Spark 运行的4种模式
Posted chong-zuo3322
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark 运行的4种模式相关的知识,希望对你有一定的参考价值。
1. 4种运行模式概述图
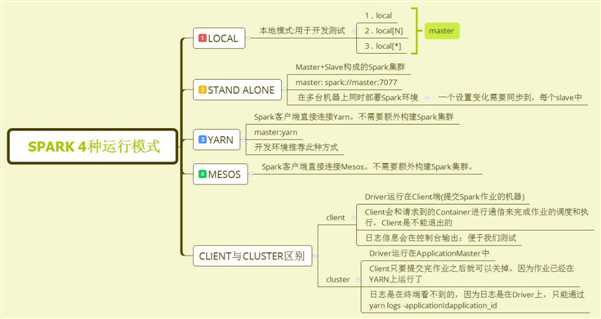
1)本地(local)模式,用于开发测试
2)Standalone
是Spark自带的,如果一个集群是Standalone的话,那么就需要在多台机器上同时部署spark环境,只要修改一台机器配置,就要同步到所有的机器上去,比较麻烦,生产环境中不采取。
3) Yarn
生成环境下使用该模式,统一使用Yarn进行整个集群作业(MR、Spark)的资源调度
Client模式
Driver运行在Client端(提交Spark作业的机器)
Client会和请求到的Container进行通信,来完成作业的调度和执行,Client是不能退出的,ApplicationMaster 申请资源(Yarn ResourceManager)
日志信息会在控制台输出:便于我们测试
Cluster模式
Driver运行在ApplicationMaster中
Client只要提交作业之后就可以关掉,因为作业已经在Yarn运行
日志在中断看不到的,因为日志是在Driver上,只能通过命令 yarn logs -applicationId application_id
4)mesos
2. 不同的提交参数说明
./bin/spark-submit //主类入口 --class <main-class> // 指定appname --name <appname> //pom依赖所需要的resource目录下的资源文件 --files //需要的jar包 --jar //运行内存 --executor-memory 1G //运行内核数 --num-executors 1 //运行模式指定 --master <master-url> //指定client模式或者cluster模式,默认是client --deploy-mode <deploy-mode> //设置参数 --conf <key>=<value> //jar包路径 <application-jar> //main方法的参数 [application-arguments] # Run application locally on 8 cores ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master local[8] /path/to/examples.jar 100 # Run on a Spark standalone cluster in client deploy mode ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://207.184.161.138:7077 --executor-memory 20G --total-executor-cores 100 /path/to/examples.jar 1000 # Run on a Spark standalone cluster in cluster deploy mode with supervise ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://207.184.161.138:7077 --deploy-mode cluster --supervise --executor-memory 20G --total-executor-cores 100 /path/to/examples.jar 1000 # Run on a YARN cluster export HADOOP_CONF_DIR=XXX ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster # can be client for client mode --executor-memory 20G --num-executors 50 /path/to/examples.jar 1000
原文来源:https://blog.csdn.net/wtzhm/article/details/84839352?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.nonecase
以上是关于Spark 运行的4种模式的主要内容,如果未能解决你的问题,请参考以下文章