k8s 1.8.2部署实践
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了k8s 1.8.2部署实践相关的知识,希望对你有一定的参考价值。
由于业务需要,近期在研究k8s,故就需要先部署一套。我通过官方文档来部署发现还是有一些坑,故整理了部署中遇到的问题做个记录。本文章主要介绍了在centos7环境下k8s 1.8.2+dashboard+metrics server+ingress的部署。系统环境
1,k8s的版本为1.8.2
2,docker ce的版本为19.03.8-3
3,五台主机操作系统版本为centos7,kernel版本3.10.0-957
4,使用五台主机部署,机器列表
172.18.2.175 master1
172.18.2.180 master2
172.18.2.181 master3
172.18.2.186 work1
172.18.2.187 work2
172.18.2.182 apiserver-lb
部署HA架构
1,etcd是使用Go语言开发的一个开源的、高可用的强一致性分布式key-value存储系统,可以用于配置共享和服务的注册和发现集群,每个节点都可以提供服务。
2,kubernetes系统组件间只能通过API服务器通信,它们之间不会直接通信,API服务器是和etcd通信的唯一组件。 其他组件不会直接和etcd通信,需要通过API服务器来修改集群状态。
3,controller-manager和scheduler监听API服务器变化,如果API服务器有更新则进行对应的操作。
4,由于各个组件都需要和API服务器通信,默认情况下组件通过指定一台API服务器的ip进行通信。故需要配置API服务的高可用,我们通过单独部署一套高可用负载均衡服务,配置一个VIP,此VIP的后端是三台API服务器,在负载均衡层做转发和API服务器的监控检查,从而实现API服务的高可用。
5,默认情况下,master节点本机的组件只会和本机的API服务器或者etcd进行通信。
6,高可用master节点至少3台机器,官方建议可以根据集群大小扩容。
环境准备和kubeadm工具箱安装
1,确认每台机器的时区和时间都正确,如果不正确执行如下命令
# rm -rf /etc/localtime;ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
# /usr/sbin/ntpdate -u ntp.ubuntu.com cn.pool.ntp.org;clock -w
# echo "*/30 * * * * /usr/sbin/ntpdate -u ntp.ubuntu.com cn.pool.ntp.org;clock -w" >> /var/spool/cron/root;chmod 600 /var/spool/cron/root2,每台机器设置主机名
hostnamectl set-hostname <hostname>3,每台机器添加所有机器的主机名到ip的映射,有些服务通过主机名来相互通信,例如metrics server获取node的状态信息
# cat << EOF >> /etc/hosts
172.18.2.175 master1
172.18.2.180 master2
172.18.2.181 master3
172.18.2.186 work1
172.18.2.187 work2
EOF4,确保每台机器mac地址的唯一性
# ip addr5,确保每台机器product_uuid的唯一性
# cat /sys/class/dmi/id/product_uuid6,禁用每台机器的swap
# swapoff -a
# sed -i.bak ‘/ swap /s/^/#/‘ /etc/fstab7,由于k8s在v1.2及之后版本kube-proxy默认使用iptables来实现代理功能,而通过bridge-netfilter的设置可以使 iptables过滤bridge的流量。如果容器是连接到bridge的这种情况,那么就必须将bridge-nf-call-iptables参数设置为1,使iptables能过滤到bridge的流量,确保kube-proxy正常工作。默认情况下,iptables不过滤bridge的流量。
# lsmod | grep br_netfilter
# modprobe br_netfilter
注意:当kernel版本比较低的时候,可能出现报错找不到对应的module,可以通过升级kernel解决
# cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
# sysctl --system8,每台机器关闭firewalld防火墙和selinux
# systemctl disable --now firewalld
# setenforce 0
# sed -i ‘s/SELINUX=enforcing/SELINUX=permissive/g‘ /etc/selinux/config9,每台机器添加阿里k8s和docker的官方yum repo
# cat << EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
# yum install -y yum-utils
# yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo| 9,不同角色的机器需要开放对应端口 master节点: |
协议 | 方向 | 端口范围 | 作用 | 使用者 |
|---|---|---|---|---|---|
| TCP | 入站 | 6443 | Kubernetes API 服务器 | 所有组件 | |
| TCP | 入站 | 2379-2380 | etcd server client API | kube-apiserver, etcd | |
| TCP | 入站 | 10250 | Kubelet API | kubelet自身、控制平面组件 | |
| TCP | 入站 | 10251 | kube-scheduler | kube-scheduler自身 | |
| TCP | 入站 | 10252 | kube-controller-manager | kube-controller-manager自身 |
| work节点: |
协议 | 方向 | 端口范围 | 作用 | 使用者 |
|---|---|---|---|---|---|
| TCP | 入站 | 10250 | Kubelet API | kubelet 自身、控制平面组件 | |
| TCP | 入站 | 30000-32767 | NodePort 服务 | 所有组件 |
10,每台机器安装docker环境
# yum install docker-ce -y
# systemctl enable --now docker11,每台机器安装kubeadm,kubelet,kubectl
kubeadm:用来初始化集群的指令。
kubelet:在集群中的每个节点上用来启动pod和容器等。
kubectl:用来与集群通信的命令行工具。
# yum install -y kubelet kubeadm kubectl –disableexcludes=kubernetes
# systemctl enable --now kubelet配置HA负载均衡通过VIP方式访问API Server服务
1,创建的HA负载均衡器监听端口:6443 / TCP
2,配置其后端:172.18.2.175:6443,172.18.2.180:6443,172.18.2.181:6443
3,开启按源地址保持会话
4,配置完成之后,HA负载均衡VIP为172.18.2.182
k8s集群master节点配置
1,在master1上执行init命令
# kubeadm init --kubernetes-version 1.18.2 --image-repository registry.cn-hangzhou.aliyuncs.com/google_containers --control-plane-endpoint apiserver-lb:6443 --upload-certs
W0513 07:18:48.318511 30399 configset.go:202] WARNING: kubeadm cannot validate component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io]
[init] Using Kubernetes version: v1.18.2
[preflight] Running pre-flight checks
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/如上输出有警告信息,我们通过步骤2来解决
2,调整下docker的cgroup驱动为k8s官方建议的systemd和使用阿里云的镜像加速。由于默认docker官方镜像在国外,速度比较慢,阿里云提供了加速器,能够提高获取docker官方镜像的速度。如下修改在每台机器上进行。
# vim /etc/docker/daemon.json
{
"registry-mirrors": ["https://v16stybc.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"]
}
# systemctl daemon-reload
# systemctl restart docker
3,在master1上继续执行init命令
# kubeadm init --kubernetes-version 1.18.2 --image-repository registry.cn-hangzhou.aliyuncs.com/google_containers --control-plane-endpoint apiserver-lb:6443 --upload-certs
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of the control-plane node running the following command on each as root:
kubeadm join apiserver-lb:6443 --token i7ffha.cbp9wse6jhy4uz2q --discovery-token-ca-cert-hash sha256:1f084d1ac878308635f1dbe8676bac33fe3df6d52fa212834787a0bc71f1db6d --control-plane --certificate-key e6d08e338ee5e0178a85c01067e223d2a00b5ac0e452bca58561976cf2187dd5
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join apiserver-lb:6443 --token i7ffha.cbp9wse6jhy4uz2q --discovery-token-ca-cert-hash sha256:1f084d1ac878308635f1dbe8676bac33fe3df6d52fa212834787a0bc71f1db6d如上输出已经提供了初始化其它master和其它work节点的命令(token有过期时间,默认2h,过期则如上命令就失效,需要手动重新生成token),但是需要等master1上所有服务都就绪后才能执行,具体见接下来的步骤。
命令选项说明:
--image-repository:默认master初始化时,k8s会从k8s.gcr.io拉取容器镜像,由于国内此地址访问不到,故调整为阿里云仓库
--control-plane-endpoint: 配置VIP地址映射的域名和port
--upload-certs:将master之间的共享证书上传到集群
4,根据步骤3的输出提示在master1上执行如下命令
# mkdir -p $HOME/.kube
# cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
# chown $(id -u):$(id -g) $HOME/.kube/config使用calico做为pod之间通信用的CNI(Container Network Interface),并修改calico.yaml如下字段配置,确保calico的ipv4地址池和k8s的service cidr相同
# wget https://docs.projectcalico.org/v3.14/manifests/calico.yaml
# vim calico.yaml
- name: CALICO_IPV4POOL_CIDR
value: "10.96.0.0/12"
# kubectl apply -f calico.yaml5,过10min左右在master1上执行如下命令查看所有的pod是否都处于Running状态,然后再继续接下来的步骤
# kubectl get pods -A -o wide
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kube-system calico-kube-controllers-789f6df884-66bf8 1/1 Running 0 75s 10.97.40.67 master1 <none> <none>
kube-system calico-node-65dks 1/1 Running 0 75s 172.18.2.175 master1 <none> <none>
kube-system coredns-546565776c-wwdmq 1/1 Running 0 115s 10.97.40.65 master1 <none> <none>
kube-system coredns-546565776c-z66mm 1/1 Running 0 115s 10.97.40.66 master1 <none> <none>
kube-system etcd-master1 1/1 Running 0 116s 172.18.2.175 master1 <none> <none>
kube-system kube-apiserver-master1 1/1 Running 0 116s 172.18.2.175 master1 <none> <none>
kube-system kube-controller-manager-master1 1/1 Running 0 116s 172.18.2.175 master1 <none> <none>
kube-system kube-proxy-ghc7q 1/1 Running 0 115s 172.18.2.175 master1 <none> <none>
kube-system kube-scheduler-master1 1/1 Running 0 116s 172.18.2.175 master1 <none> <none>6,如果初始化有问题,则执行如下命令后重新初始化
# kubeadm reset
# rm -rf $HOME/.kube/config7,在master上执行验证API Server是否正常访问(需要负载均衡正确配置完成)
# curl https://apiserver-lb:6443/version -k
{
"major": "1",
"minor": "18",
"gitVersion": "v1.18.2",
"gitCommit": "52c56ce7a8272c798dbc29846288d7cd9fbae032",
"gitTreeState": "clean",
"buildDate": "2020-04-16T11:48:36Z",
"goVersion": "go1.13.9",
"compiler": "gc",
"platform": "linux/amd64"8,如果距master1初始化时间没超过2h,则在master2和master3执行如下命令,开始初始化
# kubeadm join apiserver-lb:6443 --token i7ffha.cbp9wse6jhy4uz2q --discovery-token-ca-cert-hash sha256:1f084d1ac878308635f1dbe8676bac33fe3df6d52fa212834787a0bc71f1db6d --control-plane --certificate-key e6d08e338ee5e0178a85c01067e223d2a00b5ac0e452bca58561976cf2187dd5master2和master3初始化完成之后,查看node状态:
# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master1 Ready master 3h7m v1.18.2
master2 Ready master 169m v1.18.2
master3 Ready master 118m v1.18.29,如果距master1初始化时间超过2h,token已经过期,则需要在master1上重新生成token和cert,再在master2和master3上执行初始化
在master1上重新生成token和cert:
# kubeadm init phase upload-certs --upload-certs
W0514 13:22:23.433664 656 configset.go:202] WARNING: kubeadm cannot validate component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io]
[upload-certs] Storing the certificates in Secret "kubeadm-certs" in the "kube-system" Namespace
[upload-certs] Using certificate key:
b55acff8cd105fe152c7de6e49372f9ccde71fc74bdf6ec22a08feaf9f00eba4
# kubeadm token create --print-join-command
W0514 13:22:41.748101 955 configset.go:202] WARNING: kubeadm cannot validate component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io]
kubeadm join apiserver-lb:6443 --token 1iznqy.ulvp986lej4zcace --discovery-token-ca-cert-hash sha256:1f084d1ac878308635f1dbe8676bac33fe3df6d52fa212834787a0bc71f1db6d新的初始化master2和master3的命令如下:
# kubeadm join apiserver-lb:6443 --token 1iznqy.ulvp986lej4zcace --discovery-token-ca-cert-hash sha256:1f084d1ac878308635f1dbe8676bac33fe3df6d52fa212834787a0bc71f1db6d --control-plane --certificate-key b55acff8cd105fe152c7de6e49372f9ccde71fc74bdf6ec22a08feaf9f00eba4新的初始化work节点的命令如下:
# kubeadm join apiserver-lb:6443 --token 1iznqy.ulvp986lej4zcace --discovery-token-ca-cert-hash sha256:1f084d1ac878308635f1dbe8676bac33fe3df6d52fa212834787a0bc71f1db6dk8s集群worker节点配置
1,在work1和work2机器执行如下初始化命令
# kubeadm join apiserver-lb:6443 --token 1iznqy.ulvp986lej4zcace --discovery-token-ca-cert-hash sha256:1f084d1ac878308635f1dbe8676bac33fe3df6d52fa212834787a0bc71f1db6d2,如果要重新初始化或者移除一个work节点,则执行如下步骤。
在要重新初始化的work上执行:
# kubeadm reset在master上执行:
# kubectl delete node work1
# kubectl delete node work23,在master1上执行查看master和work节点是否都正常运行
# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master1 Ready master 4h31m v1.18.2
master2 Ready master 4h13m v1.18.2
master3 Ready master 3h22m v1.18.2
work1 Ready <none> 82m v1.18.2
work2 Ready <none> 81m v1.18.2
# kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-789f6df884-vdz42 1/1 Running 1 4h37m
kube-system calico-node-429s9 1/1 Running 1 89m
kube-system calico-node-4cmwj 1/1 Running 1 4h37m
kube-system calico-node-bhw9s 1/1 Running 1 89m
kube-system calico-node-rw752 1/1 Running 1 3h29m
kube-system calico-node-xcqp8 1/1 Running 1 4h21m
kube-system coredns-546565776c-jjlsm 1/1 Running 1 4h38m
kube-system coredns-546565776c-ztglq 1/1 Running 1 4h38m
kube-system etcd-master1 1/1 Running 2 4h38m
kube-system etcd-master2 1/1 Running 2 4h20m
kube-system etcd-master3 1/1 Running 1 3h29m
kube-system kube-apiserver-master1 1/1 Running 1 4h38m
kube-system kube-apiserver-master2 1/1 Running 2 4h20m
kube-system kube-apiserver-master3 1/1 Running 1 3h29m
kube-system kube-controller-manager-master1 1/1 Running 2 4h38m
kube-system kube-controller-manager-master2 1/1 Running 1 4h20m
kube-system kube-controller-manager-master3 1/1 Running 1 3h29m
kube-system kube-proxy-5lf4b 1/1 Running 1 89m
kube-system kube-proxy-dwh7w 1/1 Running 1 4h38m
kube-system kube-proxy-nndpn 1/1 Running 1 89m
kube-system kube-proxy-spclw 1/1 Running 1 4h21m
kube-system kube-proxy-zc25r 1/1 Running 1 3h29m
kube-system kube-scheduler-master1 1/1 Running 2 4h38m
kube-system kube-scheduler-master2 1/1 Running 2 4h20m
kube-system kube-scheduler-master3 1/1 Running 1 3h29m
安装dashbaord
Dashboard可以将容器应用部署到Kubernetes集群中,也可以对容器应用排错,还能管理集群资源。您可以使用Dashboard获取运行在集群中的应用的概览信息,也可以创建或者修改Kubernetes资源(如 Deployment,Job,DaemonSet 等等)。例如,您可以对Deployment实现弹性伸缩、发起滚动升级、重启Pod或者使用向导创建新的应用。
Dashboard同时展示了Kubernetes集群中的资源状态信息和所有报错信息。
1,在master1上安装
下载manifests:
# wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.0/aio/deploy/recommended.yaml通过NodePod的方式访问dashboard
修改recommended.yaml如下内容
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
ports:
- port: 443
targetPort: 8443
selector:
k8s-app: kubernetes-dashboard
为
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
type: NodePort
ports:
- port: 443
targetPort: 8443
nodePort: 30008
selector:
k8s-app: kubernetes-dashboard部署dashboard
# kubectl apply -f recommended.yaml2,通过firefox访问(chrome和safari浏览器安全限制等级太高,对于自制的证书禁止访问,firefox可以添加例外来实现访问)此地址:https://172.18.2.175:30008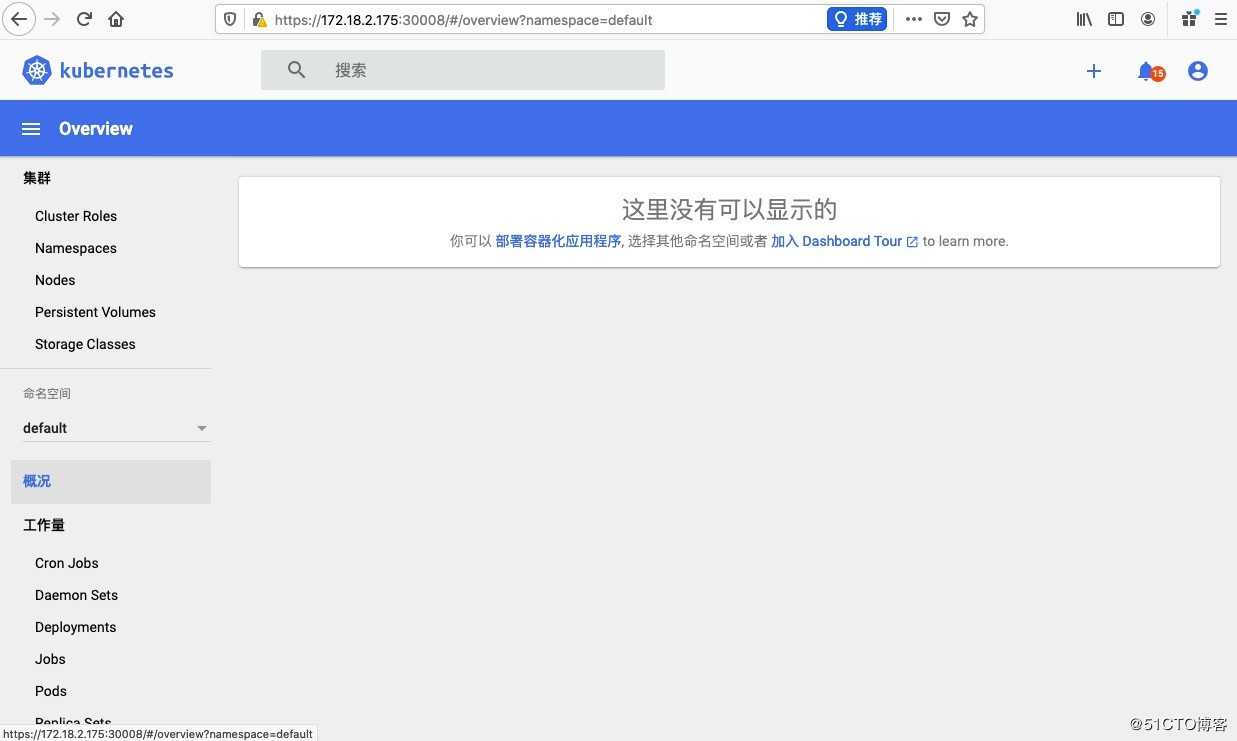
获取登陆dashboard的token
# kubectl -n kubernetes-dashboard describe secret $(kubectl -n kubernetes-dashboard get secret | grep dashboard-admin | awk ‘{print $1}‘)3,登陆之后,发现不能选择命名空间,通过查kubernetes-dashboard这个pod日志来分析原因
# # kubectl logs -f kubernetes-dashboard-7b544877d5-225rk -n kubernetes-dashboard
2020/05/14 08:21:35 Getting list of all pet sets in the cluster
2020/05/14 08:21:35 Non-critical error occurred during resource retrieval: pods is forbidden: User "system:serviceaccount:kubernetes-dashboard:kubernetes-dashboard" cannot list resource "pods" in API group "" in the namespace "default"
2020/05/14 08:21:35 Non-critical error occurred during resource retrieval: events is forbidden: User "system:serviceaccount:kubernetes-dashboard:kubernetes-dashboard" cannot list resource "events" in API group "" in the namespace "default"
2020/05/14 08:21:35 [2020-05-14T08:21:35Z] Outcoming response to 10.97.40.64:58540 with 200 status code
2020/05/14 08:21:35 Non-critical error occurred during resource retrieval: statefulsets.apps is forbidden: User "system:serviceaccount:kubernetes-dashboard:kubernetes-dashboard" cannot list resource "statefulsets" in API group "apps" in the namespace "default"
2020/05/14 08:21:35 Non-critical error occurred during resource retrieval: pods is forbidden: User "system:serviceaccount:kubernetes-dashboard:kubernetes-dashboard" cannot list resource "pods" in API group "" in the namespace "default"
2020/05/14 08:21:35 Non-critical error occurred during resource retrieval: events is forbidden: User "system:serviceaccount:kubernetes-dashboard:kubernetes-dashboard" cannot list resource "events" in API group "" in the namespace "default"通过如上日志我们可以看到dashboard没有访问其他namespace和相关资源的权限,我们通过调整rbac来解决:
# vim r.yaml
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
rules:
# Allow Metrics Scraper to get metrics from the Metrics server
- apiGroups: ["","apps","batch","extensions", "metrics.k8s.io"]
resources: ["*"]
verbs: ["get", "list", "watch"]
# kubectl apply -f r.yaml4,我们再刷新dashboard发现数据都已经正常显示了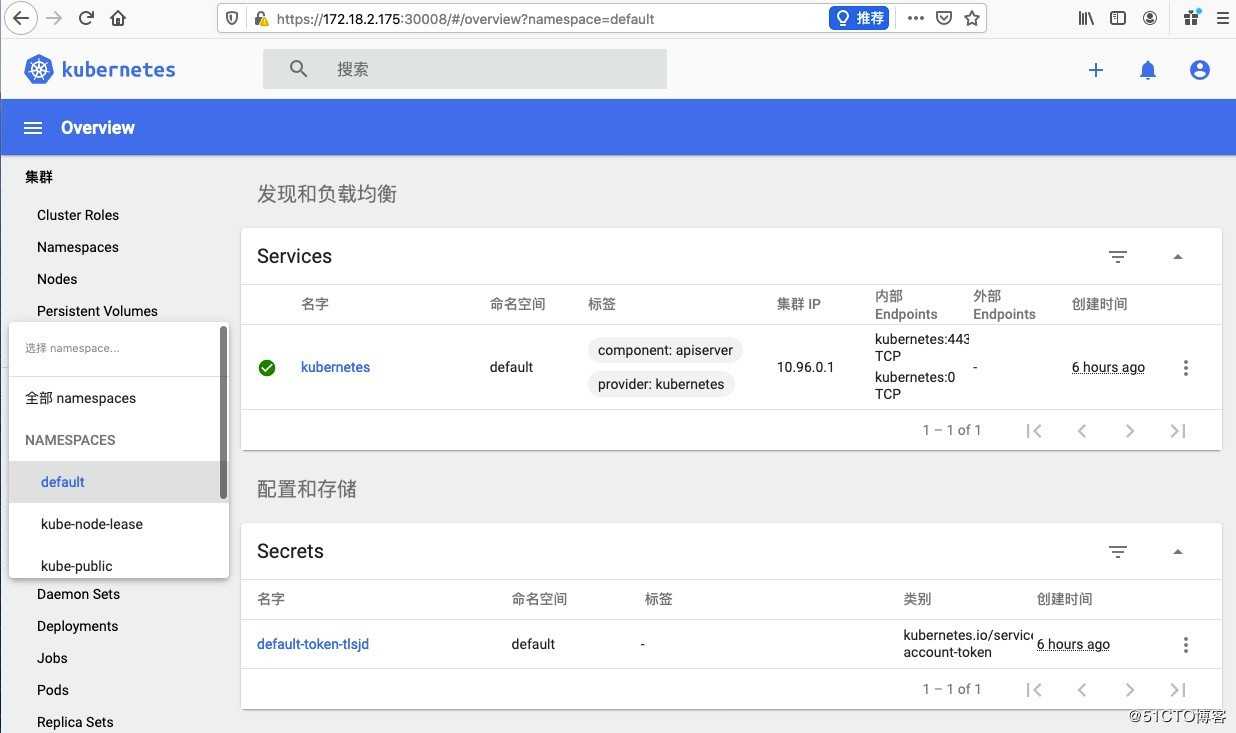
安装Metrics server
从 Kubernetes 1.8开始,官方废弃heapster项目,为了将核心资源监控作为一等公民对待,资源使用指标,例如容器 CPU 和内存使用率,可通过 Metrics API 在 Kubernetes 中获得。这些指标可以直接被用户访问,比如使用kubectl top命令行,或者这些指标由集群中的控制器使用,例如,Horizontal Pod Autoscaler,使用这些指标来做决策。主要有两部分功能:
1,Metrics API
通过Metrics API,您可以获得指定节点或pod当前使用的资源量。此API不存储指标值,因此想要获取某个指定节点10分钟前的资源使用量是不可能的。
2,Metrics Server
它集群范围资源使用数据的聚合器。 从Kubernetes 1.8开始,它作为Deployment对象,被默认部署在由kube-up.sh脚本创建的集群中。如果您使用不同的Kubernetes安装方法,则可以使用提供的deployment manifests来部署。Metric server 从每个节点上的 Kubelet 公开的 Summary API 中采集指标信息。
1,安装
下载和修改manifests文件替换国内访问不到的k8s.gcr.io地址
# wget https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.3.6/components.yaml
# sed -i ‘s#k8s.gcr.io#registry.cn-hangzhou.aliyuncs.com/google_containers#g‘ components.yaml
# kubectl apply -f components.yaml2,测试使用
确保metrics server运行
# kubectl get pods -A |grep "metrics-server"
kube-system metrics-server-68b7c54c96-nqpds 1/1 Running 0 48s获取node的cpu,内存信息,发现报错
# kubectl top nodes
error: metrics not available yet3,查看metrics-server-68b7c54c96-nqpds这个pod的日志来分析
# kubectl logs -f metrics-server-68b7c54c96-nqpds -n kube-system
E0514 11:20:58.357516 1 manager.go:111] unable to fully collect metrics: [unable to fully scrape metrics from source kubelet_summary:work2: unable to fetch metrics from Kubelet work2 (work2): Get https://work2:10250/stats/summary?only_cpu_and_memory=true: dial tcp: lookup work2 on 10.96.0.10:53: no such host, unable to fully scrape metrics from source kubelet_summary:master2: unable to fetch metrics from Kubelet master2 (master2): Get https://master2:10250/stats/summary?only_cpu_and_memory=true: dial tcp: lookup master2 on 10.96.0.10:53: no such host, unable to fully scrape metrics from source kubelet_summary:master1: unable to fetch metrics from Kubelet master1 (master1): Get https://master1:10250/stats/summary?only_cpu_and_memory=true: dial tcp: lookup master1 on 10.96.0.10:53: no such host, unable to fully scrape metrics from source kubelet_summary:work1: unable to fetch metrics from Kubelet work1 (work1): Get https://work1:10250/stats/summary?only_cpu_and_memory=true: dial tcp: lookup work1 on 10.96.0.10:53: no such host, unable to fully scrape metrics from source kubelet_summary:master3: unable to fetch metrics from Kubelet master3 (master3): Get https://master3:10250/stats/summary?only_cpu_and_memory=true: dial tcp: lookup master3 on 10.96.0.10:53: no such host]通过查看如上log,应该是dns解析的问题。k8s中使用coredns负责所有pod的dns解析,而master1,master2,master3,work1,work2是服务器的主机名不是pod的,故没有对应的解析。
4,通过google,发现解决办法有两个:
第一个办法:直接使用http方式+ip来获取node的metrics信息,缺点就是不安全,没有了https。找到componets.yaml文件中args相关的行,args修改为如下内容:
containers:
- args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-insecure-tls
- --kubelet-preferred-address-types=InternalIP
# kubectl apply -f components.yaml过几分钟,就能正常获取node的cpu,内存信息
# kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
master1 204m 10% 1189Mi 68%
master2 137m 6% 1079Mi 62%
master3 141m 7% 1085Mi 62%
work1 92m 4% 879Mi 50%
work2 94m 4% 876Mi 50%第二个办法:仍然使用https+域名的安全方式访问,对其它组件做调整。缺点就是麻烦,扩容的时候也需要考虑到这一步骤。
1)给coredns添加所有机器的主机名解析
获取目前coredns目前的配置:
# kubectl -n kube-system get configmap coredns -o yaml > coredns.yaml给coredns配置添加hosts块的配置,此配置从默认从/etc/hosts加载映射后添加到coredns的解析中:
# cat coredns.yaml
apiVersion: v1
data:
Corefile: |
.:53 {
errors
health {
lameduck 5s
}
ready
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
hosts {
172.18.2.175 master1
172.18.2.180 master2
172.18.2.181 master3
172.18.2.186 work1
172.18.2.187 work2
172.18.2.182 apiserver-lb
fallthrough
}
prometheus :9153
forward . /etc/resolv.conf
cache 30
loop
reload
loadbalance
}
kind: ConfigMap
metadata:
creationTimestamp: "2020-05-14T02:21:41Z"
managedFields:
- apiVersion: v1
fieldsType: FieldsV1
fieldsV1:
f:data:
.: {}
f:Corefile: {}
manager: kubeadm
operation: Update
time: "2020-05-14T02:21:41Z"
name: coredns
namespace: kube-system
resourceVersion: "216"
selfLink: /api/v1/namespaces/kube-system/configmaps/coredns
uid: a0e4adaa-8577-4b99-aef2-a543988a6ea8
# kubectl apply -f coredns.yaml2)查看metrics-server-68b7c54c96-d9r25这个pod的日志
# kubectl logs -f metrics-server-68b7c54c96-d9r25 -n kube-system
E0514 11:52:59.242690 1 manager.go:111] unable to fully collect metrics: [unable to fully scrape metrics from source kubelet_summary:master1: unable to fetch metrics from Kubelet master1 (master1): Get https://master1:10250/stats/summary?only_cpu_and_memory=true: x509: certificate signed by unknown authority, unable to fully scrape metrics from source kubelet_summary:master3: unable to fetch metrics from Kubelet master3 (master3): Get https://master3:10250/stats/summary?only_cpu_and_memory=true: x509: certificate signed by unknown authority, unable to fully scrape metrics from source kubelet_summary:work1: unable to fetch metrics from Kubelet work1 (work1): Get https://work1:10250/stats/summary?only_cpu_and_memory=true: x509: certificate signed by unknown authority, unable to fully scrape metrics from source kubelet_summary:work2: unable to fetch metrics from Kubelet work2 (work2): Get https://work2:10250/stats/summary?only_cpu_and_memory=true: x509: certificate signed by unknown authority, unable to fully scrape metrics from source kubelet_summary:master2: unable to fetch metrics from Kubelet master2 (master2): Get https://master2:10250/stats/summary?only_cpu_and_memory=true: x509: certificate signed by unknown authority]我们发现又有新的报错产生,看着应该是证书问题。通过google发现可能是由于master节点上kubelet的证书和node上kubelet的证书由不同的本地系统的ca签发,导致不可信。所有节点(master和node)上的证书,可以在master1上是用master1本地的CA重新生成所有节点的kubelet证书来解决。
3)重新生成master1上kubelet的证书
安装CFSSL
curl -s -L -o /bin/cfssl https://pkg.cfssl.org/R1.2/cfssl_linux-amd64
curl -s -L -o /bin/cfssljson https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64
curl -s -L -o /bin/cfssl-certinfo https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64
chmod +x /bin/cfssl*生成过期时间为2年的证书配置
# mkdir ~/mycerts; cd ~/mycerts
# cp /etc/kubernetes/pki/ca.crt ca.pem
# cp /etc/kubernetes/pki/ca.key ca-key.pem
# cat kubelet-csr.json
{
"CN": "kubernetes",
"hosts": [
"127.0.0.1",
"master1",
"kubernetes",
"kubernetes.default",
"kubernetes.default.svc",
"kubernetes.default.svc.cluster",
"kubernetes.default.svc.cluster.local"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [{
"C": "US",
"ST": "NY",
"L": "City",
"O": "Org",
"OU": "Unit"
}]
}
# cat ca-config.json
{
"signing": {
"default": {
"expiry": "17520h"
},
"profiles": {
"kubernetes": {
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
],
"expiry": "17520h"
}
}
}
}
# cat config.json
{
"signing": {
"default": {
"expiry": "168h"
},
"profiles": {
"www": {
"expiry": "17520h",
"usages": [
"signing",
"key encipherment",
"server auth"
]
},
"client": {
"expiry": "17520h",
"usages": [
"signing",
"key encipherment",
"client auth"
]
}
}
}
}
# cfssl gencert -ca=ca.pem -ca-key=ca-key.pem --config=ca-config.json -profile=kubernetes kubelet-csr.json | cfssljson -bare kubelet
# scp kubelet.pem root@master1:/var/lib/kubelet/pki/kubelet.crt
# scp kubelet-key.pem root@master1:/var/lib/kubelet/pki/kubelet.key4)在master1上为master2生成kubelet证书,只需要修改(3)步骤中kubelet-csr.json配置中master1改为master2,scp中master1为master2,然后完整执行(3)的其它步骤即可。master3,work1,work2证书的生成步骤相同。
5)重启每台机器的kubelet
# systemctl restart kubelet6)过几分钟,就能正常获取node的cpu,内存信息。并且,通过dashbaord也能显示node的cpu和内存信息了。
# kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
master1 246m 12% 1202Mi 69%
master2 152m 7% 1094Mi 62%
master3 160m 8% 1096Mi 63%
work1 97m 4% 882Mi 50%
work2 98m 4% 879Mi 50%安装Ingress
nginx ingress安装没有坑,直接按照官方文档安装即可,链接为:https://docs.nginx.com/nginx-ingress-controller/installation/installation-with-manifests/
参考文档
https://docs.docker.com/engine/install/centos/
https://kubernetes.io/zh/docs/tasks/access-application-cluster/web-ui-dashboard/
https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/install-kubeadm/
https://kubernetes.io/zh/docs/tasks/access-application-cluster/web-ui-dashboard/
https://kubernetes.io/zh/docs/tasks/debug-application-cluster/resource-metrics-pipeline/
https://coredns.io/plugins/hosts/
https://stackoverflow.com/questions/53212149/x509-certificate-signed-by-unknown-authority-kubeadm
https://docs.nginx.com/nginx-ingress-controller/installation/installation-with-manifests/
以上是关于k8s 1.8.2部署实践的主要内容,如果未能解决你的问题,请参考以下文章