一门新技术或者开源项目我是如何从头开始学习
Posted adaicoffee
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一门新技术或者开源项目我是如何从头开始学习相关的知识,希望对你有一定的参考价值。
开篇
对于一门新技术或者开源项目如何从头开始学习?相信每个人都有不同的想法和见解,下面谈谈我个人的想法和实践
万变不离其宗
无论你学习的新知识是什么,首先可以简单的百度 google一下,比如我想要学习netty,那么就搜索 "netty 介绍",读完过后,一定要去官方网站看一下。一般的开源项目都放在github上,且有一个readMe.md文件,我建议你一定要去读一遍。因为官网上的文档信息一定是最全最新的,所有其他网站的资料,几乎都是从官网上搬运过去的,且很有可能相关资料已经过时。
无论怎样,对于一门新知识的学习,建议你一定要去官网上看一下文档
重量级知识
这里的“重量级知识”是指有难度,有深度,且相对不容易掌握的知识,例如elasticsearch、netty、Java多线程、JVM底层,这些知识的学习是需要时间沉淀的,不可能一蹴而就。
这些知识,往往不是简单掌握用法、API即可,不然很有可能会埋坑,且在将来某个时间爆发。
就拿我亲身经历来说,以前我们有个项目需要使用elasticsearch,且该项目非常紧急,我和另一个同事之前都没有任何elasticsearch相关经验,我们从网上简单了解并学习相关elasticsearch api过后,就直接在项目中使用,而我们判断elasticsearch是否正确使用的依据,就是 业务 “CRUD” 相关功能是否正常。
受益于elasticsearch开箱即用,我和同事顺利的完成了相关任务,但是随着我深入学习elasticsearch,我发现我们写的代码存在不少问题
- elasticsearch没有配置任何mapping,使用的是默认的dynamic mapping,且没有任何设置
- 数据分片没有配置,默认只有5个分片,且副本为1,按照官网的信息,1个分片应该最多不超过50G数据,否则大分片在reindex和故障修复时会很慢,且不稳定
- 我们使用的相关elasticsearch API存在不少性能问题,在业务允许的情况下,应该优先使用filter查询
- 应该提高refresh的默认值,以提升写入速度
- ... 很多很多问题
虽然我们顺利的完成了任务,但是我们的代码存在很多问题,且在数据量大的情况下,很致命。(后来已修复)
一件事情,往往有两面性,像elasticsearch开箱即用功能,非常容易上手,简单部署一下,再调用相关API,就能实现 “CRUD”,但是便利的背后却是一大堆问题,如果你不深入学习elasticsearch,包括它的分片、mapping、索引别名、分词器、routing、template、filter过滤器、聚合、JVM内存设置、集群、冷热数据、副本、kibana、logstash等等。即使现在你的代码没有任何问题,能够运行,将来在某个时刻,你一定会为你的行为买单!
因此,对于这些“重量级知识”,我建议你一定要深入学习,并且长时间积累,形成体系。并把一些重要的知识点和坑记录下来,以免忘记。
就拿我学习elasticsearch而言,因为我们项目严重依赖elasticsearch,且数据量不少,因此过年期间我专注于elasticsearch。且后续不断积累相关知识,我的学习步骤如下
首先看官方文档,且在学习的过程中,一直穿插着在看官方文档 ,由于elasticsearch知识点很多,官网的文档也非常多,刚开始学习的时候,仅仅看官网文档,进展很慢,因为一些elasticsearch术语、行话不是很了解,所以是一边看视频、博客、公众号、一边看官方文档。
- 看完极客时间 阮一鸣老师 “Elasticsearch核心技术与实战”(因为当时刚好出了这门课程),但是这门主要讲解如何使用,相关api讲解较多
- 看完中华石杉 ES-顶尖高手 基础篇和高手进阶篇,这门课程讲解了很多elasticsearch底层原理,受益匪浅
- 看完https://blog.csdn.net/laoyang360/ 铭毅天下所有关于elasticsearch的博客,大约有130篇左右
- 看完 铭毅天下的公众号 所有关于elasticsearch的文章
- 看了很多铭毅天下知识星球上的帖子
如果你想要深入学习elasticsearch,我强烈推荐你去看 铭毅天下的博客、公众号、知识星球。 这个博主专注于elasticsearch领域,且已经通过了elasticsearch官方认证工程师。 百度搜索 “铭毅天下” 即可
至此,我的elasticsearch相关领域的知识,已经从最初的简单使用 api 到现在 已深入理解elasticsearch相关核心知识。
我在学习elasticsearch的过程中,不断积累相关重点知识和坑,并形成一定知识体系,方便我后期查阅。


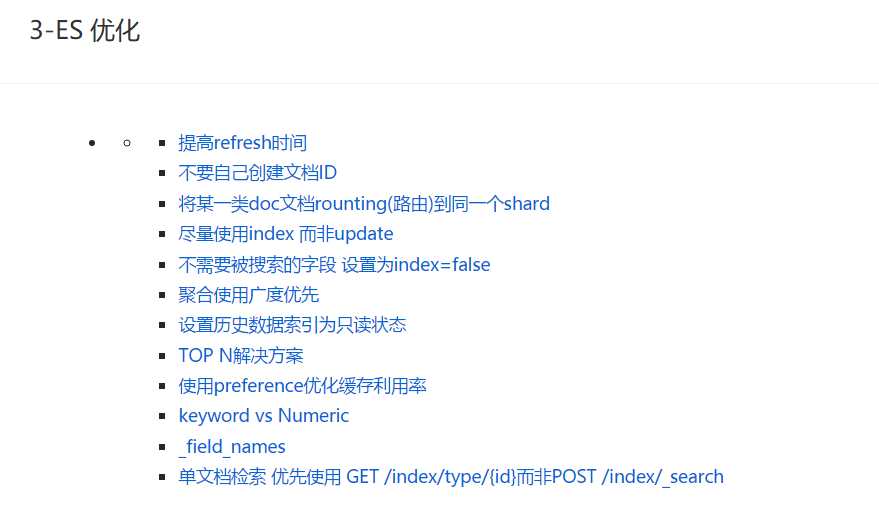

我建议你最好也将相关知识记录下来,最后形成一定体系。
轻量级知识
这里的“轻量级知识”是指难度较低,且深度较浅,并容易掌握的知识。类似于druid数据库连接池、easyExcel等等
就拿我学习easyExcel举例。以前处理excel相关数据的时候,使用的都是poi,但是最近发现同事在使用easyExcel,这引起了我的好奇心,到网上查阅相关资料,发现easyExcel相比poi、jxl有不少优点,且有完善的中文文档和社区(其实就是qq群和钉钉群,有问题可以到群里面提问),于是我也尝试使用easyExcel来处理excel相关数据。
第一步: 我到github easyExcel首页,读完整个readMe.md 文档(全是中文),建议你一定要读完,以免错过重要信息。
第二步: 通过文档信息,我知道easyExcel是个maven工程,并且有着完善的单元测试,我随即clone()最新的代码到本地
第三步: 通过文档信息,找到核心单元测试 ReadTest、WriteTest,并跑完这两个类所有的测试方法
第四步: 读取docs目录下相关easyExcel相关信息
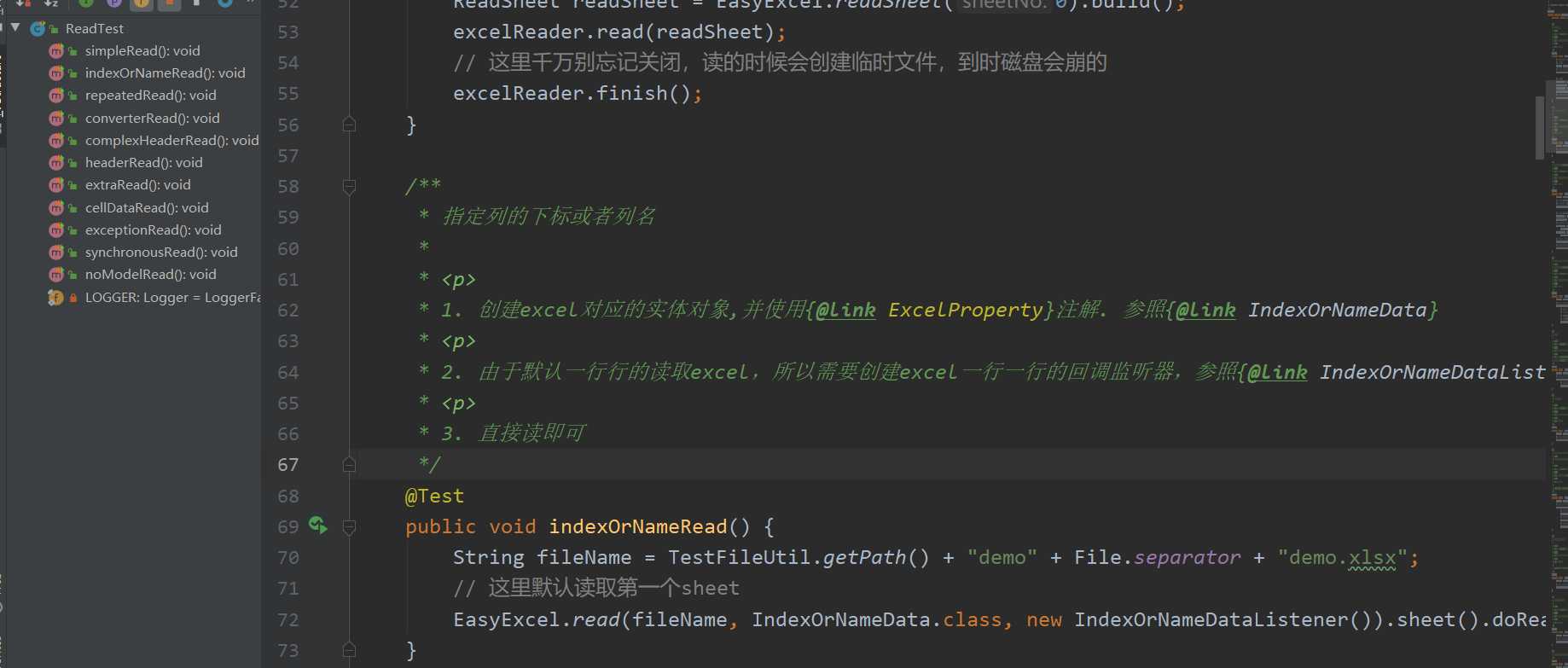
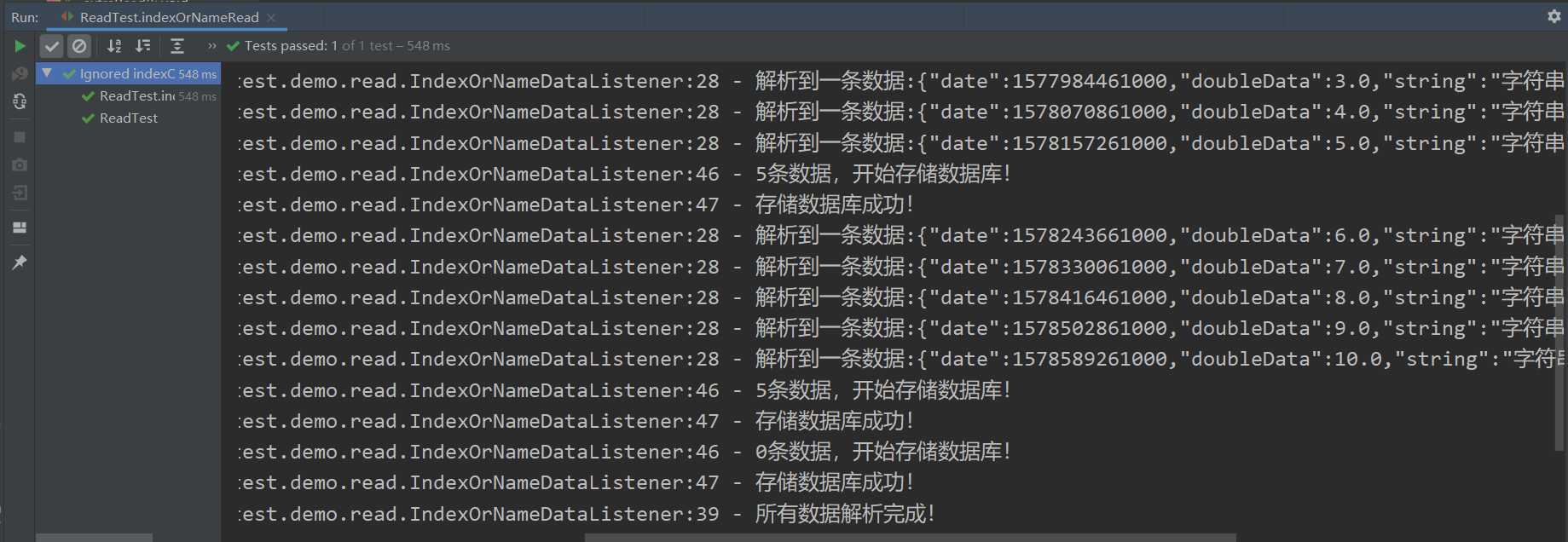
这里不得不提一下,easyExcel的单元测试用例,写的非常好,并且很完善,基本上所有和excel相关的处理,你基本上都可以找到相关的测试用例代码。每一个单元测试,你都可以成功运行,且还有代码注释和实际的控制台输出,如果你想深入了解底层逻辑,还可以debug代码。
每一个测试用例都有详细的注释:
每一个测试用例都有详细的输出:
通过easyExcel的单元测试用例,仅仅一个下午的时间,我就完全掌握了easyExcel处理excel相关的方法。
对于这类“轻量级知识”,通过官方文档信息和单元测试用例来学习,真的非常省时省力。如果你是通过博客或百度查阅一个个知识点,真的很花时间,且资料很可能已经过时。
以上是关于一门新技术或者开源项目我是如何从头开始学习的主要内容,如果未能解决你的问题,请参考以下文章