爬取图片
Posted wsr0414
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬取图片相关的知识,希望对你有一定的参考价值。
学习了爬虫后尝试爬取网页文字内容,掌握后开始爬取图片内容
我爬取的网页是所有人的童年:www.4399.com

我先爬取了文字内容,是成功的。之后我开始尝试爬取图片
import requests
import os
import os
url="http://4399.com"
root = "D://123456789"
root = "D://123456789"
path=root + url.split(‘/‘)[-1]
try:
if not os.path.exists(root) :
os.mkdir (root)
if not os.path.exists(root) :
os.mkdir (root)
if not os.path.exists(path) :
r = requests .get (url)
with open (path,‘wb‘) as f:
f.write (r. content)
f.close ()
print("文件保存成功")
r = requests .get (url)
with open (path,‘wb‘) as f:
f.write (r. content)
f.close ()
print("文件保存成功")
else:
print("文件不存在")
print("文件不存在")
except :
print("爬取失败")
print("爬取失败")
之后结果是
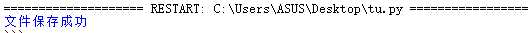
我兴奋的去找生成的图片决定大饱眼福

不是我熟悉的png 或者jpg,不重要了打开看看
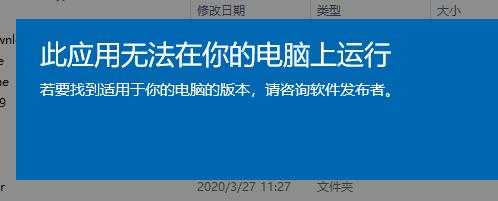
有些尴尬。。。
我打开文件属性
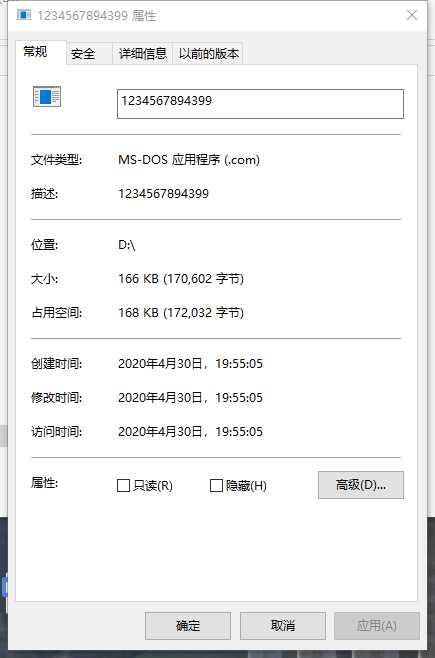
也算是一半的成功吧
朋友们,你们知道这是神马情况吗,求教大佬们
以上是关于爬取图片的主要内容,如果未能解决你的问题,请参考以下文章