编译基础理论
Posted strick
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了编译基础理论相关的知识,希望对你有一定的参考价值。
最近在读一本编译相关的书《两周自制脚本语言》,书中用Java来设计一种名为Stone的脚本语言。

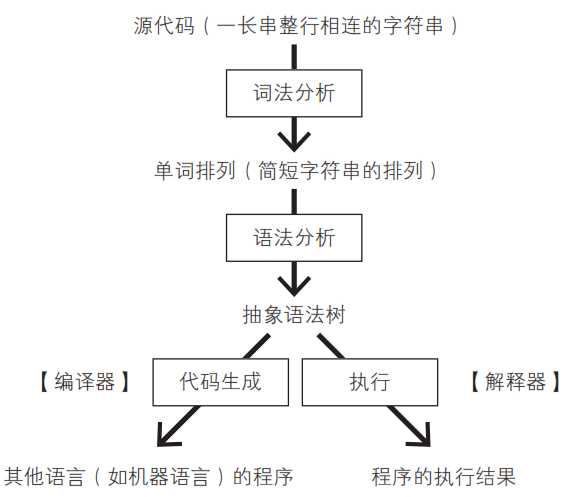
一、语言处理器的结构
在下图中,源代码首先将进行词法分析,由一长串字符串细分为多个更小的字符串单元。分割后的字符串称为单词(token)。之后处理器将执行语法分析处理,把单词的排列转换为抽象语法树。至此为止,解释器与编译器的处理方式相同。之后,编译器将会把抽象语法树转换为其他语言,而解释器将会一边分析抽象语法树一边执行运算。
二、词法分析
语言处理器的第一个组成部分是词法分析器(lexical analyzer、lexer或scanner)。程序的源代码最初只是一长串字符串。从内部来看,源代码中的换行也能用专门的(不可见)换行符表示,因此整个源代码是一种相连的长字符串。这样的长字符串很难处理,语言处理器通常会首先将字符串中的字符以单词为单位分组,切割成多个子字符串。这就是词法分析。JFlex工具可定义单词并自动生成词法分析器。
1)通过正则表达式定义单词
要设计词法分析器,首先要考虑每一种类型的单词定义,规定怎样的字符串才能构成一个单词。
Stone语言支持三种类型的单词,即标识符、整型字面量及字符串字面量。
(1)标识符(identifier)指的是变量名、函数名或类名等名称。此外,+或-等运算符及括号等标点符号也属于标识符。还有保留字也作为标识符处理。
(2)整型字面量(integer literal)指的是127或2014等字符序列。
(3)字符串字面量(string literal)是一串用于表示字符串的字符序列。双引号之间可以使用 、"与这三种类型的转义字符。它们分别表示换行符、双引号和反斜杠。
正则表达式(regular expression)是一种用于字符串模式匹配的书写记号。接下来,我们借助正则表达式来定义Stone语言的单词。
(1)首先来定义整型字面量,它比较简单。
[0-9]+
(2)然后定义标识符,最后的p{Punct}表示与任意一个标点符号字符匹配,这是Java的正则语法。模式||将会匹配||。由于|是正则表达式的元字符,因此在使用时必须在前面添加来转义。
[A-Z_a-z][A-Z_a-z0-9]*|==|<=|>=|&&||||p{Punct}
(3)最后需要定义的是字符串字面量。
"("|\\|
|[^"])*"
2)设计词法分析器
要利用这一功能设计词法分析器,首先要准备一个下面这样的正则表达式。
s*((//.*)|(pat1)|(pat2)|pat3)?
其中,pat1是与整型字面量匹配的正则表达式,pat2与字符串字面量匹配,pat3则与标识符匹配。起始的s与空字符匹配,s*与0个及0个以上的空字符匹配。模式//.*匹配由//开始的任意长度的字符串,用于匹配代码注释。于是,上述正则表达式能匹配任意个空白符以及连在其后的注释、整型字面量、字符串字面量或标识符。又因为它最后以?结尾,所以仅由任意多个空白符组成的字符串也能与该模式匹配。
执行词法分析时,语言处理器将逐行读取源代码,从各行开头起检查内容是否与该正则表达式匹配,并在检查完成后获取与正则表达式括号内的模式相匹配的字符串。
只要像这样检查一下哪一个括号对应的不是null,就能知道行首出现的是哪种类型的单词。之后再继续用正则表达式匹配剩余部分,就能得到下一个单词。不断重复该过程,词法分析器就能获得由源代码分割而得的所有单词。
3)自动机
自动机(automaton)类似于一种极为简单的计算机。它的内部包含了一个仅能记录有限类型的值的内存,在接收新的输入后,新值将由输入值与当前值共同决定,并更新至内存中。自动机不支持包括四则运算或分支运算等在内的任何其他类型的运算。自动机程序实质是一张对应关系表,根据该表,我们能由输入值及当前内存值的组合,得到需要保存至内存中的新值。
图中的自动机与正则表达式[0-9][0-9]*等价。圆圈内的数字表示自动机内存记录的当前值。圆圈(或其中的数字)称为状态。图中的箭头表示自动机在某一状态下,如果收到箭头旁标识的输入,将转换至箭头指向的状态(这一过程称为转换)。也就是说,如果圆圈内的数字是内存的当前值,且箭头旁的数字是自动机接受的输入,那么内存的值将被更新为箭头指向的圆圈内的数字。
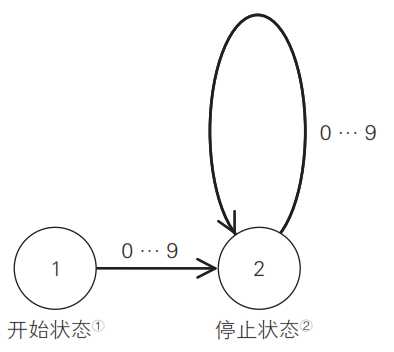
任何正则表达式都能转化为与之等价的有限状态机,也就是说自动机定能仅包含有限个圆圈。事实上,圆圈内的数字并没有特殊的含义。它们仅仅用于区分不同的圈圈。因此,有些图中的圆圈内不写数字。该图最为根本的一点在于,圆圈的数量有限(因此称为有限状态自动机)。
字符串匹配的执行将从起始状态,即图中的状态1开始。自动机将从字符串头部开始逐一输入字符,并据此改变状态,最终抵达停止状态,即图中的状态2。执行途中如果找不到符合要求的箭头就会出现错误,字符串匹配失败。
状态2是一个停止状态,其中,我们应当关注的是状态2上标有的箭头。可以看到,该自动机的状态2依然能够接受数字输入并继续执行。由于箭头从状态2出发又回到该状态,因此无论输入几次,自动机将始终处于状态2。只要输入内容是数字,自动机的执行将不断循环。
要判断正则表达式是否与整个字符串匹配,程序需要检查字符串的最后一个字符输入后,自动机是否处于停止状态。如果没有到达停止状态,或中途出错,则表示字符串与正则表达式不匹配。
下面我们再来看一个自动机的例子。这次我们尝试将一条更加复杂的正则表达式改写为自动机。
s*([0-9][0-9]*|[A-Za-z][A-Za-z0-9]*|=|==)
下图是与该正则表达式等价的自动机,它含有5种状态。其中,状态1是开始状态,其余都是停止状态。当自动机处于状态1时,它能根据输入的内容在4种模式中选择,并转换至相应的状态。如果输入的是空白符,自动机将保持状态1,直至接受到与某种模式匹配的字符。

由于模式=与==的首字符相同,因此对于这两种模式,自动机都将转换至状态4。如果下一个字符不是=,匹配将就此结束。如果自动机继续接受了一个字符=,就将转换至状态5并结束。状态5没有转换至其他状态的箭头,因此无论之后的输入是什么,匹配过程都会直接结束,不会进行判断。
三、语法分析
语言处理器在词法分析阶段将程序分割为单词后,将开始构造抽象语法树。抽象语法树(AST,Abstract Syntax Tree)是一种用于表示程序结构的树形结构。构造抽象语法树的过程称为语法分析,依然属于语言处理器的前半阶段。经过词法分析后,程序已经被分解为一个个单词。语法分析的主要任务是分析单词之间的关系,如判断哪些单词属于同一个表达式或语句,以及处理左右括号(单词)的配对等问题。语法分析的结果能够通过抽象语法树来表示。这一阶段还会检查程序中是否含有语法错误。
1)抽象语法树
用树形结构来表现语法分析的结果,即通过对象来表示程序中的语句与表达式。接下来我们试着用抽象语法树来表示下面的Stone语言程序。
13 + x * 2
只要将这个程序理解为算式13+x*2,即13与(x*2)的和即可。图下是它的对象形式表示,是一棵抽象语法树。
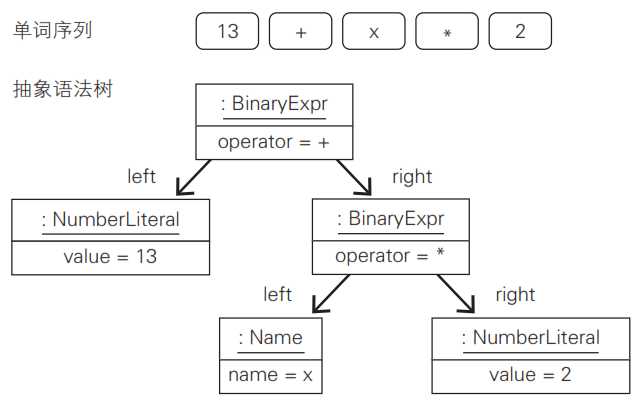
图上方的单词序列是词法分析阶段得到的结果。通过语法分析,就能得到如图所示的由对象形式表现的树形结构。图中的矩形表示对象。矩形上半部分显示的是类名。箭头表示的是字段,箭头旁边显示的文字是字段名。矩形下半部分列出的也是字段。
BinaryExpr对象用于表示双目运算表达式。双目运算指的是四则运算等一些通过左值和右值计算新值的运算。
图中含有两个BinaryExpr对象,其中一个用于表示乘法运算x*2,另一个用于表示加法运算13加x*2。加法运算的左侧是整型字面量13,它是一个NumberLiteral对象。右侧是x*2,它是另一个BinaryExpr对象。这样通过对象来表示运算符的左值与右值的方式能一目了然地显示各自表示的内容。
表达式x*2左侧的x是一个变量名,因此能用Name对象来表示。右侧的2是一个整型字面量,因此以NumberLiteral对象表示。
上图形如一棵上下颠倒的树,因此这种数据结构通常被称为树形结构。图中的矩形(对象)称为节点(node),箭头称为树枝或边。图的上方的BinaryExpr对象称为根节点。NumberLiteral对象及Name对象这类不含树枝的节点被称为叶节点。如果一个节点含有若干树枝,树枝连接的节点就是该节点的子节点,它们与该节点组成的整体称为子树。
在很多教材中,抽象语法树会用更加简洁的形式表示,如下图所示,树形结构通过箭头呈现。这种表示树形结构的方式没有限定具体的实现方式。
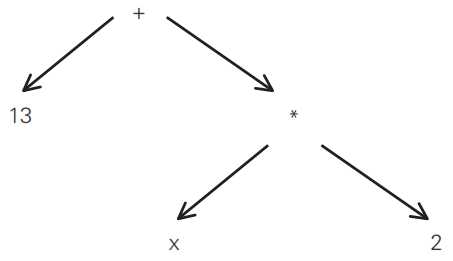
抽象语法树仅用于表示语法分析的结果,因此通过词法分析得到的单词并不一定要与抽象语法树的节点一一对应。抽象语法树是一种去除了多余信息的抽象树形结构。
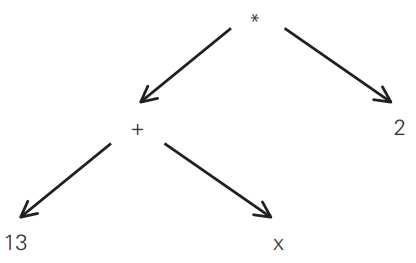
(13 + x) * 2
对这样一个表达式来说,它与之前的例子不同,包含了括号。乘法运算的左值不再是x而是13+x。一般来讲,这段程序的抽象语法树如下图所示。叶节点和中间的节点都不含括号。
2)BNF
要构造抽象语法树,语言处理器首先要知道将会接收哪些单词序列(即需要处理怎样的程序),并确定希望构造出怎样的抽象语法树。通常,这些设定由程序设计语言的语法决定。
语法规定了单词的组合规则,例如,双目运算表达式应该由哪些单词组成,或是if语句应该具有怎样的结构等。而程序设计语言的语法通常会包含诸如if语句的执行方式,或通过extends继承类时将执行哪些处理等规则。
下面的代码清单采用了一种名为BNF(Backus-NaurForm,巴科斯范式)的书写方式,这是一种用于表示上下文无关文法的语言。准确来讲,这里使用的书写方式更接近BNF的扩展版本EBNF(Extended BNF,扩展巴科斯范式)。一般都会用Yacc这类工具来生成基于BNF的语法分析器。
factor: NUMBER|"("expression")"
term: factor{("*"|"/")factor}
expression: term{("+"|"-")term}
BNF中用到的元符号如下表所示。
| {pat} | 模式pat至少重复0次 |
| [pat] | 与重复出现0次或1次的模式pat匹配 |
| pat1|pat2 | 与pat1或pat2匹配 |
| () | 将括号内视为一个完整的模式 |
乍一看,BNF与正则表达式区别很大,但两者的思维方式类似。BNF与正则表达式都用于表述某种模式,以检查序列的内容。
在BNF的表达规则中,冒号(:)左侧所写的内容能够用于表示与在冒号右侧所写的模式相匹配的单词序列。例如,第1行的规则中,factor(因子)意指与右侧模式匹配的单词序列。冒号左侧出现的诸如factor这样的符号称为非终结符或元变量。
与非终结符相对的是终结符,它们是一些事先规定好的符号,表示各种单词。在代码清单中,NUMBER这种由大写字母组成的名称,以及由双引号"括起的诸如"("的符号就是终结符。NUMBER表示任意一个整型字面量单词,"("表示一个内容为左括号的单词。
冒号右侧的模式中也包含了若干个终结符或非终结符。与正则表达式一样,模式中也能使用上表列出的那些特殊符号。
例如,在代码清单第1行的规则中,factor能表示NUMBER(1个整型字面量单词),或由左括号、expression(表达式)及右括号依次排列而成的单词序列。expression是一个非终结符,第3行对其下了定义。因此,由左括号、与expression匹配的单词序列,及右括号这些单词组成的单词序列能与factor模式匹配。
如果冒号右侧的模式中仅含有终结符,BNF与正则表达式没有什么区别。此时,两者唯一的不同仅在于具体是以单词为单位检查匹配还是以字符为单位检查。
另一方面,如果右侧含有类似于expression这样的非终结符,与该部分匹配的单词序列必须与另外定义的expression模式匹配。非终结符可以理解为常用模式的别称,在定义其他模式时能够引用这些非终结符。模式中包含非终结符是BNF的特征之一。
代码清单第2行中的term(项)表示一种由factor与运算符“*”或“/”构成的序列,其中factor至少出现一次,运算符则必须夹在两个factor之间。由于“{}”括起来的模式将至少重复出现0次,因此,第2行的规则直译过来就是:与模式term匹配的内容,或是一个与factor相匹配的单词序列,或是在一个与factor相匹配的单词序列之后,由运算符“*”或“/”以及factor构成的组合再重复若干次得到的序列。
第3行的规则也是类似。expression表示一种由term(对term对应的单词序列)与运算符“+”或“-”构成的序列,其中term至少出现一次,运算符则必须夹在两个term之间。结合所有这些规则,可以发现与模式expression匹配的就是通常的四则运算表达式,只不过单词的排列顺序做了修改。也就是说,与该模式匹配的单词序列就是一个expression。反之,如果单词序列与模式expression不匹配,则会发生语法错误(syntax error)。
那么,接下来让我们来看一个具体的例子。表达式
13 + 4 * 2
经过词法分析后将得到如下的单词序列。
NUMBER "+" NUMBER "*" NUMBER
整个单词序列与代码清单中的模式expression匹配。如下图所示,该单词序列的局部与非终结符factor及term的模式匹配,整个序列则明显与模式expression匹配。整型字面量13与factor匹配的同时也与term匹配。根据语法规则,单独的整型字面量单词能与factor匹配,单个factor又能与term匹配。
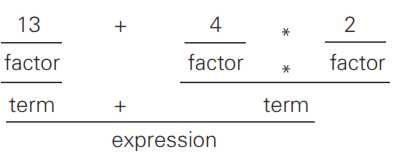
在代码清单中,expression、term与factor是范围逐层缩小的组成单位,不过需要注意的是,factor能够重新回到(由括号括起的)expression。这种具有循环结构的递归定义也是BNF的一个特征。
3)语法分析与抽象语法树
在使用BNF来表示语法之后,就能借助它们进行语法分析,并构造抽象语法树。语法分析用于查找与模式匹配的单词序列。查找得到的单词序列是一个具有特定含义的单词组。分组后的单词能继续与其他单词组一起做模式匹配,组成更大的分组。
通常,抽象语法树用于表示语法分析的结果,因此需要表现出这些分组之间的包含关系。下图是根据代码清单中的四则运算规则,对13+4*2进行语法分析后得到的结果,以及根据该结果构造的抽象语法树。图的左上方是语法分析的结果,右下方是构造的抽象语法树,正好上下颠倒。抽象语法树中的13或+等节点表示与相应单词对应的叶节点。可以看到,语法规则中出现的终结符都是抽象语法树的叶节点。非终结符term与factor也是抽象语法树的节点。
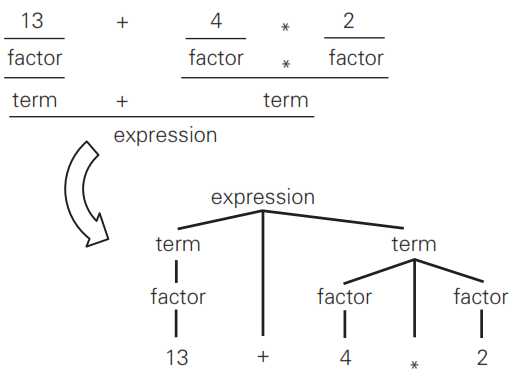
抽象语法树的子树表示的是语法分析中得到的单词组。子树是更大的树中的一部分。例如,与非终结符term模式匹配的分组能够构成一棵子树,它的根节点是表示非终结符term,与相应单词匹配的叶节点都是其子节点。右侧的term与4、*及2匹配,它们是以term为根节点的子树的叶节点。4与2同时也与模式factor匹配,因此term与4、2之间插入了一个表示factor的节点。至于13,它和term、factor通过一条直线相连,也是一棵以term为根节点、13为叶节点的符合语法规则的子树。
以上是关于编译基础理论的主要内容,如果未能解决你的问题,请参考以下文章