图解数据库事务的隔离级别
Posted for-easy-fast
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图解数据库事务的隔离级别相关的知识,希望对你有一定的参考价值。
前言
乐观锁和悲观锁 与 数据库的隔离级别的关系 或者两者使用的场景是什么?
我在网上所能找到的答案,帮助个人的理解。
答案一:事务隔离级别是并发控制的整体解决方案,其实际上是综合利用各种类型的锁和行版本控制,来解决并发问题。锁是数据库并发控制的内部机制,是基础。对用户来说,只有当事务隔离级别无法解决一些并发问题和需求时,才有必要在语句中手动设置锁。
那么事务隔离级别无法解决哪些并发问题呢?
先来看看事务的隔离级别:
事务隔离级别
为了解决多个事务并发会引发的问题,进行并发控制。数据库系统提供了四种事务隔离级别供用户选择。
-
Read Uncommitted 读未提交:不允许第一类更新丢失。允许脏读,不隔离事务。
-
Read Committed 读已提交:不允许脏读,允许不可重复读。
-
Repeatable Read 可重复读:不允许不可重复读。但可能出现幻读。
-
Serializable 串行化:所有的增删改查串行执行。
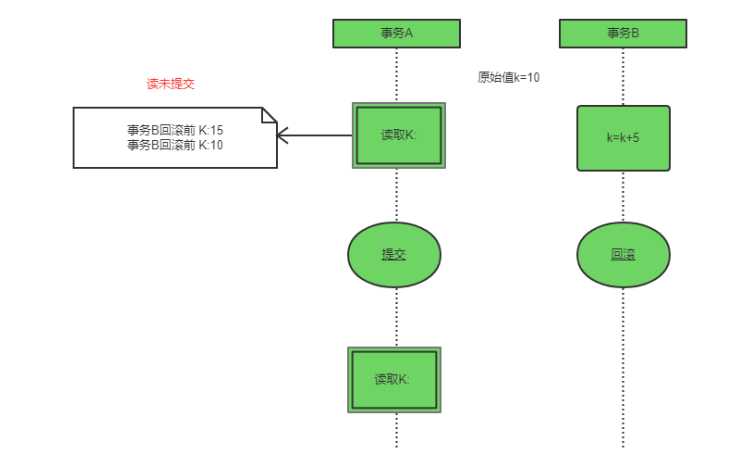
读未提交
事务读不阻塞其他事务读和写,事务写阻塞其他事务写但不阻塞读。 可以通过写操作加“持续-X锁”实现。
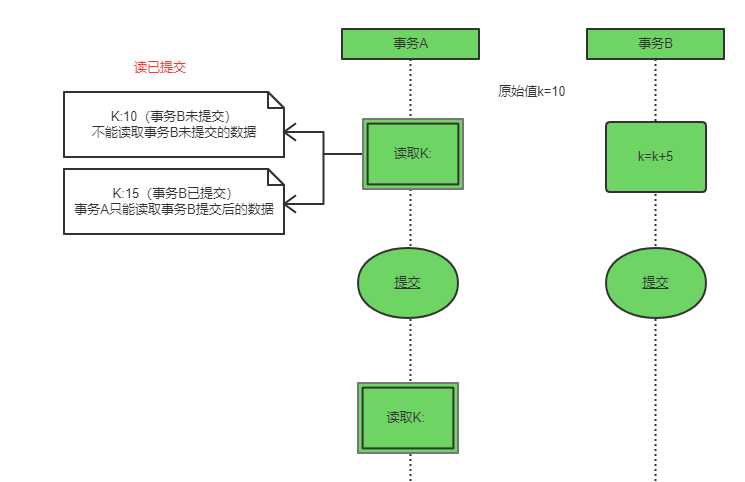
读已提交
事务读不会阻塞其他事务读和写,事务写会阻塞其他事务读和写。 可以通过写操作加“持续-X”锁,读操作加“临时-S锁”实现。
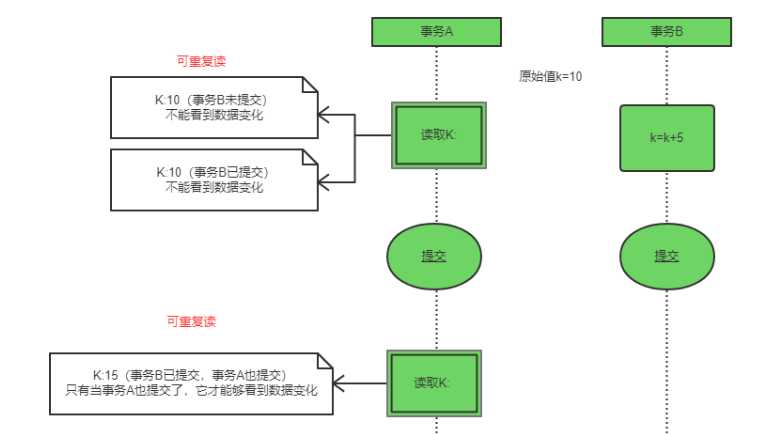
可重复读
事务读会阻塞其他事务事务写但不阻塞读,事务写会阻塞其他事务读和写。 可以通过写操作加“持续-X”锁,读操作加“持续-S锁”实现。
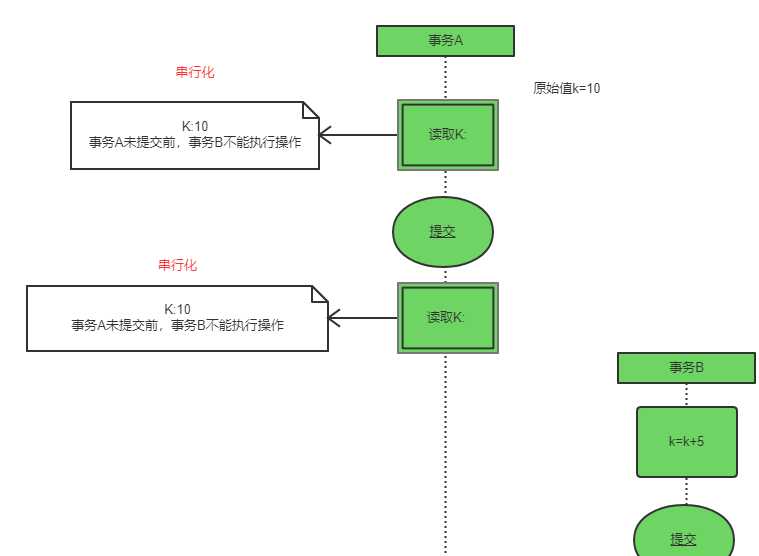
串行化
“行级锁”做不到,需使用“表级锁”。
可串行化
如果一个并行调度的结果等价于某一个串行调度的结果,那么这个并行调度是可串行化的。
区分事务隔离级别是为了解决脏读、不可重复读和幻读三个问题的。
| 事务隔离级别 | 回滚覆盖 | 脏读 | 不可重复读 | 提交覆盖 | 幻读 |
|---|---|---|---|---|---|
| 读未提交 | x | 可能发生 | 可能发生 | 可能发生 | 可能发生 |
| 读已提交 | x | x | 可能发生 | 可能发生 | 可能发生 |
| 可重复读 | x | x | x | x | 可能发生 |
| 串行化 | x | x | x | x | x |
既然事务的隔离级别可以做到这些。还需要悲观锁干什么呢?
我的理解是:(理解有错误的,请大家指正)
mysql默认使用的隔离级别是:可重复读
MSSQL默认使用的隔离级别是:读已提交
如果在MSSQL使用默认使用的隔离级别时读已提交的同事也想开发过程中想解决:不可重复读,提交覆盖和幻读等问题就可以使用悲观锁实现。
MYSQL同理。
尽管悲观锁能够防止丢失更新和不可重复读这类问题,但是它非常影响并发性能,因此应该谨慎使用。
乐观锁不能解决脏读的问题,因此仍需要数据库至少启用“读已提交”的事务隔离级别
常用的解决方案
2.悲观锁和共享锁、排它锁有是什么关系呢?
共享锁和排它锁是悲观锁的不同的实现,它俩都属于悲观锁的范畴。即悲观锁由共享锁和排它锁来实现的。
从读写角度,分共享锁(S锁,Shared Lock)和排他锁(X锁,Exclusive Lock),也叫读锁(Read Lock)和写锁(Write Lock)。理解:
持有S锁的事务只读不可写。如果事务A对数据D加上S锁后,其它事务只能对D加上S锁而不能加X锁。 ? 持有X锁的事务可读可写。如果事务A对数据D加上X锁后,其它事务不能再对D加锁,直到A对D的锁解除
注:要使用悲观锁,我们必须关闭mysql数据库的自动提交属性,因为MySQL默认使用autocommit模式,也就是说,当你执行一个更新操作后,MySQL会立刻将结果进行提交。我们可以使用命令设置MySQL为非autocommit模式:set autocommit=0;设置完autocommit后,我们就可以执行我们的正常业务了。
开始事务使用begin;/begin work;/start transaction; (三者选一就可以);
提交事务使用commit;/commit work;
两种锁的具体实现如下:
-
共享锁:悲观锁都是由数据库实现的,那共享锁在mysql中是通过什么命令来调用呢。通过在执行语句后面加上lock in share mode 就代表对某些资源加上共享锁了。
比如,我这里通过mysql打开两个查询编辑器,在其中开启一个事务,并不执行commit语句。city表DDL如下
-
CREATE TABLE `city` (
?
`id` bigint(20) NOT NULL AUTO_INCREMENT,
?
`name` varchar(255) DEFAULT NULL,
?
`state` varchar(255) DEFAULT NULL,
?
PRIMARY KEY (`id`)
?
) ENGINE=InnoDB AUTO_INCREMENT=18 DEFAULT CHARSET=utf8;

begin;
?
?
SELECT * from city where id = "1" lock in share mode;
然后在另一个查询窗口中,对id为1的数据进行更新
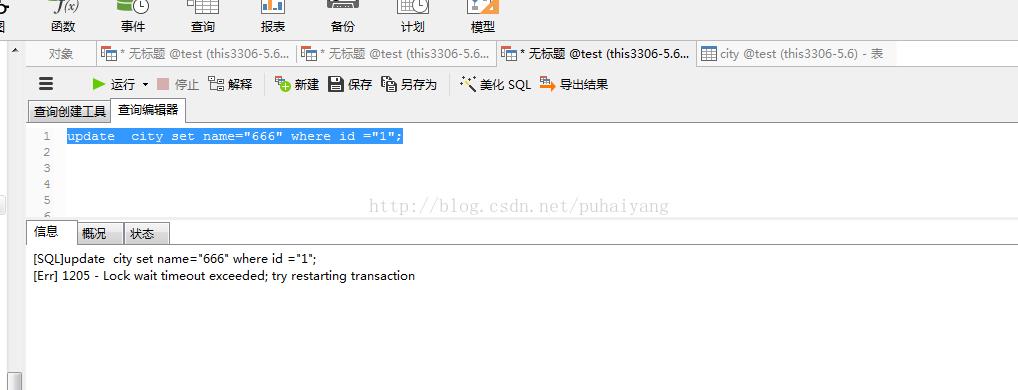
update city set name="666" where id ="1";
此时,操作界面进入了卡顿状态,过几秒后,也提示错误信息
[SQL]update city set name="666" where id ="1"; [Err] 1205 - Lock wait timeout exceeded; try restarting transaction
那么证明,对于id=1的记录加锁成功了。在上一条记录还没有commit之前,这条id=1的记录被锁住了,只有在上一个事务释放掉锁后才能进行操作,或用共享锁才能对此数据进行操作。
如果在上面一条记录加上commit;
begin;
?
?
SELECT * from city where id = "1" lock in share mode;
?
?
commit;
则 update city set name="666" where id ="1";可以执行成功!
再实验一下:

update city set name="666" where id ="1" lock in share mode;
[Err] 1064 - You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ‘lock in share mode‘ at line 1
加上共享锁后,也提示错误信息了,通过查询资料才知道,对于update,insert,delete语句会自动加排它锁的原因
于是,我又试了试SELECT * from city where id = "1" lock in share mode;
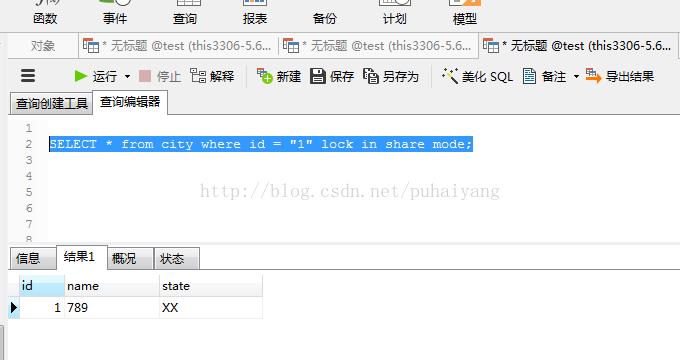
这下成功了。
-
排他锁。排它锁与共享锁相对应,就是指对于多个不同的事务,对同一个资源只能有一把锁。
与共享锁类型,在需要执行的语句后面加上for update就可以了。
排他锁的实现如下:
-
使用场景举例:以MySQL InnoDB为例
商品t_items表中有一个字段status,status为1代表商品未被下单,status为2代表商品已经被下单(此时该商品无法再次下单),那么我们对某个商品下单时必须确保该商品status为1。假设商品的id为1。 如果不采用锁,那么操作方法如下:
//1.查询出商品信息
select status from t_items where id=1;
?
//2.根据商品信息生成订单,并插入订单表 t_orders
insert into t_orders (id,goods_id) values (null,1)
?
//3.修改商品status为2
update t_items set status=2;
但是上面这种场景在高并发访问的情况下很可能会出现问题。例如当第一步操作中,查询出来的商品status为1。但是当我们执行第三步Update操作的时候,有可能出现其他人先一步对商品下单把t_items中的status修改为2了,但是我们并不知道数据已经被修改了,这样就可能造成同一个商品被下单2次,使得数据不一致。所以说这种方式是不安全的。
-
使用悲观锁来解决问题
//0.开始事务
?
begin;/begin work;/start transaction; (三者选一就可以)
?
//1.查询出商品信息
?
select status from t_items where id=1 for update;
?
//2.根据商品信息生成订单
?
insert into t_orders (id,goods_id) values (null,1);
?
//3.修改商品status为2
?
update t_items set status=2;
?
//4.提交事务
?
commit;/commit work;
上面的begin/commit为事务的开始和结束,因为在前一步我们关闭了mysql的autocommit,所以需要手动控制事务的提交。 上面的第一步我们执行了一次查询操作:select status from t_items where id=1 for update;与普通查询不一样的是,我们使用了select…for update的方式,这样就通过数据库实现了悲观锁。此时在t_items表中,id为1的那条数据就被我们锁定了,其它的事务必须等本次事务提交之后才能执行。这样我们可以保证当前的数据不会被其它事务修改(其他事务不能读也不能修改当前的数据)。需要注意的是,在事务中,只有SELECT ... FOR UPDATE 或LOCK IN SHARE MODE 操作同一个数据时才会等待其它事务结束后才执行,一般SELECT ... 则不受此影响。拿上面的实例来说,当我执行select status from t_items where id=1 for update;后。我在另外的事务中如果再次执行select status from t_items where id=1 for update;则第二个事务会一直等待第一个事务的提交,此时第二个查询处于阻塞的状态,但是如果我是在第二个事务中执行select status from t_items where id=1;则能正常查询出数据,不会受第一个事务的影响。
-
Row Lock与Table Lock
使用select…for update会把数据给锁住,不过我们需要注意一些锁的级别,MySQL InnoDB默认Row-Level Lock,所以只有「明确」地指定主键或者索引,MySQL 才会执行Row lock (只锁住被选取的数据) ,否则MySQL 将会执行Table Lock (将整个数据表单给锁住。举例如下: 1、select * from t_items where id=1 for update; 这条语句明确指定主键(id=1),并且有此数据(id=1的数据存在),则采用row lock。只锁定当前这条数据。 2、select * from t_items where id=3 for update; 这条语句明确指定主键,但是却查无此数据,此时不会产生lock(没有元数据,又去lock谁呢?)。 3、select * from t_items where name=‘手机‘ for update; 这条语句没有指定数据的主键,那么此时产生table lock,即在当前事务提交前整张数据表的所有字段将无法被查询。 4、select * from t_items where id>0 for update; 或者select * from t_items where id<>1 for update;(注:<>在SQL中表示不等于) 上述两条语句的主键都不明确,也会产生table lock。 5、select * from t_items where status=1 for update;(假设为status字段添加了索引) 这条语句明确指定了索引,并且有此数据,则产生row lock。 6、select * from t_items where status=3 for update;(假设为status字段添加了索引) 这条语句明确指定索引,但是根据索引查无此数据,也就不会产生lock。
参考的链接有:https://www.jianshu.com/p/71a79d838443
https://blog.csdn.net/puhaiyang/article/details/72284702
https://blog.csdn.net/xiaokang123456kao/article/details/75268240
https://blog.csdn.net/yinni11/article/details/81238541
感谢这四位博主做的贡献!
以上是关于图解数据库事务的隔离级别的主要内容,如果未能解决你的问题,请参考以下文章