Spark 数据分析调优
Posted yjyyjy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark 数据分析调优 相关的知识,希望对你有一定的参考价值。
Apache Spark Job 调优以提高性能(一)
假设你已经清楚了Spark 的 RDD 转换,Action 等内容。并且已经知道用web UI来理解为什么Job要花这么长时间时,Job、stage和task 也很清楚了。
如果不清楚可以看我的视频(。。。。)
在本文中,您将了解Spark程序在集群中实际执行的基础知识。然后,您将获得一些关于Spark执行模型对于编写高效程序的实际建议。
Spark如何执行您的程序
- Spark应用程序由单个Driver进程和一组分散在集群节点上的executer进程组成。
- Driver程序是负责需要完成的工作的高级控制流的流程。
- 执行程序进程负责以task的形式执行此工作,以及存储用户选择缓存的任何数据。
- 单个executer程序有许多插槽用于运行task,并将在其整个生命周期中并发地运行许多task。在集群上部署这些进程由集群管理器(Yarn、Mesos或独立的Spark) 完成,但是Driver和executer程序本身存在于每个Spark应用程序中。
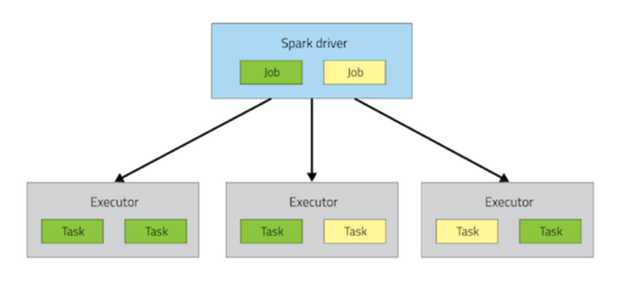
在Spark应用程序中调用一个action将触发一个Spark作业的启动来完成它。为了确定这个任务是什么样子的,Spark检查了该操作所依赖的RDDs图,并制定了一个执行计划。此计划从最后面的RDD开始(祖先)或引用已缓存数据的RDD—并最终生成生成操作结果所需的最终RDD。
执行计划包括将task的转换组装到各stage (阶段)。一个阶段对应于一组task,所有这些任务都在数据的不同子集上执行相同的代码。每个阶段都包含一系列transform,这些转换可以在不打乱完整数据的情况下完成。
是什么决定了数据是否需要重新洗牌(shuffle)? 回想一下,一个RDD包含固定数量的分区,每个分区包含若干条记录。对于所谓的窄转换(如map和filter) 返回的RDDs,计算单个分区中的记录所需的记录驻留在父RDD中的单个分区中。每个对象只依赖于父对象中的一个对象。像coalesce这样的操作可以导致一个任务处理多个输入分区,但是转换仍然被认为是窄的,因为用于计算任何单个输出记录的输入记录仍然只能驻留在分区的一个有限的子集中。
但是,Spark还支持具有广泛依赖性的转换,比如groupByKey和reduceByKey。在这些依赖项中,计算单个分区中的记录所需的数据可能驻留在父RDD的许多分区中。所有具有相同键的元组都必须位于相同的分区中,由相同的任务处理。为了满足这些操作,Spark必须执行一个shuffle,它在集群中传输数据,并导致使用一组新的分区进入一个新阶段(合并后重新分区)。
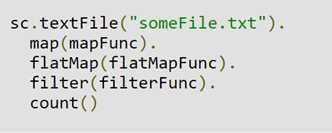
比如,以下代码不需要Shuffle: 它执行单个操作,该操作依赖于从文本文件派生的RDD上的转换序列。这段代码将在单个阶段执行,因为这三个操作的输出都不依赖于来自不同分区的数据。
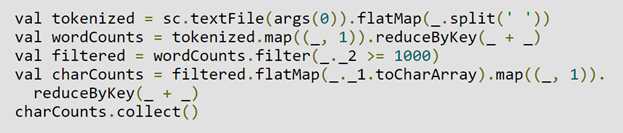
相比之下,这段代码可以找出每个字符在文本文件中出现超过1,000次的所有单词中出现的次数。这个过程可以分为三个阶段。reduceByKey操作会导致阶段边界,因为计算它们的输出需要按键对数据进行重新分区。
下面是一个更复杂的转换图,包括一个具有多个依赖项的连接转换。粉红色的方框显示用于执行它的结果阶段图。
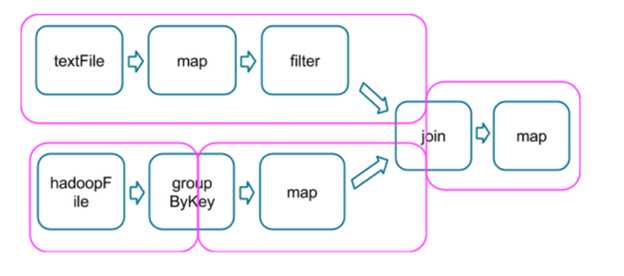
在每个阶段边界,数据由父阶段的任务写入磁盘,然后由子阶段的任务通过网络获取。因为它们会导致大量磁盘和网络I/O,所以阶段边界可能会很昂贵,应该尽可能避免。
父阶段中的数据分区数量可能与子阶段中的分区数量不同。可能触发阶段边界的转换通常接受一个numPartitions参数,该参数确定在子阶段中将数据分割为多少个分区。
正如减速器的数量是调优MapReduce作业的一个重要参数一样,在阶段边界调优分区的数量常常会影响或破坏应用程序的性能。我们将在后面的部分中更深入地研究如何调优这个数字。
调优方法
-
选择正确的操作符
当尝试使用Spark完成某些事情时,开发人员通常可以从许多操作安排和转换中进行选择,这些操作和转换将产生相同的结果。然而,并不是所有这些安排都会导致相同的性能: 避免常见的缺陷并选择正确的安排可以极大地提高应用程序的性能。当这些选择出现时,一些规则和见解将帮助你确定自己的方向。高版本中的SchemaRDD成为了一个稳定的组件,用户将不再需要做这些决定。
选择操作符排列的主要目标是减少变换的次数和数据变换的数量。这是因为改组是相当昂贵的操作;
所有洗牌数据必须写入磁盘,然后通过网络传输。重新分区、联接、cogroup和任何*By或*ByKey转换都可能导致改组。然而,并不是所有这些操作都是相同的,而且对于新手Spark开发人员来说,一些最常见的性能陷阱来自于选择错误的操作。
- 在执行关联简化操作时避免使用groupByKey
例如,rdd. groupbykey (). mapvalues (_.sum) 将产生与reduceByKey (_ + _) 相同的结果。然而,前者将通过网络传输整个数据集,而后者将为每个分区中的每个键计算本地和,并在洗牌后将这些本地和合并为更大的和。
- 当输入和输出值类型不同时,避免reduceByKey
例如,考虑编写一个转换,查找与每个键对应的所有惟一字符串。一种方法是使用map将每个元素转换成一个集合,然后用reduceByKey合并这些集合:

这段代码导致大量不必要的对象创建,因为必须为每个记录分配一个新的集合。
更好的方法是使用aggregateByKey,它可以更有效地执行map端的聚合:

- 避免使用flatMap-join-groupBy模式
当两个数据集已经按键分组,并且您想要加入它们并将它们分组时,您可以使用cogroup。这避免了与组的拆包和重新打包相关的所有开销。
2. 什么时候避免shuffle
当前面的转换已经根据相同的分区程序对数据进行了分区时,Spark知道如何避免随机打乱。考虑以下流程:

因为没有将分区器传递给reduceByKey,所以将使用默认分区器,从而导致rdd1和rdd2都是散列分区的。这两个reduceByKeys将导致两个改组。如果RDDs具有相同数量的分区,则连接将不需要额外的变换。因为RDDs的分区是相同的,所以rdd1的任何单个分区中的键集只能出现在rdd2的单个分区中。因此,rdd3的任何单个输出分区的内容将只依赖于rdd1中的单个分区和rdd2中的单个分区的内容,而不需要第三次洗牌。
例如,如果someRdd有4个分区,someOtherRdd有2个分区,两个reduceByKeys都使用3个分区,那么执行的任务集将如下:
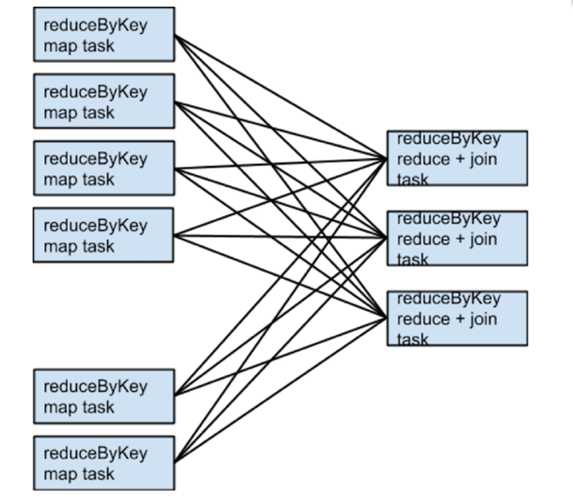
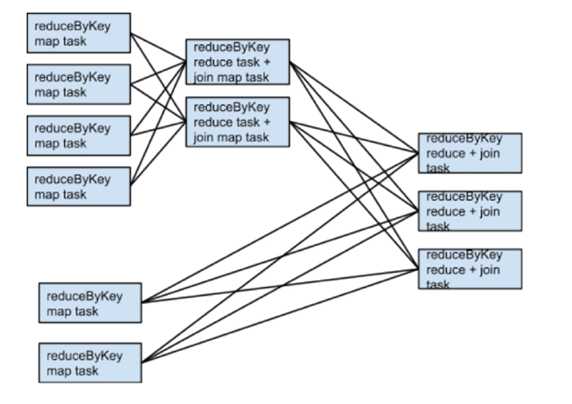
如果rdd1和rdd2使用不同的分区器或使用具有不同数字分区的默认(哈希)分区器会怎么样?在这种情况下,只有一个rdds(分区数量较少的那个)需要为连接重新洗牌。
在连接两个数据集时避免打乱顺序的一种方法是利用广播变量。当其中一个数据集足够小,可以在单个执行程序中装入内存时,可以将其加载到驱动程序的散列表中,然后向每个执行程序广播。映射转换可以引用哈希表来进行查找。
3. 什么时候Shuffle越多越好
在减少洗牌次数的规则中,偶尔会有例外。当增加并行度时,额外的洗牌可能对性能有利。
例如,如果数据以几个大的不可分割文件的形式到达,那么由InputFormat指定的分区可能会在每个分区中放置大量的记录,而不会生成足够的分区来利用所有可用的内核。在这种情况下,在加载数据之后用大量的分区调用重分区(这会引发洗牌)将允许后面的操作利用更多的集群CPU。
当使用reduce或聚合操作将数据聚合到驱动程序中时,可能会出现此异常的另一个实例。当聚合大量的分区时,计算会很快成为驱动程序中合并所有结果的单个线程的瓶颈。要减轻驱动程序的负载,可以首先使用reduceByKey或aggregateByKey执行一轮分布式聚合,将数据集划分为更小数量的分区。在将结果发送到驱动程序进行最后一轮聚合之前,每个分区中的值将并行地彼此合并。看看treeReduce和treeAggregate中如何实现这一点的例子。
当聚合已经按键分组时,这个技巧特别有用。例如,考虑一个应用程序,它希望统计语料库中每个单词的出现次数,并将结果作为Map拉入驱动程序。使用聚合操作可以完成的一种方法是在每个分区计算一个本地映射,然后在驱动程序中合并映射。另一种方法(可以使用aggregateByKey完成) 是以一种完全分布式的方式执行计数,然后简单地将结果收集到驱动程序中。
4. 二次排序
另一个需要注意的重要功能是repartitionAndSortWithinPartitions转换。这是一个听起来神秘的转变,但似乎出现在各种奇怪的情况。这种转换将排序下推到洗牌机制中,在洗牌机制中可以有效地溢出大量数据,并且可以将排序与其他操作结合在一起。例如,Apache Hive on Spark在其join实现中使用这个转换。它还在二级排序模式中充当重要的构建块。您希望按键对记录进行分组,然后在遍历与键对应的值时,让它们以特定的顺序显示。这个问题出现在算法中,算法需要按用户对事件进行分组,然后根据事件发生的时间顺序分析每个用户的事件。
以上是关于Spark 数据分析调优 的主要内容,如果未能解决你的问题,请参考以下文章
Spark篇---Spark调优之代码调优,数据本地化调优,内存调优,SparkShuffle调优,Executor的堆外内存调优