全卷积目标检测:FCOS
Posted wujianming-110117
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了全卷积目标检测:FCOS相关的知识,希望对你有一定的参考价值。
全卷积目标检测:FCOS
FCOS: Fully Convolutional One-Stage Object Detection
原文链接:https://arxiv.org/abs/1904.01355
代码链接:https://github.com/tianzhi0549/FCOS/
摘要
本文提出了一种完全卷积的一级目标检测器(FCOS),以模拟语义分割,以逐像素预测的方式解决目标检测问题。几乎所有最先进的目标探测器,如RetinaNet、SSD、YOLOv3和更快的R-CNN,都依赖于预定义的锚定盒。提出的探测器FCOS是锚箱自由,通过消除预先定义的锚箱集合,FCOS完全避免了训练过程中锚箱计算重叠等与锚箱相关的复杂计算。更重要的是,还避免了与锚箱相关的所有超参数,这些参数通常对最终的检测性能非常敏感。ResNeXt-64x4d-101的FCOS在单模型单尺度的AP中,仅采用后处理非最大抑制(NMS),就达到了44.7%,大大超过了以往的单级检测器,具有简单的优点。首次展示了一种更简单灵活的检测框架,以提高检测精度。希望所提出的FCOS框架可以作为许多其他实例级任务的简单而强大的替代方案。
算法流程
本文贡献
1. 现在,检测已与许多其他FCN可解决的任务(如语义分割)统一在一起,使重用这些任务中的思想变得更加容易。
2. 检测变得无提议(proposal)且无锚(anchor),这大大减少了设计参数的数量。设计参数通常需要进行急速调整,并涉及许多技巧以实现良好的性能。因此新检测框架使检测器(尤其是其训练)变得相当简单。
3. 通过消除锚框,新型检测器完全避免了与锚框相关的复杂计算,例如IOU计算以及训练期间锚框与真值之间的匹配,从而加快了训练和测试的时间,并且减少了训练内存。
4. 在没有奇淫技巧的情况下一阶段检测器中获得了最先进的结果。还表明,提出的FCOS可以在两阶段检测器中用作区域提议网络(RPN),并且比基于锚的RPN对应项实现明显更好的性能。鉴于更简单的无锚检测器的性能更好,鼓励社区重新考虑在物体检测中使用锚框的必要性,目前,锚框被视为事实上的检测标准。
5. 提议的检测器可以立即扩展以解决其他视觉任务,而只需进行最小的修改,包括实例分割和关键点检测。这种新方法可以成为许多实例预测问题的新基准。
主要框架
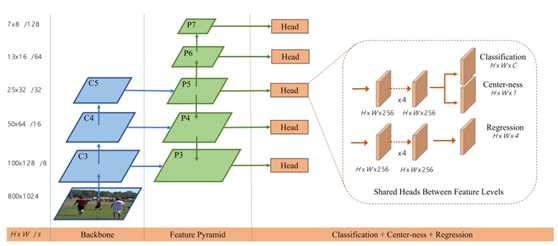
FCOS的网络体系结构,其中C3,C4和C5表示encoder的特征图,P3至P7是用于最终预测的特征。H×W是要素图的高度和宽度。“ / s”(s = 8、16,...,128)是功能图到输入图像的水平下采样率。
结论
本文提出了一种无锚和无提案的单级探测器FCOS。实验表明,FCOS与目前流行的基于锚的单级检测器(RetinaNet、YOLO和SSD)相比具有优势,但设计复杂度要低得多。FCOS完全避免了与锚定盒相关的所有计算和超参数,并以每像素预测的方式解决目标检测问题,类似于语义分割等其他密集预测任务。FCOS还实现了一级探测器的实时性能。还证明了FCOS可以作为两级检测器FasterR-CNN中的rpn,并在很大程度上优于其rpn。考虑到其有效性和效率,希望FCOS可以作为当前主流的锚定探测器的一个强大而简单的替代品。FCOS可以扩展到解决许多其他即时级别的识别任务。
1. 整个算法步骤如下,
- 步骤1. 对输入的图片进行预处理操作
- 步骤2. 搭建如图所示的网络架构,将输入数据送入backbone网络中获取输入数据的feature_map,在feature_map的每一点上面进行回归操作,进行网络训练获取网络模型
- 步骤3. 将预训练的网络模型应用到测试图片中,从特征金字塔的多个Head中获得预测的结果
- 步骤4. 使用NMS等后处理操作获得最终的结果
2. 算法细节
对于基于anchor的检测器, 会在得到的feature map的每一位置上使用预先定义好的anchors,而FCOS的改动点是对于特征图Fi上的每个位置,可以将其映射回输入图像,如果这个映射回原始输入的点在相应的真值的目标框范围之内,而且类别标签对应,将其作为训练的正样本块. 换句话说检测器直接将位置视为训练样本,而不是基于锚的检测器中的锚框,这与用于语义分割的FCN相同。接着,回归的目标是(l,t,r,b),即中心点与目标框的left、top、right和bottom之间的距离,具体如下图所示:

当然还有一种情况,就是一个location和多个box有关,作者考虑如果一个位置在多个box的内部,将其看左边一个模糊样本,针对这样样本文中采样的方法是直接选择择面积最小的边界框作为其回归目标。由于网络中FPN的存在,导致这样的模糊样本的数量大大减少.
3.损失函数
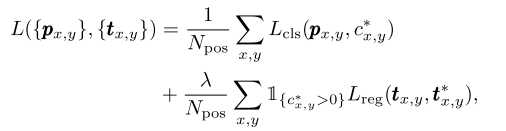
L_cls是凯明大佬提出的focal loss, L_reg是IOU损失函数,作者采用的GIOU.
4.中心度
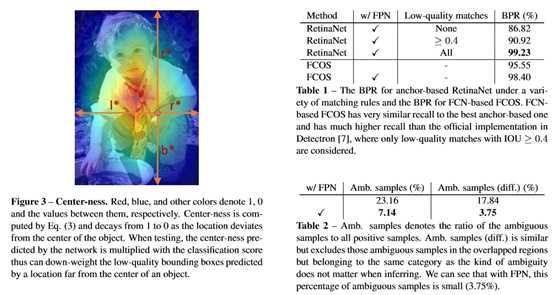
虽然使用了FPN,但是FCOS和anchor-based 的检测器还是有些差距. 即会引入一些低质量的box,即远离目标中心的检测框,而Center-ness的作用就是用来很好的抑制这些低质量的box的产生,它的优点是比较简单。不需要引入其它的超参数。它的位置是在Head网络的分类网络分支下面。对于给定的一个位置的回归目标的l、t、r、b而言,center-ness目标的定义如下所示:
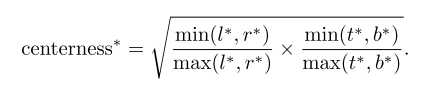
实验主要结果
1.消融实验
1.1 子模块对比
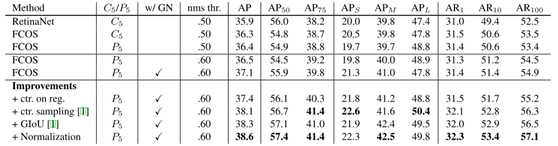
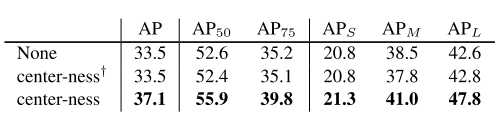
是否使用中心度的FCOS在COCO2014上的结果
1.2 SOTA算法对比
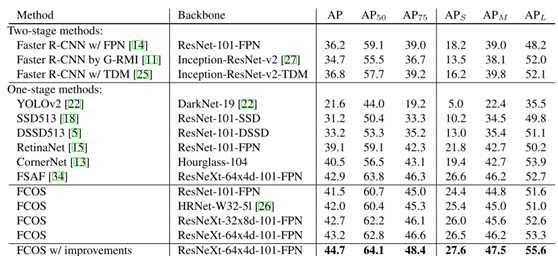
FCOS与其他最先进的两阶段或一阶段检测器(单模型和单标度结果)相比。在具有相同backbone的AP中,FCOS优于基于锚的同类RetinaNet 2.4%MAP。FCOS还以更低的设计复杂度胜过了最新的无锚点单阶段探测器CornerNet
的实验是在大规模检测基准COCO上进行的[16]。按照常规做法[15,14,24],使用COCO trainval35k分割(115Kimages)进行训练和minival分割(5Kimages)作为消融研究的验证。通过将检测结果上传到评估服务器,将主要结果报告给测试开发人员分割(20K个图像)。

Conclusion
中心-nessvs.IoUNet:
蒋等人的中心和观点。“获取精确目标检测的定位证据”与不同的方法有着相似的目的(即抑制低质量预测)。IoUNet训练一个单独的网络来预测预测边界框和地面真值框之间的IoU分数。中心度作为探测器的一部分,只有一层,与检测联合训练,因此简单得多。此外,“中心度”不作为预测边界框的输入。相反,它直接访问位置预测高质量边界框的能力。
BPR和歧义分析:
不打算将“按特定IoU召回”与“按框内像素召回”进行比较。表1的主要目的是表明FCOS的召回上界与锚定视网膜的召回上界非常接近(98.4%对99.23%)。其他IoU阈值的BPR列为视网膜网官方代码中使用的阈值。此外,没有证据表明,fcos的回归目标很难训练,因为它们更分散。FCOS实际上产生了更精确的边界框。在训练过程中,通过选择最小面积的地面真值盒来处理同一FPN水平上的模糊问题。测试时,如果同一类的两个对象A和B有重叠,无论重叠中的位置预测的是哪一个对象,预测都是正确的,漏掉的预测只能由属于它的位置来预测。在A和B不属于同一类的情况下,重叠中的一个位置可能会预测A的类,但会回归B的边界框,这是一个错误。这就是为什么只计算不同类之间的模糊性。此外,如表8所示,这种模糊性似乎不会使FCOS比AP中的RetinaNet更糟。
附加融合研究:
如表8所示,香草型FCOS的性能与RetinaNet相当,设计简单,网络输出少9×9。此外,FCOS比单锚的RetinaNet更有效。对于testdev上的2%增益,除了表8中的组件带来的性能增益外,推测不同的训练细节(例如,学习率计划)可能会导致性能的轻微差异。
中心性视网膜网:
中心度不能在每个位置有多个锚定框的视网膜网络中直接使用,因为特征地图上的一个位置只有一个中心度得分,但不同锚定框的位置要求不同的“中心度”(注意,中心度对于正/负样本来说是“软”阈值)。对于基于锚的RetinaNet,锚箱和地面真值箱之间的IoU分数可以作为“中心度”的替代。
正样本与视网膜网重叠:
想强调的是,中心性只在测试时起作用。训练时,地面真相框中的所有位置都标记为正边界框。
以上是关于全卷积目标检测:FCOS的主要内容,如果未能解决你的问题,请参考以下文章