最大似然估计和最大后验概率估计(MLE&MAP)
Posted feynmania
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了最大似然估计和最大后验概率估计(MLE&MAP)相关的知识,希望对你有一定的参考价值。
0.相关概念
数据:X
参数:theta
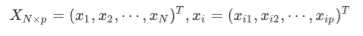
假设概率模型为:x~p(x|theta) 【xi服从于p(x|theta),并且是独立同分布(iid)】
明确先验、后验和似然的概念:
似然(likelihood):p(X|theta)
先验(prior):p(theta):(随机变量)参数theta所服从的分布
后验(posterior):p(theta|X):
问题:参数估计问题,也就是求theta的值。
关于这个问题频率派常用最大似然估计方法(MLE),贝叶斯派常用最大后验估计方法(MAP)。
1.频率派的特点是将theta作为常量;X作为随机变量。常用最大似然估计(MLE)进行参数估计。MLE步骤为:
①首先搭建模型,
②然后将模型转化为优化问题(有 loss function)
③然后用不同的优化算法求解(比如梯度下降法,牛顿法等等)
代价函数为观测集的概率
因为是独立同分布,所以观测集概率可表示为连乘:
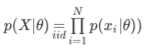
最大对数似然估计(MLE)方法求解theta:【加上log是为了将连乘转化为,方便运算。通过求解最大似然估计得到theta的值】
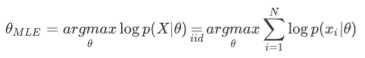
2.贝叶斯派的特点是将theta作为随机变量【theta~p(theta)】;X也作为随机变量。常用最大后验概率估计(MAP)进行参数估计。MAP步骤为:
①用贝叶斯定理将求解后验概率转化为求解似然和先验的积分问题:【 贝叶斯定理是用似然和先验求解后验的过程。】
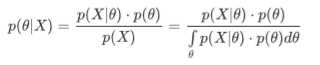
②最大后验概率方法求解theta的值:
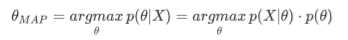
3.引申:
频率派后续引出一系列统计机器学习的方法,主要步骤为搭建模型,构造损失函数(loss funcion),选取优化算法进行优化,本质是优化问题。
贝叶斯派后续引出一些列概率图模型,主要是用数值方法求积分,因为在参数空间中求积分,所以转而寻找用概率图求积分的方法,常用MCMC、蒙特卡洛等方法。
传统贝叶斯估计需要求积分:
将后验概率用于贝叶斯预测:【通过theta将x_new和X解构】
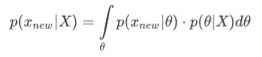
参考资料:
https://www.bilibili.com/video/BV1aE411o7qd?p=2 ,B站机器学习白板推导,作者:shuhuai008
以上是关于最大似然估计和最大后验概率估计(MLE&MAP)的主要内容,如果未能解决你的问题,请参考以下文章
机器学习基本理论详解最大似然估计(MLE)最大后验概率估计(MAP),以及贝叶斯公式的理解
机器学习基础系列--先验概率 后验概率 似然函数 最大似然估计(MLE) 最大后验概率(MAE) 以及贝叶斯公式的理解