Elasticsearch概念及安装
Posted wuzhenzhao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch概念及安装相关的知识,希望对你有一定的参考价值。
官网:https://www.elastic.co/cn/products/elasticsearch
Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。又以下特点
- 分布式,无需人工搭建集群(solr就需要人为配置,使用Zookeeper作为注册中心)
- Restful风格,一切API都遵循Rest原则,容易上手
- 近实时搜索,数据更新在Elasticsearch中几乎是完全同步的。
ElasticSearch 中的基本概念:
Index索引:索引是具有相似特性的文档集合。例如,可以为用户数据提供索引,为产品目录建立另一个索引,以及为订单数据建立另一个索引。索引由名称(必须全部为小写)标识,该名称用于在对其中的文档执行索引、搜索、更新和删除操作时引用索引。在单个群集中,您可以定义尽可能多的索引。
Type类型:在索引中,可以定义一个或多个类型。类型是索引的逻辑类别/分区,其语义完全取决于您。一般来说,类型定义为具有公共字段集的文档。例如,假设你运行一个博客平台,并将所有数据存储在一个索引中。在这个索引中,您可以为用户数据定义一种类型,为博客数据定义另一种类型,以及为注释数据定义另一类型。
Document文档:文档是可以被索引的信息的基本单位。例如,您可以为单个用户提供一个文档,单个产品提供另一个文档,以及单个订单提供另一个文档。本文件的表示形式为JSON(javascript Object Notation)格式,这是一种非常普遍的互联网数据交换格式。在索引/类型中,您可以存储尽可能多的文档。请注意,尽管文档物理驻留在索引中,文档实际上必须索引或分配到索引中的类型。
Shards & Replicas分片与副本:索引可以存储大量的数据,这些数据可能超过单个节点的硬件限制。例如,十亿个文件占用磁盘空间1TB的单指标可能不适合对单个节点的磁盘或可能太慢服务仅从单个节点的搜索请求。为了解决这一问题,Elasticsearch提供细分你的指标分成多个块称为分片的能力。当你创建一个索引,你可以简单地定义你想要的分片数量。每个分片本身是一个全功能的、独立的“指数”,可以托管在集群中的任何节点。Shards分片的重要性主要体现在以下两个特征:
- 分片允许您水平拆分或缩放内容的大小
- 分片允许你分配和并行操作的碎片(可能在多个节点上)从而提高性能/吞吐量
这个机制中的碎片是分布式的以及其文件汇总到搜索请求是完全由ElasticSearch管理,对用户来说是透明的。在同一个集群网络或云环境上,故障是任何时候都会出现的,拥有一个故障转移机制以防分片和结点因为某些原因离线或消失是非常有用的,并且被强烈推荐。为此,Elasticsearch允许你创建一个或多个拷贝,你的索引分片进入所谓的副本或称作复制品的分片,简称Replicas。Replicas的重要性主要体现在以下两个特征:
- 副本为分片或节点失败提供了高可用性。为此,需要注意的是,一个副本的分片不会分配在同一个节点作为原始的或主分片,副本是从主分片那里复制过来的。
- 副本允许用户扩展你的搜索量或吞吐量,因为搜索可以在所有副本上并行执行。
可能到这里您对这些概念还有点模糊,没关系,在以后的使用过程中慢慢就会有深刻的体会了。
关系型数据库和 ElasticSearch 操作姿势对比:
JDBC 操作 ElasticSearch Client 操作
- 加载驱动类(JDBC 驱动)
- 建立连接(Connection) ----------------1、建立连接(TransportClient)
- 创建语句集(Statement)----------------2、条件构造(SearchRequestBuilder)
- 执行语句集 execute() ----------------3、执行语句 execute()
- 获取结果集(ResultSet)----------------4、获取结果(SearchResponse)
- 关闭结果、语句、连接 ----------------5、关闭以上操作
ElasticSearch 集群搭建:
JDK:1.8
OS:windows
es版本:elasticsearch-6.5.1.zip,官方下载地址 https://www.elastic.co/cn/downloads/elasticsearch
但是这个版本不是最新的。我们来简单对比一下大版本的区别:
| 版本信息 | 6.X | 7.X |
| 集群连接对比 | 可使用TransportClient | 建议使用restclient TransportClient被废弃,只能使用restclient。于java编程,建议采用 High-level-rest-client 的方式操作ES集群 |
| ES数据存储结构变化 | index/type 一对一 | 建议使用_doc做type 去除了type,es7中使用默认的_doc作为type |
| 默认配置变化 | 默认节点名称为主机名,默认分片数改为5 | 默认节点名称为主机名,默认分片数改为1 |
| ES程序包默认打包jdk | Jdk需自己安装配置,需要配置官方支持的jdk版本建议在Java 8发行版系列中安装Java版本1.8.0_131或更高版本。打包大小100M+ 的捆绑版本的OpenJDK。 | 捆绑的JVM,位于Elasticsearch主目录的jdk目录中。可使用自己的Java版本,在JAVA_HOME环境配置。打包大小300M+(包含jdk) |
| 查询相关性速度优化 | 倒排索引的方式进行查询 |
倒排索引的方式进行查询+Weak-AND算法 |
| 间隔查询(Intervals queries) | 无 | 查找单词或短语彼此相距一定距离的记录 |
| 安全性功能 | 6.8有免费 | 其他无 7.0无免费 其他有免费 |
1.下载之后,直接解压即可。单机版的话运行 bin 目录下的 elasticsearch.bat 文件 。伪分布式需要进行配置,首先我们先解压三份出来,组成一主二从的局面:
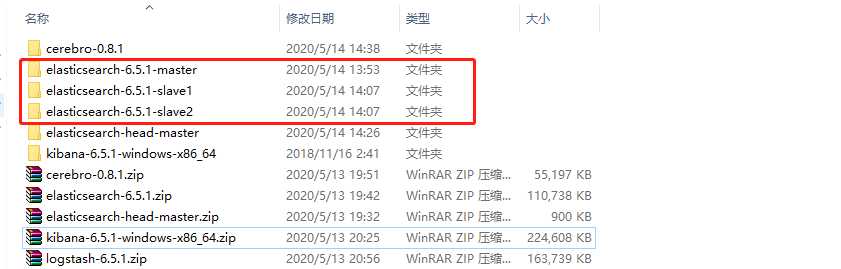
2.修改master的配置,进入安装目录中 config 下面,编辑 elasticsearch.yml
cluster.name: wuzz-cluster # 集群的名称
node.name: master # 节点ID,保证唯一
node.master: true # 是否主节点
network.host: 127.0.0.1 #对外公开的 IP 地址,如果自动识别配置为 0.0.0.0
同样配置其他两个节点的 elasticsearch.yml:
// slave-1
cluster.name: wuzz-cluster #集群名称三个节点保持一致
node.name: slave-1 #从节点 ID,保证唯一
network.host: 127.0.0.1 #对外公开的 IP 地址,如果自动识别配置为 0.0.0.0
http.port: 8200 #默认端口为 9200,因为我的环境是在同一台机器,因此,指定服务端口号
discovery.zen.ping.unicast.hosts: ["127.0.0.1"] #集群的 IP 组,配置主节点 IP 即可
// slave-2
cluster.name: wuzz-cluster #集群名称三个节点保持一致
node.name: slave-2 #从节点 ID,保证唯一
network.host: 127.0.0.1 #对外公开的 IP 地址,如果自动识别配置为 0.0.0.0
http.port: 8000 #默认端口为 9200,因为我的环境是在同一台机器,因此,指定服务端口号
discovery.zen.ping.unicast.hosts: ["127.0.0.1"] #集群的 IP 组,配置主节点 IP 即可
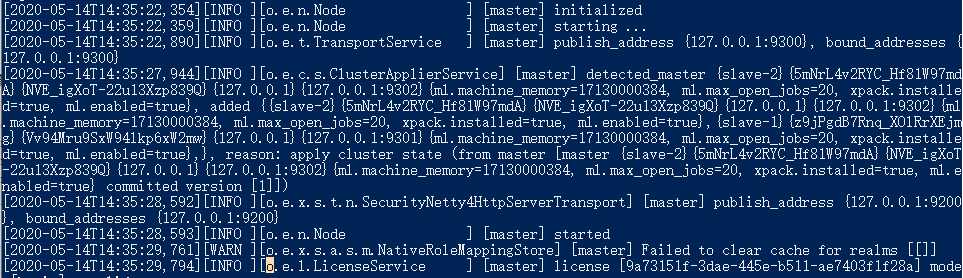
3.启动三个节点,成功的话可以看到类似这样的输出信息:
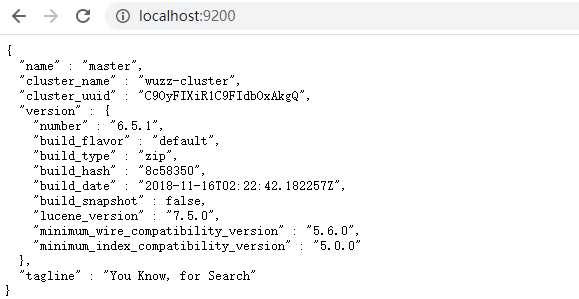
4.分别访问http://localhost:9200/,http://localhost:8200/,http://localhost:8000/,都会输出节点信息,说明配置完成:
可视化工具之 elasticsearch-head:
1.因为head是一个Node.js项目。所以,如果没有安装nodejs需要先安装Node.js,安装可以参考 https://www.cnblogs.com/wuzhenzhao/p/12672125.html
2.因为运行head需要借助grunt命令,所以需要安装grunt。进入Node.js目录下,执行命令npm install -g grunt-cli,将grunt安装位全局命令。进入head主目录执行npm install安装grunt,安装完成后执行grunt -version查看是否安装成功,会显示安装的版本号。
如果npm 不让使用,执行 set-ExecutionPolicy RemoteSigned 就好了

3.下载 https://github.com,搜索 elasticsearch-head 关键字。下载 elasticsearch-head-master.zip 包。
4..配置主节点 elasticsearch.yml
http.cors.enabled: true
http.cors.allow-origin: "*"
node.data: true
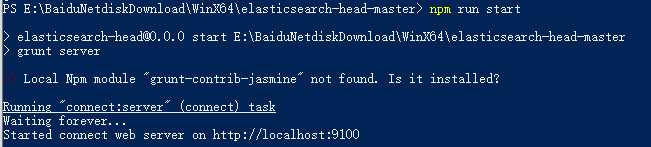
5.命令行进入head文件夹执行执行npm install 安装完成后执行grunt server 或者npm run start 运行head插件,如果不成功重新安装grunt。成功如下:
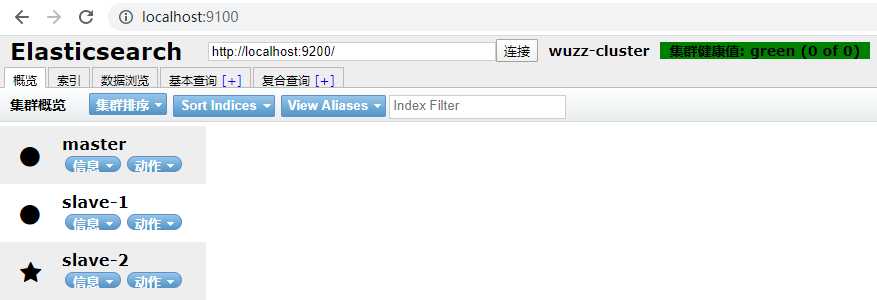
6.然后就可以通过 http://localhost:9100/ 来访问:
可视化工具之 Cerebro:
下载 https://github.com/lmenezes/cerebro/releases
下载完解压,运行成功如下图所示

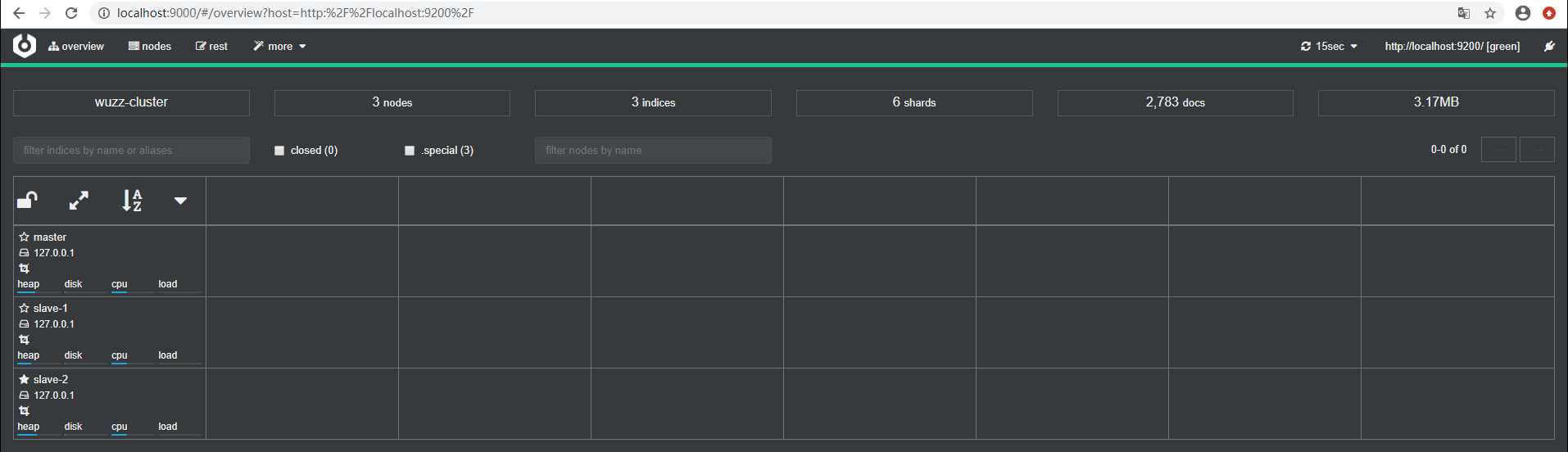
然后就可以通过 http://localhost:9000/ 进行访问:
可视化工具之 Kibana:
版本:需要与 ElasticSearch保持一致,也是6.5.1
下载 :https://www.elastic.co/cn/downloads/past-releases 下载 Kibana6.5.1
1.进行安装目录 config 下面,修改 kibana.yml (保持默认也可以)默认链接本地9200端口的es
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.url: "http://192.168.1.101:9200" #es集群主节点地址
kibana.index: ".kibana"
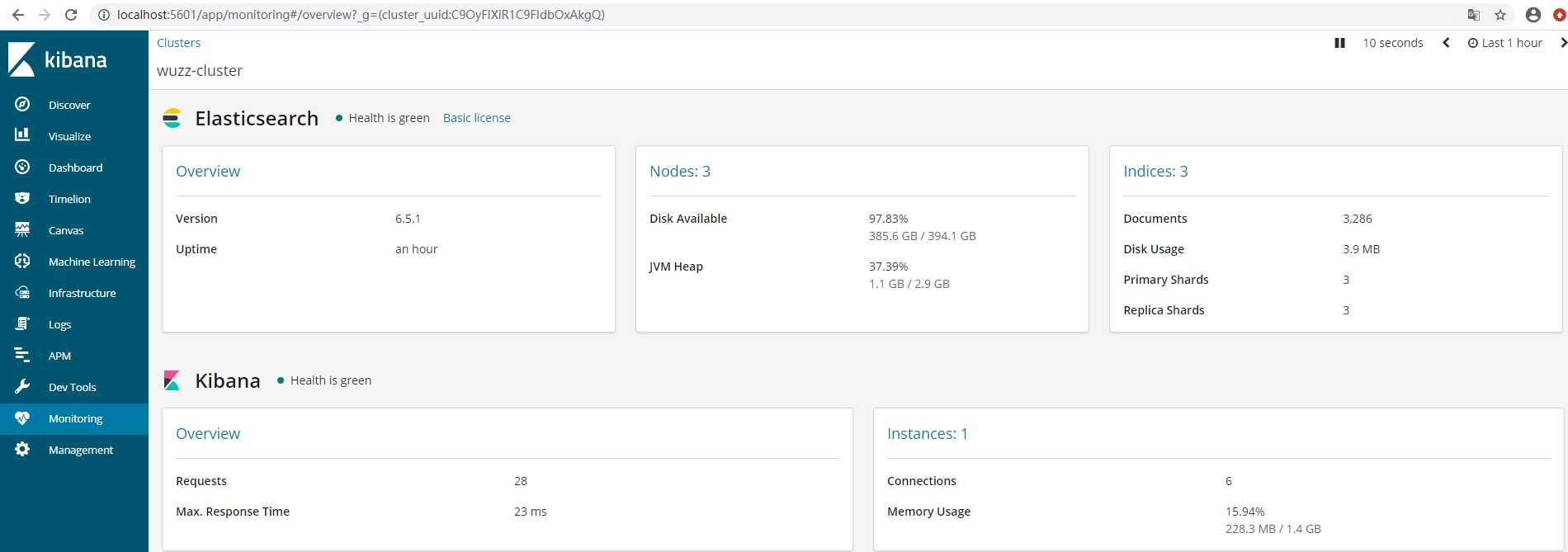
2.进入bin 启动 启动 kibana 即可,然后通过 http://localhost:5601/ 进行访问。点击 monitoring 就可以看到es集群信息:
- Discover:日志管理视图 主要进行搜索和查询
- Visualize:统计视图 构建可视化的图表
- Dashboard:仪表视图 将构建的图表组合形成图表盘
- Timelion:时间轴视图 随着时间流逝的数据
- APM:性能管理视图 应用程序的性能管理系统
- Canvas:大屏展示图
- Dev Tools: 开发者命令视图 开发工具
- Monitoring:健康视图 请求访问性能预警
- Management:管理视图 管理工具
以上是关于Elasticsearch概念及安装的主要内容,如果未能解决你的问题,请参考以下文章