victoriametrics 集群架构
Posted rongfengliang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了victoriametrics 集群架构相关的知识,希望对你有一定的参考价值。
victoriametrics 支持基于模式,同时拆分出了三大组件,vminsert,vmselect,vmstorage
参考图
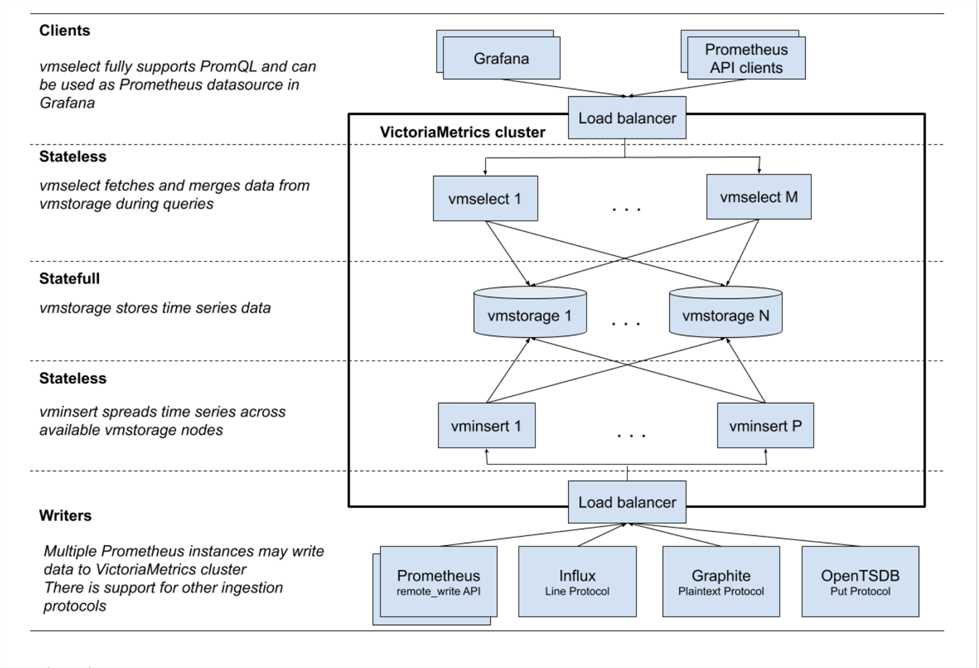
从这张图我们可以看到insert 以及select 都是无状态的,只有vmstorage,对于insert 以及select 的扩展很简单,主要是vmstorage
配置说明
官方实际上已经提供了一个简单的基于docker-compose 以及k8s部署的集群(按照三大组件部署),同时文档也有说明扩展的处理,以
下是一个简单的说明
- 参考docker-compose 内容
参考:https://github.com/VictoriaMetrics/VictoriaMetrics/blob/cluster/deployment/docker
version: ‘3.5‘
services:
prometheus:
container_name: prometheus
image: prom/prometheus:v2.17.2
depends_on:
- "vminsert"
- "vmselect"
ports:
- 9090:9090
volumes:
- promdata:/prometheus
- ./prometheus.yml:/etc/prometheus/prometheus.yml
command:
- ‘--config.file=/etc/prometheus/prometheus.yml‘
- ‘--storage.tsdb.path=/prometheus‘
restart: always
?
grafana:
container_name: grafana
image: grafana/grafana:6.7.2
entrypoint: >
/bin/sh -c "
cd /var/lib/grafana &&
mkdir -p dashboards &&
sed ‘s/$${DS_PROMETHEUS}/Prometheus/g‘ vm.json > dashboards/vm.json &&
/run.sh"
depends_on:
- "prometheus"
ports:
- 3000:3000
restart: always
volumes:
- grafanadata:/var/lib/grafana
- ./provisioning/:/etc/grafana/provisioning/
- ./../../dashboards/victoriametrics.json:/var/lib/grafana/vm.json
?
vmstorage:
container_name: vmstorage
image: victoriametrics/vmstorage
ports:
- 8482
- 8400
- 8401
volumes:
- strgdata:/storage
command:
- ‘--storageDataPath=/storage‘
restart: always
?
vminsert:
container_name: vminsert
image: victoriametrics/vminsert
depends_on:
- "vmstorage"
command:
- ‘--storageNode=vmstorage:8400‘
ports:
- 8480
restart: always
?
vmselect:
container_name: vmselect
image: victoriametrics/vmselect
depends_on:
- "vmstorage"
command:
- ‘--storageNode=vmstorage:8401‘
ports:
- 8481:8481
restart: always
?
volumes:
promdata: {}
strgdata: {}
grafanadata: {}
集群扩展说明
从上图我们可以看出对于无状态的部分我们可以基于lb提高负载能力(promxy以及trickster,nginx,haproxy 都是不错的选择)
- lb 配置:
请求以 /insert 路由到vminsert的8480
请求以 /select 路由到vmselect的8481
- 集群缩放:
* vminsert&&vmselect添加新节点即可
* vmstorage 添加:启动新的vmstorage,平滑重启vmselect注意需要添加-storageNode 参数,信息为:<new_vmstorage_host>:8401, 平滑重启vminsert
注意需要添加-storageNode 参数,信息为:<new_vmstorage_host>:8401
核心:注意顺序启动新vmstorage,平滑重启vmselect ,平滑重启vminsert
集群可用性
- http lb 必须不能路由信息到不可用的vminsert&&vmselect节点(健康检查机制可以解决)
- 集群必须至少存在一个vmstorage
vminsert 重路由请求从不可用vmstorage节点到健康节点
vmselect 持续处理请求服务到至少一个可用的vmstorage节点
集群更新以及重新配置
vminsert&&vmstorage&&vmselect可以通过平滑的更新变动
容量规划
vminsert:
- vminsert可以根据摄取率计算所有实例的建议vCPU内核总数vCPUs = ingestion_rate / 150K。
- 每个vminsert实例的建议vCPU核心数应等于vmstorage集群中的实例数。
- 每个vminsert实例的RAM量应为1GB或更多。RAM用作摄取率峰值的缓冲区。
- 有时-rpc.disableCompression,vminsert实例上的命令行标志可能以vminsert和之间更高的网络带宽使用为代价来增加摄取容量vmstorage。
vmstorage:
- vmstorage可以根据摄取率计算所有实例的建议vCPU内核总数vCPUs = ingestion_rate / 150K。
- vmstorage可以从活动时间序列数中计算所有实例的建议RAM总量:RAM = active_time_series * 1KB。如果时间序列在最后一个小时内至少收到一个数据点,或者在最后一个小时内已被查询过,则该时间序列处于活动状态。
- 所有vmstorage实例的建议存储空间总量可以根据摄取率和保留率来计算:storage_space = ingestion_rate * retention_seconds。
vmselect:
- vmselect实例的推荐硬件在很大程度上取决于查询的类型。少量时间序列上的轻量级查询通常需要使用较少的vCPU内核和较少的RAM
- vmselect,而大量时间序列上的重量查询(> 10K)通常需要使用较多的vCPU内核和大量的RAM。
灾备处理
victoriametrics提供了一些数据备份的方法vmbackup&&vmrestore 都是一些工具
- 备份方法
* /snapshot/create 请求创建快照
* <-storageDataPath>/snapshots/<snapshot_name> 目录文档使用vmbackup进行归档
* /snapshot/delete?snapshot=<snapshot_name> 或者 /snapshot/delete_all 删除快照清理部分空间
- 数据恢复
* 使用 kill -INT 停止vmstorage
* 使用vmrestore 恢复数据到-storageDataPath目录
* 启动vmstorage节点
说明
以上是对于victoriametrics 集群模式的一个简单说明,实际使用还是有好多地方需要踩坑的,总的来说victoriametrics 是一个简单但是高效的
prometheus 方案
以上是关于victoriametrics 集群架构的主要内容,如果未能解决你的问题,请参考以下文章
基于VictoriaMetrics的prometheus 集群监控报警方案
基于VictoriaMetrics的prometheus 集群监控报警方案