十分钟搞懂Elasticsearch数字搜索原理
Posted sunshuyi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了十分钟搞懂Elasticsearch数字搜索原理相关的知识,希望对你有一定的参考价值。
更多精彩内容请看我的个人博客或者扫描二维码,关注微信公众号:佛西先森

前言
Elasticsearch诞生的本意是为了解决文本搜索太慢的问题,ES会默认将所有的输入内容当作字符串来理解,对于字段类型是keyword或者text的数据比较友好。但是如果输入的类型是数字,ES还会把数字当作字符串吗?排序问题还有范围查询问题怎么解决呢?这篇文章就简单介绍了ES对于数字类型(numeric)数据的处理,能让你大涨姿势
简介
Elasticsearch专为字符串搜索而生,在建立索引的时候针对字符串进行了非常多的优化,在对字符串进行准确匹配或者前缀匹配等匹配的时候效率是很高的。ES底层把所有的数据都会当成字符串,其中就包括数字——所有的数字在ES底层都是会以字符串的形式保存。
这就和我们通常理解的数字就不一样了,在mysql或者各种编程语言比如Java、Python中,数字比如int类型就是4个字节呀!最高位符号位,后面的位数按照二进制进行存储,还能有其他的表示方式?
出现这个现象的原因就是ES和MySQL或者Java中对数字的需求不一样了。在编程语言中,数字要经常参与计算比如加减乘除还有移位以及比较大小操作,这个时候用int这种原生的方式是简单直接效率高的;在MySQL中,索引是以B+树的形式存储,每次查询某一个数字都要在树中把整个数字和分隔节点进行比较操作,直到找到最后的目标数据节点。
可以看到直接使用int的本身的结构来存储的优势就是直接比较大小的效率非常高(空间消耗小也是另外一个优势),但是如果进行范围查询,就会有问题了。比如在MySQL的组合查询中如果出现范围查询,那么很有可能出现范围查询后面的索引是不生效的(具体的MySQL的组合查询的原理可以在网上看看),也就是说范围查询可能会降低查询性能;在编程语言中的集合的范围查询就只能遍历所有的元素,一一比较大小,没有优化。
ES的出现为解决范围查询提供了一个新的思路——为不同精度范围内的数据直接建立索引,把符合范围查询要求的数据聚合到一个索引上面,在搜索的时候把大的搜索范围拆分成很多小的范围索引,直接用term搜索就可以找到符合要求的所有文档。
emmm...是不是有点抽象╮(╯_╰)╭
比如想搜索在[300,500]内的文档并且事先已经把值在[300,400]之间的文档索引到了3、[400,500]之间的文档索引到了4,那么就直接通过term查询取出3和4对应的文档id列表并且进行or操作就可以了,简单直接高效。
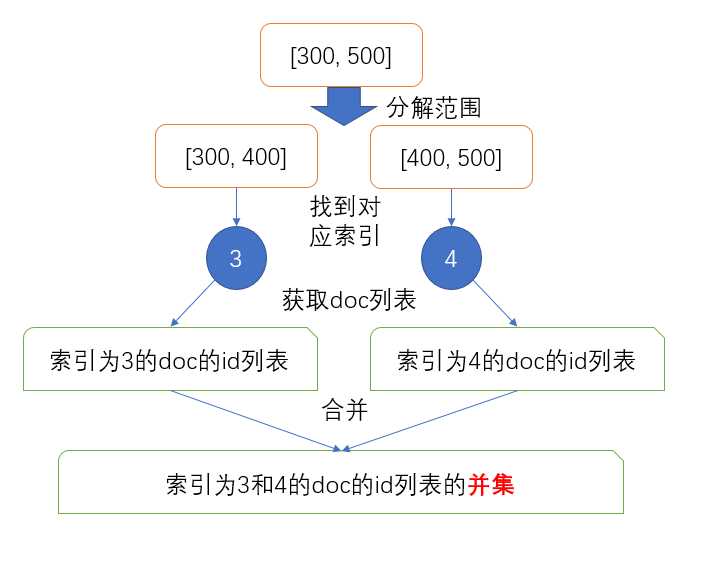
原理虽然简单,不过实现起来还是有些困难需要解决的。
数字直接变成字符串的问题
ES并没有直接把数字变成字符串,也没有对每个数字建立简单的索引,因为这两种做法可能会带来一些问题。
字符串比较
首先最大的问题是数字变成字符串之后如何进行比较,如果直接是把十进制的数字变成字符串,排序按照字典序(lexicographic)比较(默认所有的term都是按照字典序比较大小),会有不同位数比较的问题。比如搜索[423,642]内的文档,5也会被算在内,因为字典序"5"比"423"大,比"642"小。
这个问题的一个解决方案是在每个数字变成字符串的时候在前面填充0,把5变成005,这样就能正确比较大小了,这也是旧版本的ES采用的解决方案。但是每次把int转化成string的时候要填充多少个0呢?太多了占空间,太少了又可能因为数字太长影响比较,比如最多只填充2个0,对于1000以下的数字没有问题,当数字大于1000了,个位数填充2个0就不够用了。
获取的范围过多
另一个问题是范围内的term过多带来的性能下降。比如现在有很多文档,其中索引的数字的列表为[421,423,445,446,448,521,522,632,633,634,641,642,644]一共13个term,如果我们想要查询[423,642]之间的所有的文档,需要取出一共11个term,然后用这些term去搜索对应的文档。
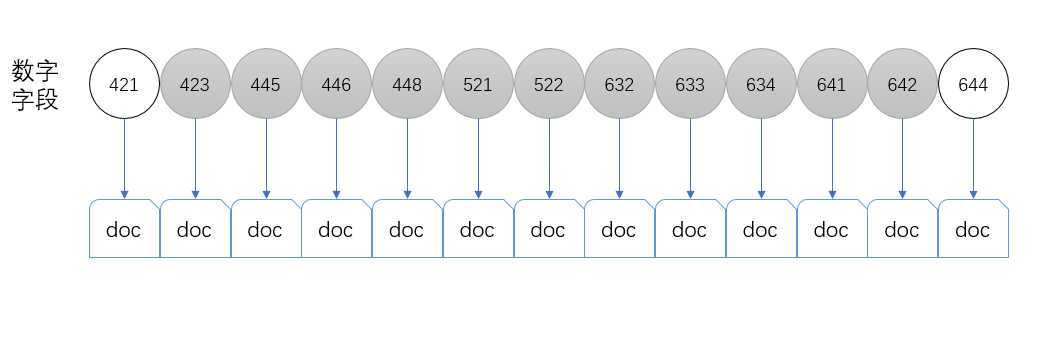
当范围越来越大,需要的term的数量就越来越多,查询的性能就会不断下降。
ES是怎么把数字变成字符串
先来解决第一个问题,数字怎么变成字符串。
十进制的数字有填充问题,如果变成了二进制,再进行词典序比较,不就没有问题了吗?Perfect,似乎问题完美的解决了。
哥么你就没有考虑过负数的感受吗?

二进制的int保证是32位,对于正数和正数的比较或者负数和负数的比较是没有问题的,可是正数和负数的比较就不行了。正数的最高位是0,负数的最高位是1,直接比较,负数永远大于正数。这个时候ES采用的方法是把正数最高位变成1,负数最高位变成0,这样正数用于大于负数,问题就解决了。
int类型解决了,float呢?由于浮点数在Java中的表示方法,最高位符号位,2330位是指数位,022是尾数,如果直接把一个正的float当作int类型来比较好像也没有什么问题,指数位高的,当然大;指数相同,尾数大的也自然数字就大,所以正浮点型可以直接当成int转化。但是负数就不行了,指数越大,数字越小,尾数越大,数字也越小。ES给出的解决方案是直接对低31位每一位取反,1变成0,0变成1,这样负数的float就可以比较大小了。总结就是正float当int用,负float低31位取反后当成int用。
对于long和double类型,也是同样的道理,只不过32位变成了64位。
你以为就这样变成了二进制字符串了吗?不,还没有,没有这么简单。
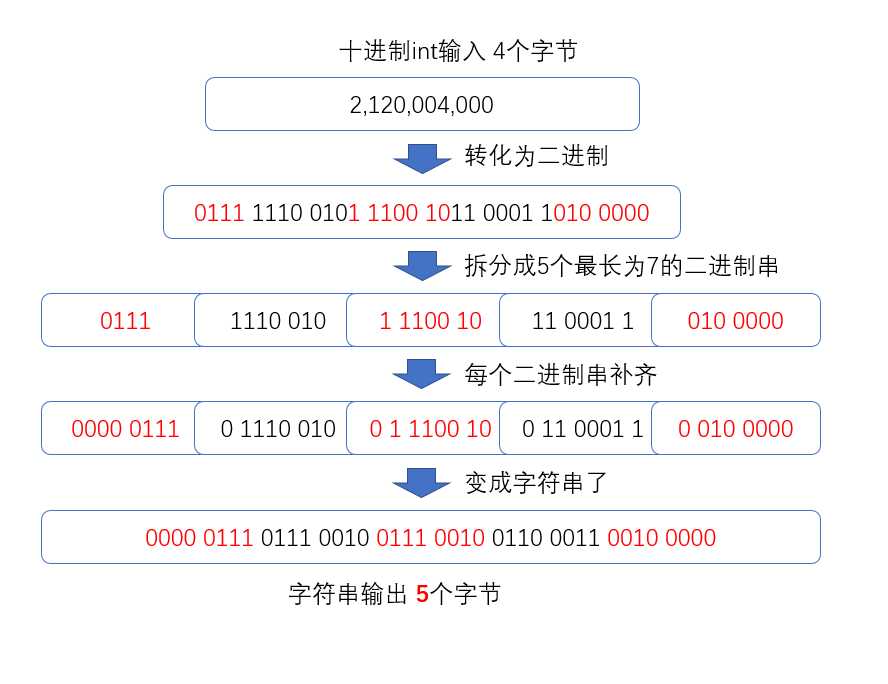
刚才是把int变成了二进制的字符串,一个字符只保存0和1不觉得浪费吗?一个int要用32个字符也就是32个字节保存,暴殄天物呀!
Java的1个int占4个字节,1个char是2个字节,1个int用2个char不就行了。但是Java使用Unicode字符集来保存字符串,ES用UTF8编码保存Unicode字符,对于0~127使用1个字节,大于127一般2个字节,汉字通常3个字节,这样的话1个int用2个char表示,最多需要6个字节(这里int虽然不是汉字,但是在变成char之后有可能在Unicode字符集中表示某一个汉字)
ES表示还能做的更好,上面不是说0~127只用一个字节吗?好,我就把int切分之后的大小限制在127以内(原来默认切分是4组8位的二进制数字)。127是7位二进制数字,int是32位的,那就把32位的int变成由4、7、7、7、7这5组二进制组成,最后这个字符串只需要5个字节就可以了,和上面的6个字节相比,空间利用率提高了17%!
数字的索引是什么样子
上面说到的另外一个问题是查询term数量太多的问题,解决方案就是用空间换时间,通过前缀聚合部分的term来达到。
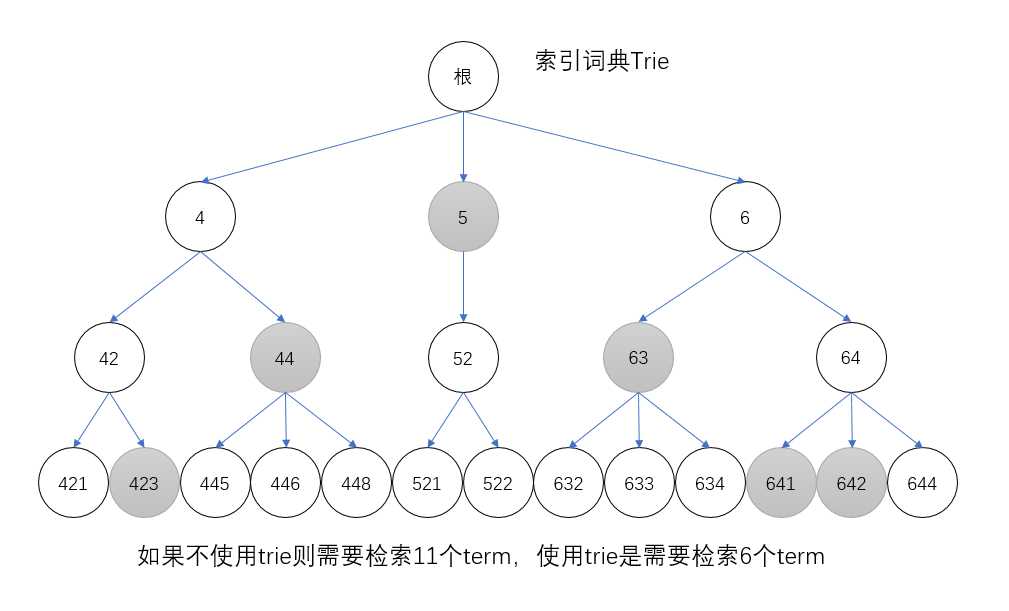
这里的聚合的实现方式是采用trie的数据结构,比如445、446和448这个三个term,可以聚合到44这个term的下面,节点44包含的文档的id列表应该是所有子节点的并集,这样原先需要的11个term就可以减少2个。同理对于其他的term也进行合并,合并之后[423,642]查询就只需要6个term,效率提高了一倍!
然而聚合也是要讲道理的,把445、446和448聚合到44以及把44聚合到4相当于是把数字除以10,精度就是10。但是并不是一直都希望这个精度是10,也可以设置为100(精度相对应的降低,节约索引空间)等等。ES提供了precisionStep来定制化这个精度,不过不是针对十进制,而是二进制的位数。比如precisionStep设置为4,那么在二进制位里面每隔4位(相当于十进制的16)就建立一个前缀聚合索引。
比如对于二进制数字0100 0011 0001 1010,当precisionStep为4的时候,会建立4个索引——0100 0011 0001 1010、0100 0011 0001、0100 0011以及0100(最高的4位),这四个索引相当于从trie的子节点一直到根节点
精度越高(precisionStep越小)索引就越大,查询速度越快;精度越低,索引越小,相对查询速度比较慢。
比如对于long类型的数据,precisionStep是4的时候,最多需要同时搜索465个term;precisionStep是2的时候,最多只要189个term。不过并不能绝对的说精度越高越好,因为查找这些term需要的时间也会相应增加。实际上最佳的precisionStep还是要根据业务情况测试得出。
上面根据precisionStep建立索引的过程中有一个特殊的分词器来帮助拆分,比如把423拆成423、42以及4。不过分词器会同样的把4拆分成4,那怎么区分423的4和4的4呢?
那就需要额外的空间来区分这两个4,ES给出的解决方案是在这两个数字前面加上一个前缀shift表示偏移量。比如423的4,shift是2(423的42的shift是1,423的shift是0);而4的4,shift是0,所以前者的4比后者的要大。分词之后的term在每次比较之前都会先比较shift,shift越大,相应的term也越大,避免的重复的问题。
总结上面建立索引的过程:当一个文档进来的时候,有一个数字423需要建立索引,于是先把这个int数据转化成字符串,再用一个特殊的分词器根据精度把423分成对应的三个term423、42和4,并且附上对应的前缀shift,接下来在trie中找到这几个term,把稳定的id添加到这几个term的文档id列表里面(如果不存在就创建这个term)。
查询原理
清楚了数字类型的数据的索引机制之后,范围查询的原理就比较简单了。
比如有一个范围[423, 642],要找到字段大于等于423并且小于等于642的文档。
- 先在索引的trie里面找到这两个term以及范围内的兄弟节点,分别是trie的两个叶节点423、641和642
- 从叶节点向上缩小范围,对两个数字分别除以10加一和减一之后查找范围为
[43,63],此时的shift是1,得到这一层级的“叶子节点”以及范围内的兄弟节点是44和63 - 再从这一层向上,两个数字除以10,分别加一减一,得到范围
[5,5],shift为2,这就是最后的节点了,term是5 - 上面三个步骤得到最后需要的term是423、44、5、63、641和642
上面是用十进制举得一个例子,在二进制里面也是同样的道理,这里就不啰嗦了。实际上在ES实现里面用了很多位操作,效率相比于使用十进制要高很多,感兴趣的同学可以去看源代码,在LegacyNumericUtils类的splitRange方法里面。
总结
总的来说,Elasticsearch对于数字类型数据的索引和搜索不同于传统的MySQL或者Java等编程语言,采用了独特的字符串存储以及Trie数据结构保存索引的方式。
ES先将输入的数字进行预处理,把float和double分别映射成int和long,原来是int和long类型的则保持不变
然后把输入的整型数字切分成许多组由最长7位二进制数字组成的二进制串,每组二进制数字都是一个Unicode字符,整体连起来变成一个Unicode字符串
接下来根据precisionStep把这个字符串数字分词成很多term,并附上前缀shift
根据这些term建立索引词典,词典的结构类似于一个trie
范围查询的时候根据trie把所谓的范围区间划分成离散的term字符串,这些term指向的文档的并集就是范围查询的结果
One more thing
谢谢各位大佬看完了这篇文章,在这里我很遗憾的通知您,以上提到的ES数字类型数据处理的方式已经被废弃了??

ES使用的搜索库Lucene在6.0版本以及以后为了解决多维空间位置搜索问题,改用新的数据结构——BKD树来实现位置搜索,带来了很大的性能提升。开发者发现这种实现也能用于一维数据搜索,于是用新的数据结构代替了现在的字符串的实现
我会在以后专门写一篇文章介绍BKD树在ES中的应用
参考
The Evolution of Numeric Range Filters in Apache Lucene
Numeric datatypes
Class IntField
Package org.apache.lucene.search
Integer size vs Long size
Lucene的数字范围搜索 (Numeric Range Query)原理
Lucene 4 和 Solr 4 学习笔记(3)
Class LegacyNumericRangeQuery
LegacyNumericUtils
Class NumericRangeQuerys
以上是关于十分钟搞懂Elasticsearch数字搜索原理的主要内容,如果未能解决你的问题,请参考以下文章
大数据搜索引擎 Elasticsearch 数字类型(numeric)数据的处理与搜索原理。
Elasticsearch教程 Elasticsearch查询语法 Elasticsearch权威指南 深入理解Elasticsearch