、Recall、F1Score 等等),根据指标的数值来衡量当前模型的质量。
训练集、验证集和测试集
- 训练集(Train Set):用来做训练的数据的集合。
- 验证集(Validation Set):在训练的过程中,每个训练轮次结束后用来验证当前模型性能,为进一步优化模型提供参考的数据的集合。
- 测试集(Test Set):用来测试的数据的集合,用于检验最终得出的模型的性能。
每个集合都应当是独立的,和另外两个没有重叠。
其中数据量最大的是训练集,通常训练集和测试集比例为8/2或9/1或7/3。
整体数据量不大,模型又相对简单时,验证集和测试集也可以合二为一。
训练的过程
1. 编写训练程序
- 选择模型类型;
- 选择优化算法;
- 根据模型类型和算法编写程序。
2. 训练 -> 临时模型
3. 在训练集上运行临时模型,获得训练集预测结果。
4. 在验证集上运行临时模型,获得验证集预测结果。
5. 综合参照第 3 步和第 4 步的预测结果,改进模型。
6. 回到第 2 步,反复迭代,直到结果满意或者已经无法继续优化
模型评估
当我们训练出了一个模型以后,为了确定它的质量,我们可以用一些知道预期预测结果的数据来对其进行预测,把实际的预测结果和实际结果进行对比,以此来评判模型的优劣。
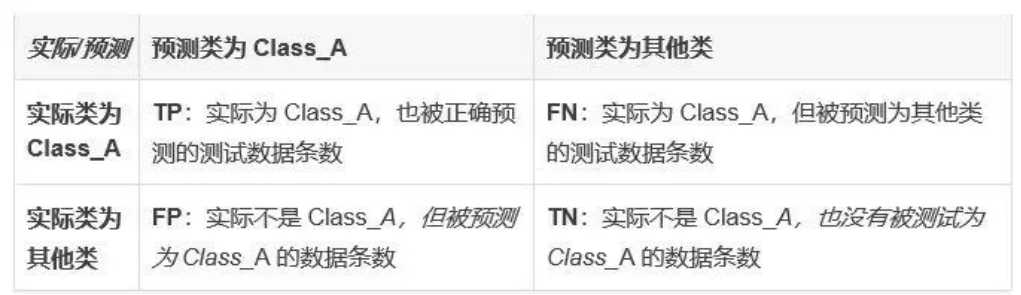
分类模型评判指标: Precision、Recall 和 F1Score
精准率:Precision=TP/(TP+FP),即在所有被预测为 Class_A 的测试数据中,预测正确的比率。
召回率:Recall=TP/(TP+FN),即在所有实际为 Class_A 的测试数据中,预测正确的比率。 F1Score = 2*(Precision * Recall)/(Precision + Recall)
回归模型的偏差和过拟合
对训练集样本拟合程度的角度,可以分为两类:欠拟合(Underfitting)和过拟合 (Overfitting)。
欠拟合:如果一个模型,在训练集上的预测结果就不佳,指标偏低,那一般是欠拟合的问题。 (学习的太好了,太关注局部特征)
过拟合:如果在训练集上指标很好,而在验证/测试集上指标偏低,则很可能是过拟合问题。(没有学到训练数据的普遍规律)
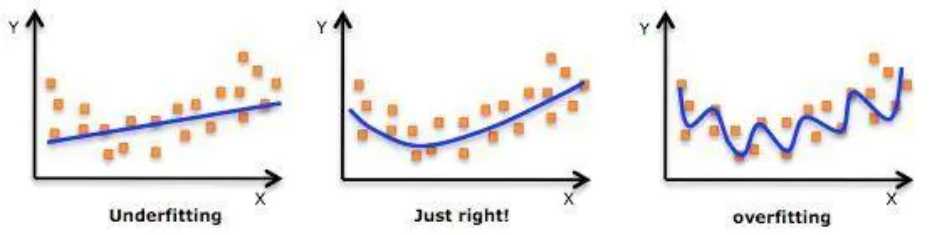
经验误差和泛化误差
经验误差:在训练集上的误差称为“训练误差”或“经验误差”。 (真实值和预测值的误差)
泛化误差:在测试集上的误差称为“泛化误差”。
评价策略:哪一个模型的经验误差和泛化误差上相近又小
回归模型的评价指标 MSE (Mean Squared Error)叫做均方误差。
这里的y是测试集上的输出。
用 真实值-预测值 然后平方之后求和平均。
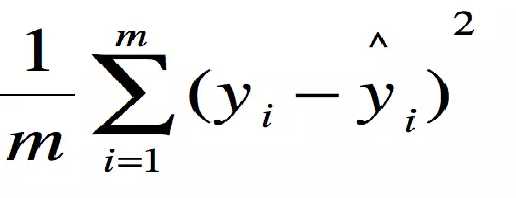
模型优化
模型的优化可以从三个方面来进行:数据、算法和模型。
数据(特征工程)
- 对数据进行归一化(Normalization,又译作正规化、标准化)等操作。
- 采用 Bootstrap 等采样方法处理有限的训练 / 测试数据,以达到更好的运算效果。
- 根据业务进行特征选取:从业务角度区分输入数据包含的特征,并理解这些特征对结果的贡献。
调参(算法参数)
我们训练模型的目的就是为了得到模型对应公式中的若干参数。这些参数是训练过程的输出,并不需要我们来调。 除了这些参数外,还有一类被称为超参数的参数,例如用梯度下降方法学习 LR 模型时的步长(Alpha),用 BFGS 方法学习 Linear-chain CRF 时的权重(w)等。
超参数是需要模型训练者自己来设置和调整的
通过调参方法来减轻调参工作量,例如 Grid Search 等。 调参没有固定的规律可以遵循,往往有很多运气成分,但靠瞎猜基本不可能得出好的结果,还是要按一定的方法来做。
算法选择
1. 算法选对的,别选贵的。前沿的不一定是好的。
2. 数据最重要,我丑话在先。
以上是关于机器学习简单介绍的主要内容,如果未能解决你的问题,请参考以下文章