flink系列-11PyFlink 核心功能介绍(整理自 Flink 中文社区)
Posted xiexiandong
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了flink系列-11PyFlink 核心功能介绍(整理自 Flink 中文社区)相关的知识,希望对你有一定的参考价值。
PyFlink 核心功能介绍
- 文章概述:PyFlink 的核心功能原理介绍及相关 demo 演示。
- 作者:程鹤群(军长)(Apache Flink Committer,阿里巴巴技术专家),是 Flink 社区的一名 PMC ,现在在阿里巴巴的实时计算团队。2015年加入阿里巴巴搜索事业部,从事主搜离线相关开发。2017年开始参与 Flink SQL 相关的开发,2019年开始深入参与 PyFlink 相关的开发。
- 整理:谢县东
- 校对:***
课程概要
今天的分享主要包含以下几个部分:
- PyFlink 的发展史。
- 介绍 PyFlink 的核心功能以及其背后的一些原理。
- PyFlink 的 demo 演示。
- PyFlink 社区扶持计划。
1.PyFlink 的发展史
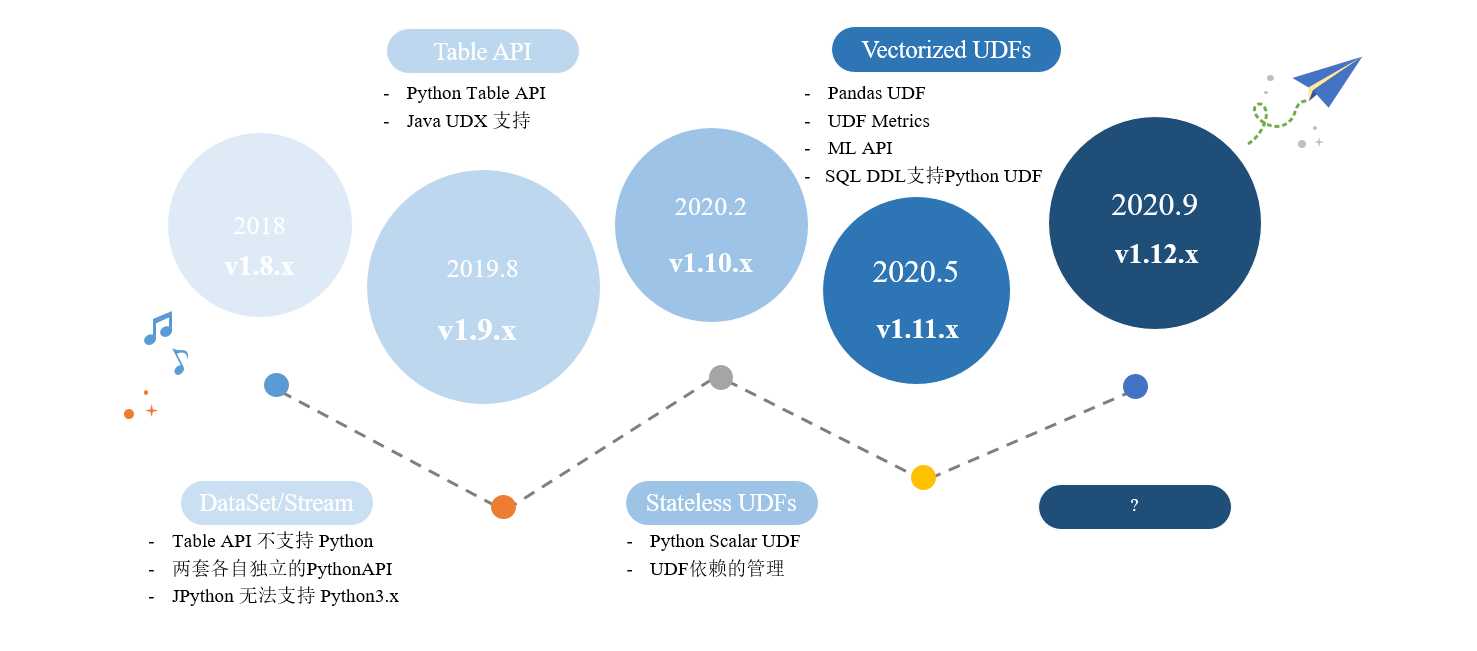
1.1、v1.8.x
- Flink 在1.8版本的时候就已经提供 Python API,只在Datase/Stream 上提供支持。
- 存在一些问题,比如:
2.1 Table API 不支持 Python。
2.2 两套各自独立实现的一个Python API。
2.3 底层实现是JPython,JPython 无法支持 Python3.x。
1.2、v1.9.x
- 2019年8月发布。
- 支持 Python Table API。
1.3、v1.10.x
- 2020年2月发布。
- 提供了 Python、UDF 的支持。
- 提供 UDF 的依赖管理。
1.4、未来发展
- 提供 Pandas UDF的支持。
- 提供用户自定义的一些UDF Metrics。
- ML API。
- 在应用性方面,提供 SQL DDL 支持 Python UDF。
2.PyFlink 核心功能及原理介绍
2.1、Python Table API (Pyflink 1.9)
1.Python Table API
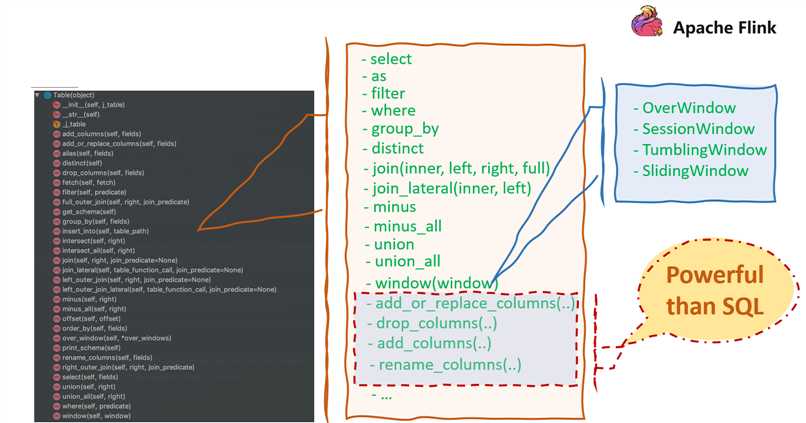
如上图所示,Table 接口主要包括一些 和 Table 相关的算子,这些算子可以分为两类:
- 1.跟 sql 相关的算子。比如 select、filter、join、window 等;
- 2.在 sql 的基础上扩展的一些算子。比如 drop_columns(..),可以用来提升 sql 的便利性,比如当有一个很大的表并且这时候想去删除某一列的时候,可以用 drop_columns 来删除某一列。
2.WordCount

3.Table API 架构
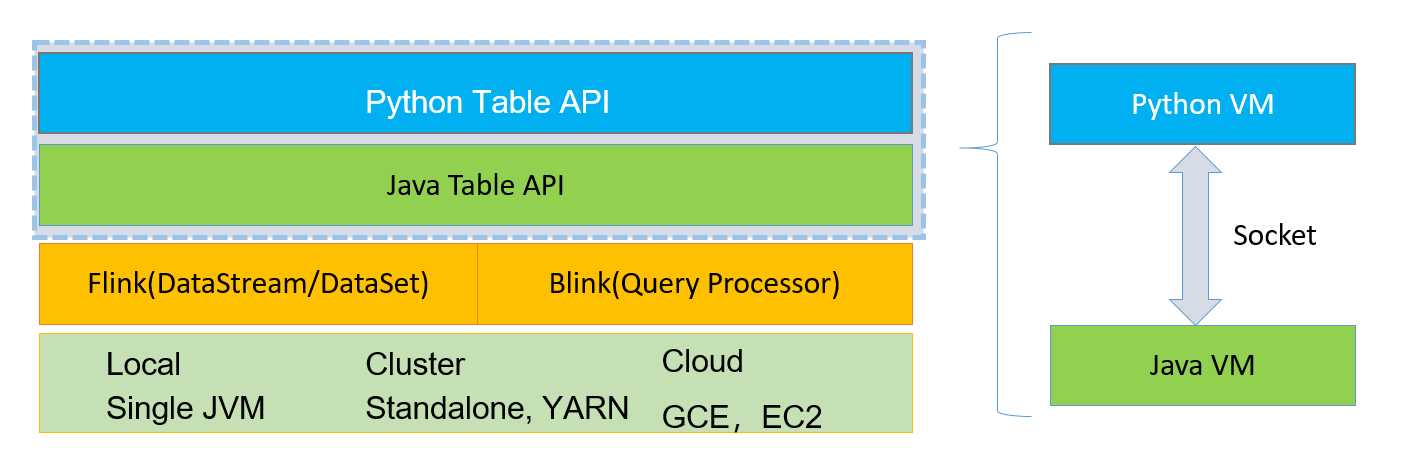
- Python Table API 是建立在 Java Table API的基础上的。
- 这两层 API 可以相互调用。
- client 端的时候,会起一个 Python VM 和一个 Java VM 然后两个 VM 进行通信(一一对应)。
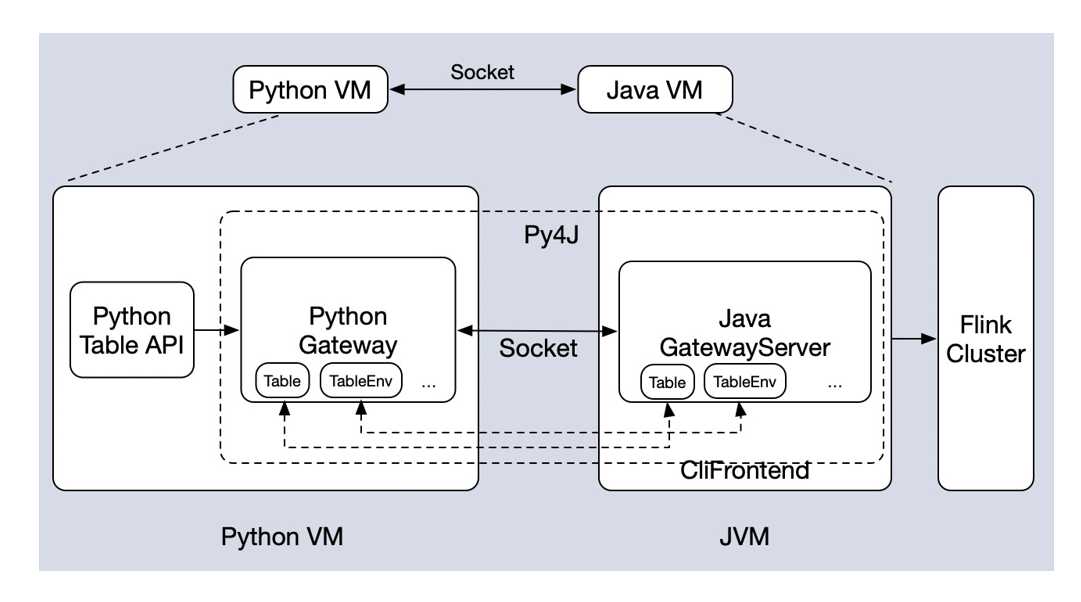
2.2、Python UDF & 依赖管理 (Pyflink 1.10)
1.Python UDF 架构
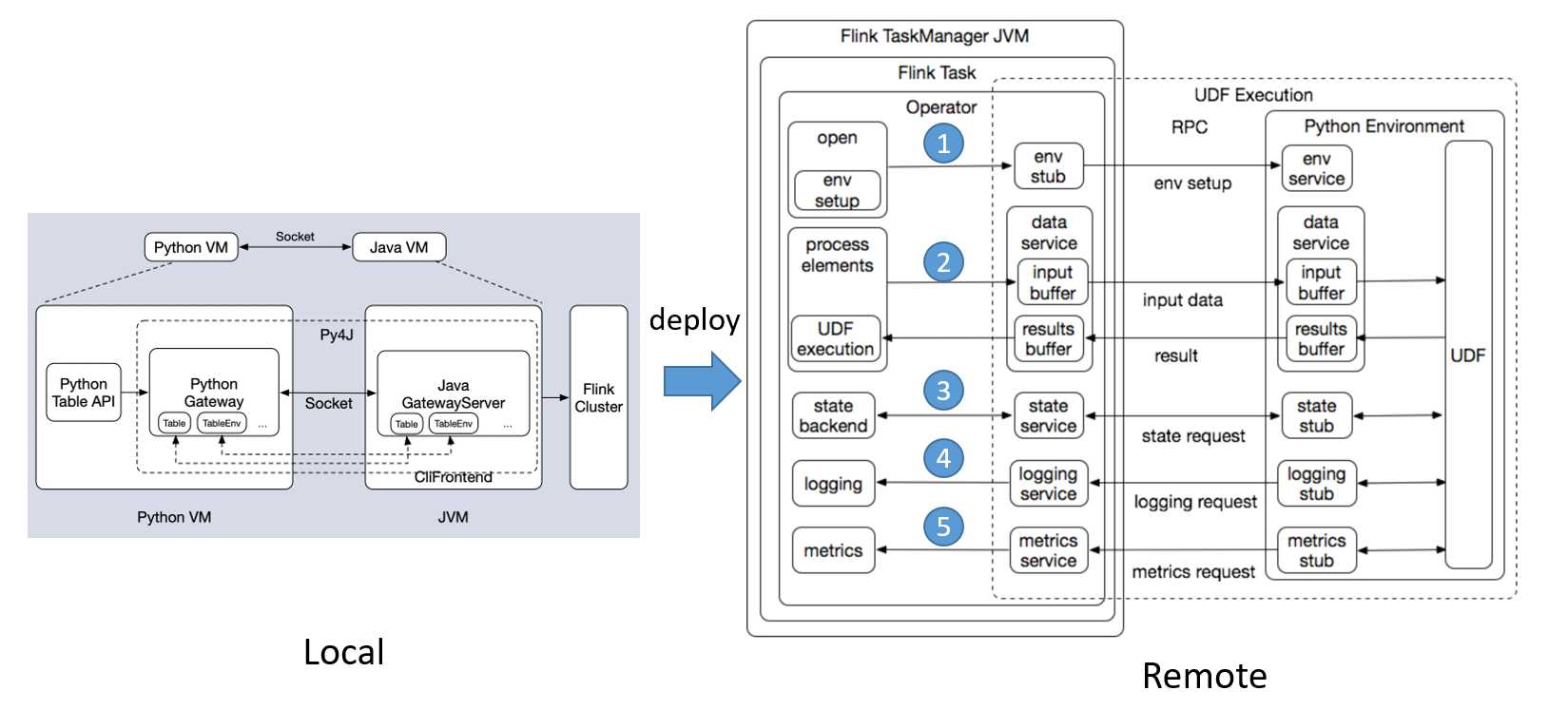
- Remote 端的架构图大概可以分为两个部分,左边部分是 Java 的 Operator,右边是 Python Operator。
- 大体流程:
- 1.在 open 方法里进行 Java Operator 和 Python Operator 的初始化。
- 2.数据处理。当 Java Operator 收到数据之后,先把数据放到一个input buffer 缓冲区中,达到一定的阈值后,才会 flash 到 Python 这边。Python 这边在处理完之后,也会先将数据放到一个结果的缓冲区中,当达到一定阈值,比如达到一定的记录的行数,或者是达到一定的时间的位置,才会把结果 flash 到这边。
- 3.state 访问的链路。
- 4.logging 访问的链路。
- 5.metrics 汇报的链路。
2.Python UDF 的使用
1.Pyflink-1.9 版本中,Python API 中支持注册使用 java UDF,使用方法如下:
table_env.register_java_function("func1", "java.user.defined.function.class.name")

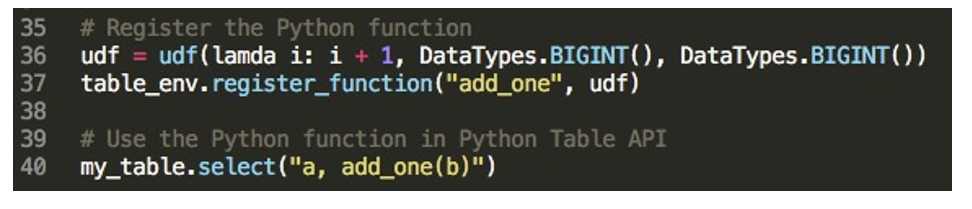
2.Python UDF 的使用:
table_env.register_function("func1", python_udf)
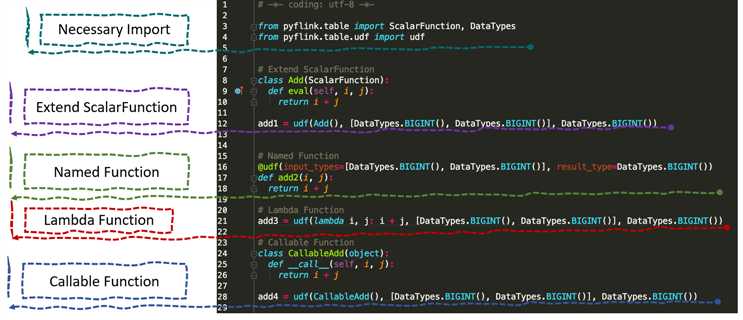
3.Python UDF 的定义方式
4.依赖管理
- 依赖文件
table_env.add_python_file(file_path)
- 依赖存档(打包)文件
table_env.add_python_archive("py_env.zip", "myenv")
# the files contained in the archive file can be accessed in UDF
def my_udf():
with open("myenv/py_env/data/data.txt") as f:
- 依赖第三方项目
# commands executed in shell
echo numpy==1.16.5 > requirements.txt
pip download -d cached_dir -r requirements.txt --no-binary :all:
# python code
table_env.set_python_requirements("requirements.txt", "cached_dir")
- 指定Python Interpreter路径
table_env.get_config().set_python_executable("py_env.zip/py_env/bin/python")
2.3、Pandas UDF & User-defined Metrics (Pyflink 1.11)
1.Pandas UDF – 功能
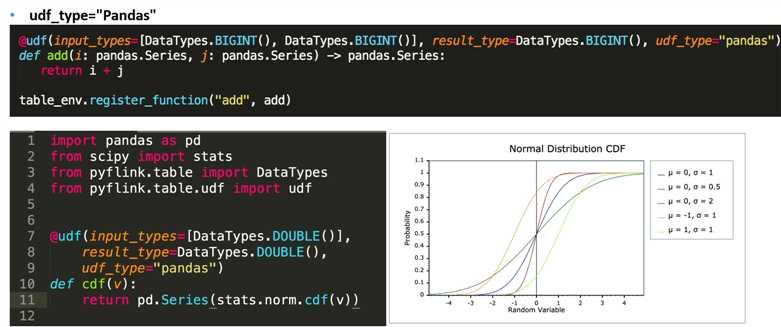
2.Pandas UDF - 性能
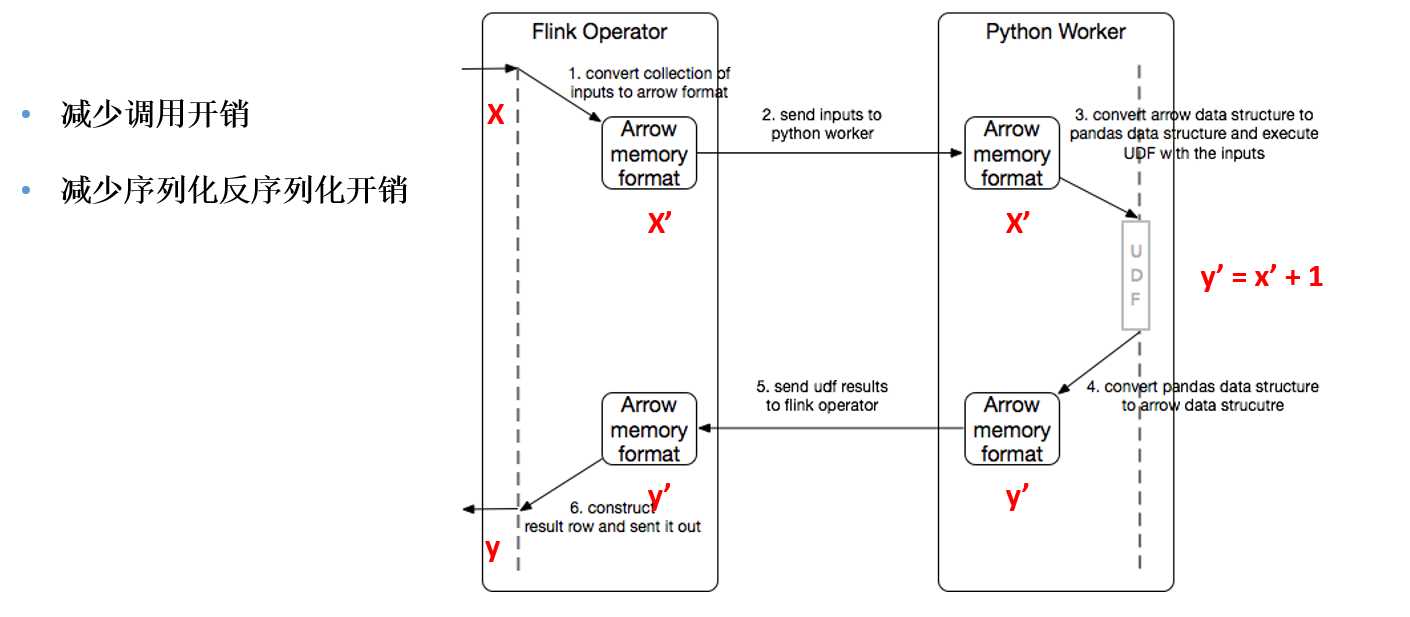
3.User-defined Metrics
- Metric 注册

- Metric Scope
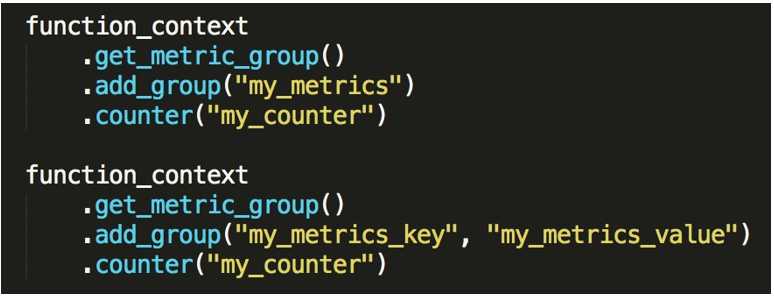
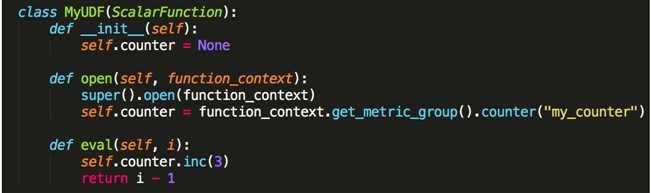
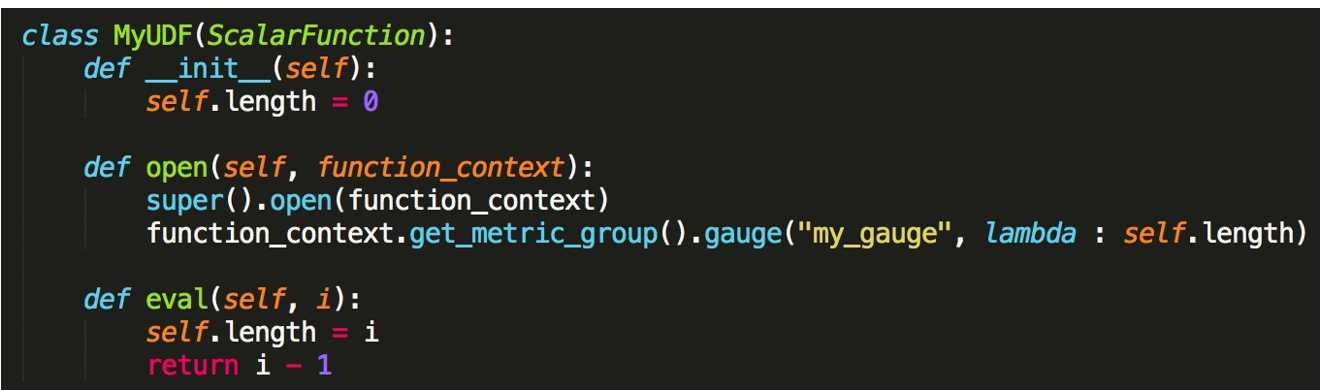
- Metric 类型
- Counter
- Gauge
- Meter
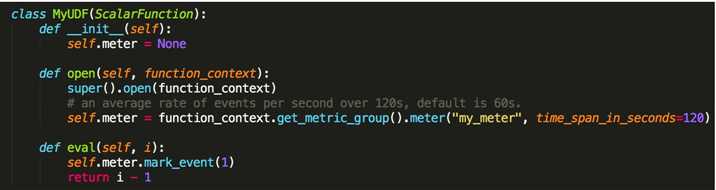
- Distribution (sum/count/min/max/mean)
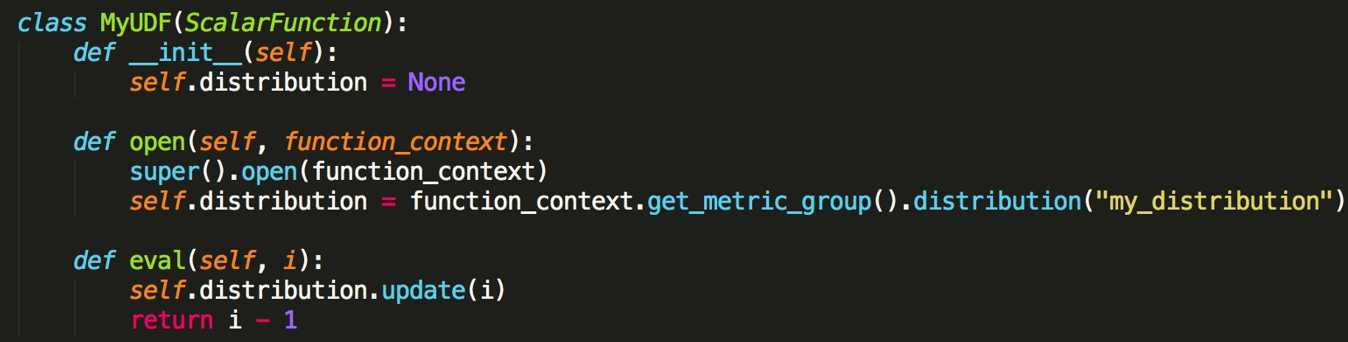
- Counter
3. PyFlink 的 demo 演示
核心功能 demo 的演示:
https://github.com/pyflink/playgrounds
4.PyFlink 社区扶持计划
- 为什么要发起 PyFlink 社区扶持计划?
用户逐渐变多、有经验用户少 - 社区目标:并肩作战,营造双赢
- 如何参与 PyFlink 计划?
https://survey.aliyun.com/apps/zhiliao/B5JOoruzY
初步审核符合条件后我们会在收到问卷的 10 个工作日内与您联系。 - 扶持目标
面向所有 PyFlink 社区公司客户 - PyFlink 问题支持&共享
以上是关于flink系列-11PyFlink 核心功能介绍(整理自 Flink 中文社区)的主要内容,如果未能解决你的问题,请参考以下文章