JPA第三天
Posted artwalker
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JPA第三天相关的知识,希望对你有一定的参考价值。
学于黑马和传智播客联合做的教学项目 感谢
黑马官网
传智播客官网
微信搜索"艺术行者",关注并回复关键词"springdata"获取视频和教程资料!
b站在线视频
第一章 Specifications动态查询
specification:N-COUNT A specification is a requirement which is clearly stated, for example about the necessary features in the design of something.规格;具体要求
有时我们在查询某个实体的时候,给定的条件是不固定的,这时就需要动态构建相应的查询语句,在Spring Data JPA中可以通过JpaSpecificationExecutor接口查询。相比JPQL,其优势是类型安全,更加的面向对象。
/**
* JpaSpecificationExecutor中定义的方法
**/
//根据条件查询一个对象
T findOne(Specification<T> spec);
//根据条件查询集合
List<T> findAll(Specification<T> spec);
//根据条件分页查询
//pageable:分页参数
//返回值:分页pageBean(page:是springdatajpa提供的)
Page<T> findAll(Specification<T> spec, Pageable pageable);
//排序查询查询
List<T> findAll(Specification<T> spec, Sort sort);
//统计查询
long count(Specification<T> spec);
对于JpaSpecificationExecutor,这个接口基本是围绕着Specification接口来定义的。我们可以简单的理解为,Specification构造的就是查询条件。
Specification接口中只定义了如下一个方法:
/**
Specification :查询条件
自定义我们自己的Specification实现类
实现
//root:查询的根对象(查询的任何属性都可以从根对象中获取)
//CriteriaQuery:顶层查询对象,自定义查询方式(了解:一般不用)
//CriteriaBuilder:查询的构造器,封装了很多的查询条件
*/
public Predicate toPredicate(Root<T> root, CriteriaQuery<?> query, CriteriaBuilder cb); //封装查询条件
1.1 使用Specifications完成条件查询
package org.example.test;
import org.example.dao.ICustomerDao;
import org.example.domain.Customer;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.jpa.domain.Specification;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import javax.persistence.criteria.*;
/**
* @author HackerStar
* @create 2020-05-17 21:23
*/
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations = "classpath:applicationContext.xml")
public class SpecTest {
@Autowired
private ICustomerDao customerDao;
/**
* 根据条件,查询单个对象
*/
@Test
public void testSpec() {
//匿名内部类
/**
* 自定义查询条件
* 1.实现Specification接口(提供泛型:查询的对象类型)
* 2.实现toPredicate方法(构造查询条件)
* 3.需要借助方法参数中的两个参数(
* root:获取需要查询的对象属性
* CriteriaBuilder:构造查询条件的,内部封装了很多的查询条件(模糊匹配,精准匹配)
* )
* 案例:根据客户名称查询,查询客户名为Google的客户
* 查询条件
* 1.查询方式
* cb对象
* 2.比较的属性名称
* root对象
*/
Specification<Customer> spec = new Specification<Customer>() {
//使用匿名内部类的方式,创建一个Specification的实现类,并实现toPredicate方法
@Override
public Predicate toPredicate(Root<Customer> root, CriteriaQuery<?> criteriaQuery, CriteriaBuilder criteriaBuilder) {
//criteriaBuilder:构建查询,添加查询方式 equal:完全匹配
//root:从实体Customer对象中按照custName属性进行查询
//1.获取比较的属性
Path<Object> custName = root.get("custName");
//2.构造查询条件 : select * from cst_customer where cust_name = ‘Google‘
/**
* 第一个参数:需要比较的属性(path对象)
* 第二个参数:当前需要比较的取值
*/
Predicate predicate = criteriaBuilder.equal(custName, "Google");//进行精准的匹配 (比较的属性,比较的属性的取值)
return predicate;
}
};
Customer customer = customerDao.findOne(spec);
System.out.println(customer);
}
}
1.2 基于Specifications的分页查询
/**
* 分页查询
* Specification: 查询条件
* Pageable:分页参数
* 分页参数:查询的页码,每页查询的条数
* findAll(Specification,Pageable):带有条件的分页
* findAll(Pageable):没有条件的分页
* 返回:Page(springDataJpa为我们封装好的pageBean对象,数据列表,总条数)
*/
@Test
public void testSpec4() {
Specification specification = null;
//PageRequest对象是Pageable接口的实现类
/**
* 创建PageRequest的过程中,需要调用它的构造方法传入两个参数
* 第一个参数:当前查询的页数(从0开始)
* 第二个参数:每页查询的数量
*/
Pageable pageable = new PageRequest(0, 2);
//分页查询
Page<Customer> page = customerDao.findAll(null, pageable);
page.forEach(customer -> System.out.println(customer));
System.out.println(page.getContent());//得到的数据结合列表
System.out.println(page.getTotalElements());//得到总条数
System.out.println(page.getTotalPages());//得到总页数
}
对于Spring Data JPA中的分页查询,是其内部自动实现的封装过程,返回的是一个Spring Data JPA提供的pageBean对象。其中的方法说明如下:
//获取总页数 int getTotalPages(); //获取总记录数 long getTotalElements(); //获取列表数据 List<T> getContent();
1.3 多条件查询
/**
* 多条件查询
* 案例:根据客户名(Google)和客户所属行业查询(software)
*/
@Test
public void testSpec1() {
/**
* root:获取属性
* 客户名
* 所属行业
* cb:构造查询
* 1.构造客户名的精准匹配查询
* 2.构造所属行业的精准匹配查询
* 3.将以上两个查询联系起来
*/
Specification<Customer> spec = new Specification<Customer>() {
@Override
public Predicate toPredicate(Root<Customer> root, CriteriaQuery<?> criteriaQuery, CriteriaBuilder criteriaBuilder) {
Path<Object> custName = root.get("custName");
Path<Object> custIndustry = root.get("custIndustry");
//构造查询
//1.构造客户名的精准匹配查询
Predicate p1 = criteriaBuilder.equal(custName, "Google");
//2..构造所属行业的精准匹配查询
Predicate p2 = criteriaBuilder.equal(custIndustry, "software");
//3.将多个查询条件组合到一起:组合(满足条件一并且满足条件二:与关系,满足条件一或满足条件二即可:或关系)
Predicate and = criteriaBuilder.and(p1, p2);
return and;
}
};
Customer customer = customerDao.findOne(spec);
System.out.println(customer);
}
1.4 模糊匹配及排序
/**
* 案例:完成根据客户名称的模糊匹配,返回客户列表
* 客户名称以 ’Goo‘ 开头
*
* equal :直接的到path对象(属性),然后进行比较即可
* gt,lt,ge,le,like : 得到path对象,根据path指定比较的参数类型,再去进行比较
* 指定参数类型:path.as(类型的字节码对象)
*/
@Test
public void testSpec3() {
//构造查询条件
Specification<Customer> spec = new Specification<Customer>() {
@Override
public Predicate toPredicate(Root<Customer> root, CriteriaQuery<?> criteriaQuery, CriteriaBuilder criteriaBuilder) {
//查询属性:客户名
Path<Object> custName = root.get("custName");
//查询方式:模糊匹配
Predicate like = criteriaBuilder.like(custName.as(String.class), "Goo%");
return like;
}
};
List<Customer> customers = customerDao.findAll(spec);
customers.forEach(customer -> {
System.out.println(customer);
});
//添加排序
//创建排序对象,需要调用构造方法实例化sort对象
//第一个参数:排序的顺序(倒序,正序)
// Sort.Direction.DESC:倒序
// Sort.Direction.ASC : 升序
//第二个参数:排序的属性名称
Sort sort = new Sort(Sort.Direction.DESC, "custId");
List<Customer> customers1 = customerDao.findAll(spec, sort);
customers1.forEach(customer -> {
System.out.println(customer);
});
}
1.5 方法对应关系
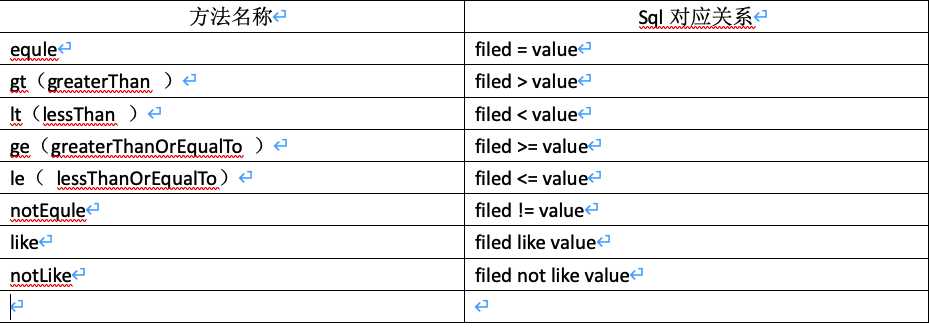
第二章 多表设计
2.1 表之间关系的划分
数据库中多表之间存在着三种关系,如图所示。
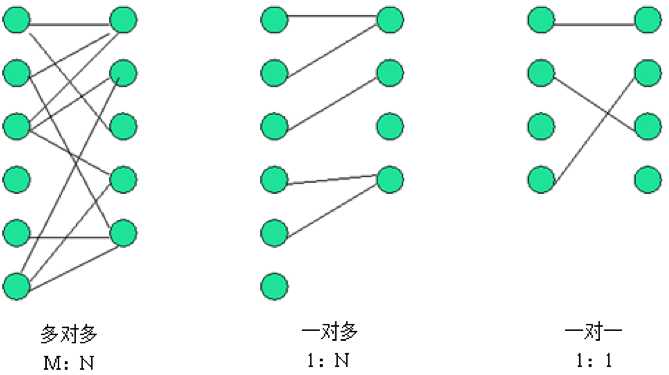
从图可以看出,系统设计的三种实体关系分别为:多对多、一对多和一对一关系。注意:一对多关系可以看为两种: 即一对多,多对一。所以说四种更精确。
明确: 我们今天只涉及实际开发中常用的关联关系,一对多和多对多。而一对一的情况,在实际开发中几乎不用。
表关系
一对一
一对多:
一的一方:主表
多的一方:从表
外键:需要再从表上新建一列作为外键,他的取值来源于主表的主键
多对多:
中间表:中间表中最少应该由两个字段组成,这两个字段做为外键指向两张表的主键,又组成了联合主键老师对学生:一对多关系
实体类中的关系
包含关系:可以通过实体类中的包含关系描述表关系
继承关系
2.2 在JPA框架中表关系的分析步骤
在实际开发中,我们数据库的表难免会有相互的关联关系,在操作表的时候就有可能会涉及到多张表的操作。而在这种实现了ORM思想的框架中(如JPA),可以让我们通过操作实体类就实现对数据库表的操作。所以今天我们的学习重点是:掌握配置实体之间的关联关系。
第一步:首先确定两张表之间的关系( 如果关系确定错了,后面做的所有操作就都不可能正确。)
第二步:在数据库中实现两张表的关系
第三步:在实体类中描述出两个实体的关系
第四步:配置出实体类和数据库表的关系映射(重点)
第三章 JPA中的一对多
3.1 示例分析
我们采用的示例为客户和联系人。
客户:指的是一家公司,我们记为A。
联系人:指的是A公司中的员工。
在不考虑兼职的情况下,公司和员工的关系即为一对多。
一个客户可以具有多个联系人
一个联系人从属于一家公司
3.2 表关系建立
在一对多关系中,我们习惯把一的一方称之为主表,把多的一方称之为从表。在数据库中建立一对多的关系,需要使用数据库的外键约束。
什么是外键?
指的是从表中有一列,取值参照主表的主键,这一列就是外键。
一对多数据库关系的建立,如下图所示 :

分析步骤
1.明确表关系
一对多关系
2.确定表关系(描述 外键|中间表)
主表:客户表
从表:联系人表
* 再从表上添加外键
3.编写实体类,在实体类中描述表关系(包含关系)
客户:在客户的实体类中包含一个联系人的集合
联系人:在联系人的实体类中包含一个客户的对象
4.配置映射关系
* 使用jpa注解配置一对多映射关系
3.3 实体类关系建立以及映射
首先在数据库创建表。
在实体类中,由于客户是少的一方,它应该包含多个联系人,所以实体类要体现出客户中有多个联系人的信息(在客户的实体类中包含一个联系人的集合(用set集合)),代码如下:
package org.example.domain;
import javax.persistence.*;
import java.util.HashSet;
import java.util.Set;
/**
* 1. 实体类和表的映射关系
* @Entity
* @Table
* 2. 类中属性和表中字段的映射关系
* @Id
* @GeneratedValue
* @Column
*/
@Entity
@Table(name = "cust_customer")
public class Customer {
@Id//表明当前私有属性是主键
@GeneratedValue(strategy = GenerationType.IDENTITY)//指定主键的生成策略
@Column(name = "cust_id")//指定和数据库表中的cust_id列对应
private Long custId;
@Column(name = "cust_address")//指定和数据库表中的cust_address列对应
private String custAddress;
@Column(name = "cust_industry")//指定和数据库表中的cust_industry列对应
private String custIndustry;
@Column(name = "cust_level")//指定和数据库表中的cust_level列对应
private String custLevel;
@Column(name = "cust_name")//指定和数据库表中的cust_name列对应
private String custName;
@Column(name = "cust_phone")//指定和数据库表中的cust_phone列对应
private String custPhone;
@Column(name = "cust_source")//指定和数据库表中的cust_source列对应
private String custSource;
//配置客户和联系人之间的关系(一对多关系)
/**
* 使用注解的形式配置多表关系
* 1.声明关系
* @OneToMany : 配置一对多关系
* targetEntity :对方对象的字节码对象
* 2.配置外键(多对多配置中间表)
* @JoinColumn : 配置外键
* name:外键字段名称
* referencedColumnName:参照的主表的主键字段名称
*
* * 在客户实体类上(一的一方)添加了外键了配置,所以对于客户而言,也具备了维护外键的作用
*/
@OneToMany(targetEntity = LinkMan.class)
@JoinColumn(name = "lkm_cust_id", referencedColumnName = "cust_id")
private Set<LinkMan> linkMans = new HashSet<>();
@Override
public String toString() {
return "Customer{" +
"custId=" + custId +
", custAddress=‘" + custAddress + ‘‘‘ +
", custIndustry=‘" + custIndustry + ‘‘‘ +
", custLevel=‘" + custLevel + ‘‘‘ +
", custName=‘" + custName + ‘‘‘ +
", custPhone=‘" + custPhone + ‘‘‘ +
", custSource=‘" + custSource + ‘‘‘ +
‘}‘;
}
public Set<LinkMan> getLinkMans() {
return linkMans;
}
public void setLinkMans(Set<LinkMan> linkMans) {
this.linkMans = linkMans;
}
public Long getCustId() {
return custId;
}
public void setCustId(Long custId) {
this.custId = custId;
}
public String getCustAddress() {
return custAddress;
}
public void setCustAddress(String custAddress) {
this.custAddress = custAddress;
}
public String getCustIndustry() {
return custIndustry;
}
public void setCustIndustry(String custIndustry) {
this.custIndustry = custIndustry;
}
public String getCustLevel() {
return custLevel;
}
public void setCustLevel(String custLevel) {
this.custLevel = custLevel;
}
public String getCustName() {
return custName;
}
public void setCustName(String custName) {
this.custName = custName;
}
public String getCustPhone() {
return custPhone;
}
public void setCustPhone(String custPhone) {
this.custPhone = custPhone;
}
public String getCustSource() {
return custSource;
}
public void setCustSource(String custSource) {
this.custSource = custSource;
}
}
由于联系人是多的一方,在实体类中要体现出,每个联系人只能对应一个客户(在联系人的实体类中包含一个客户的对象),代码如下:
package org.example.domain;
import javax.persistence.*;
import java.io.Serializable;
/**
* 联系人的实体类(数据模型)
*/
@Entity
@Table(name = "cst_linkman")
public class LinkMan implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "lkm_id")
private Long lkmId;
@Column(name = "lkm_name")
private String lkmName;
@Column(name = "lkm_gender")
private String lkmGender;
@Column(name = "lkm_phone")
private String lkmPhone;
@Column(name = "lkm_mobile")
private String lkmMobile;
@Column(name = "lkm_email")
private String lkmEmail;
@Column(name = "lkm_position")
private String lkmPosition;
@Column(name = "lkm_memo")
private String lkmMemo;
@Column(name = "lkm_cust_id")
private String lkmCustId;
/**
* 配置联系人到客户的多对一关系
* 使用注解的形式配置多对一关系
* 1.配置表关系
* @ManyToOne : 配置多对一关系
* targetEntity:对方的实体类字节码
* 2.配置外键(中间表)
* @JoinColumn : 配置外键
* name:外键字段名称
* referencedColumnName:参照的主表的主键字段名称
*
* * 配置外键的过程,配置到了多的一方,就会在多的一方维护外键
*/
@ManyToOne(targetEntity = Customer.class)
@JoinColumn(name = "lkm_cust_id", referencedColumnName = "cust_id")
private Customer customer;
@Override
public String toString() {
return "LinkMan{" +
"lkmId=" + lkmId +
", lkmName=‘" + lkmName + ‘‘‘ +
", lkmGender=‘" + lkmGender + ‘‘‘ +
", lkmPhone=‘" + lkmPhone + ‘‘‘ +
", lkmMobile=‘" + lkmMobile + ‘‘‘ +
", lkmEmail=‘" + lkmEmail + ‘‘‘ +
", lkmPosition=‘" + lkmPosition + ‘‘‘ +
", lkmMemo=‘" + lkmMemo + ‘‘‘ +
", lkmCustId=‘" + lkmCustId + ‘‘‘ +
‘}‘;
}
public Customer getCustomer() {
return customer;
}
public void setCustomer(Customer customer) {
this.customer = customer;
}
public Long getLkmId() {
return lkmId;
}
public void setLkmId(Long lkmId) {
this.lkmId = lkmId;
}
public String getLkmName() {
return lkmName;
}
public void setLkmName(String lkmName) {
this.lkmName = lkmName;
}
public String getLkmGender() {
return lkmGender;
}
public void setLkmGender(String lkmGender) {
this.lkmGender = lkmGender;
}
public String getLkmPhone() {
return lkmPhone;
}
public void setLkmPhone(String lkmPhone) {
this.lkmPhone = lkmPhone;
}
public String getLkmMobile() {
return lkmMobile;
}
public void setLkmMobile(String lkmMobile) {
this.lkmMobile = lkmMobile;
}
public String getLkmEmail() {
return lkmEmail;
}
public void setLkmEmail(String lkmEmail) {
this.lkmEmail = lkmEmail;
}
public String getLkmPosition() {
return lkmPosition;
}
public void setLkmPosition(String lkmPosition) {
this.lkmPosition = lkmPosition;
}
public String getLkmMemo() {
return lkmMemo;
}
public void setLkmMemo(String lkmMemo) {
this.lkmMemo = lkmMemo;
}
public String getLkmCustId() {
return lkmCustId;
}
public void setLkmCustId(String lkmCustId) {
this.lkmCustId = lkmCustId;
}
}
3.4 映射的注解说明
@ManyToMany
作用:用于映射多对多关系
属性:
cascade:配置级联操作。
fetch:配置是否采用延迟加载。
targetEntity:配置目标的实体类。映射多对多的时候不用写。
@JoinTable
作用:针对中间表的配置
属性:
name:配置中间表的名称
joinColumns:中间表的外键字段关联当前实体类所对应表的主键字段
inverseJoinColumn:中间表的外键字段关联对方表的主键字段
@JoinColumn
作用:用于定义主键字段和外键字段的对应关系。
属性:
name:指定外键字段的名称
referencedColumnName:指定引用主表的主键字段名称
unique:是否唯一。默认值不唯一
nullable:是否允许为空。默认值允许。
insertable:是否允许插入。默认值允许。
updatable:是否允许更新。默认值允许。
columnDefinition:列的定义信息。
3.5 一对多的操作
首先在applicationContext.xml文件中添加新的
<!--注入jpa的配置信息
加载jpa的基本配置信息和jpa实现方式(hibernate)的配置信息
hibernate.hbm2ddl.auto : 自动创建数据库表
create : 每次都会重新创建数据库表
update:有表不会重新创建,没有表会重新创建表
-->
<property name="jpaProperties" >
<props>
<prop key="hibernate.hbm2ddl.auto">update</prop>
</props>
</property>
3.5.1 添加
package org.example.test;
import org.example.dao.ICustomerDao;
import org.example.dao.ILinkManDao;
import org.example.domain.Customer;
import org.example.domain.LinkMan;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.test.annotation.Rollback;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import org.springframework.transaction.annotation.Transactional;
/**
* @author HackerStar
* @create 2020-05-17 21:23
*/
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations = "classpath:applicationContext.xml")
public class One2ManyTest {
@Autowired
private ICustomerDao customerDao;
@Autowired
private ILinkManDao linkManDao;
/**
* 保存一个客户,保存一个联系人
* 效果:客户和联系人作为独立的数据保存到数据库中
* 联系人的外键为空
* 原因?
* 实体类中没有配置关系
*/
@Test
@Transactional//配置事务
@Rollback(false)
//不自动回滚
public void testAdd() {
//创建一个客户
Customer customer = new Customer();
customer.setCustName("Apple");
customer.setCustIndustry("software");
//创建一个联系人
LinkMan linkMan = new LinkMan();
linkMan.setLkmName("Jobs");
linkMan.setLkmEmail("jobs@apple.com");
/**
* 配置了客户到联系人的关系
* 从客户的角度上:发送两条insert语句,发送一条更新语句更新数据库(更新外键)
* 由于我们配置了客户到联系人的关系:客户可以对外键进行维护
*/
customer.getLinkMans().add(linkMan);
customerDao.save(customer);
linkManDao.save(linkMan);
}
}
@Test
@Transactional //配置事务
@Rollback(false) //不自动回滚
public void testAdd1() {
//创建一个客户,创建一个联系人
Customer customer = new Customer();
customer.setCustName("百度");
LinkMan linkMan = new LinkMan();
linkMan.setLkmName("小李");
/**
* 配置联系人到客户的关系(多对一)
* 只发送了两条insert语句
* 由于配置了联系人到客户的映射关系(多对一)
*/
linkMan.setCustomer(customer);
customerDao.save(customer);
linkManDao.save(linkMan);
}
/**
* 会有一条多余的update语句
* * 由于一的一方可以维护外键:会发送update语句
* * 解决此问题:只需要在一的一方放弃维护权即可
*
*/
@Test
@Transactional //配置事务
@Rollback(false) //不自动回滚
public void testAdd2() {
//创建一个客户,创建一个联系人
Customer customer = new Customer();
customer.setCustName("百度");
LinkMan linkMan = new LinkMan();
linkMan.setLkmName("小李");
linkMan.setCustomer(customer);//由于配置了多的一方到一的一方的关联关系(当保存的时候,就已经对外键赋值)
customer.getLinkMans().add(linkMan);//由于配置了一的一方到多的一方的关联关系(发送一条update语句)
customerDao.save(customer);
linkManDao.save(linkMan);
}
通过保存的案例,我们可以发现在设置了双向关系之后,会发送两条insert语句,一条多余的update语句(只要是配置了一的一方到多的一方的关联关系就会发送update语句),那我们的解决是思路很简单,就是一的一方放弃维护权。
/**
* 放弃外键维护权的配置将如下配置
//@OneToMany(targetEntity=LinkMan.class)
//@JoinColumn(name="lkm_cust_id",referencedColumnName="cust_id")
//设置为
*/
@OneToMany(mappedBy="customer")
private Set<LinkMan> linkMans = new HashSet<>();
3.5.2 删除
删除操作的说明如下:
删除从表数据:可以随时任意删除。
删除主表数据:
-
有从表数据
-
在默认情况下,它会把外键字段置为null,然后删除主表数据。如果在数据库的表结构上,外键字段有非空约束,默认情况就会报错了。
-
如果配置了放弃维护关联关系的权利,则不能删除(与外键字段是否允许为null,没有关系)因为在删除时,它根本不会去更新从表的外键字段了。
-
如果还想删除,使用级联删除引用
-
-
无从表数据引用:随便删
在实际开发中,级联删除请慎用!(在一对多的情况下)
3.5.3 级联操作
级联操作:指操作一个对象同时操作它的关联对象。
使用方法:只需要在操作主体的注解上配置cascade
级联操作:
1.需要区分操作主体
2.需要在操作主体的实体类上,添加级联属性(需要添加到多表映射关系的注解上)
3.cascade(配置级联)
/**
* cascade:配置级联操作
* CascadeType.MERGE 级联更新
* CascadeType.PERSIST 级联保存:
* CascadeType.REFRESH 级联刷新:
* CascadeType.REMOVE 级联删除:
* CascadeType.ALL 包含所有
*/
3.5.3.1 级联添加
级联添加,
案例:当我保存一个客户的同时保存联系人
/**
* 级联添加:保存一个客户的同时,保存客户的所有联系人
* 需要在操作主体的实体类上,配置casacde属性
*/
@Test
@Transactional //配置事务
@Rollback(false) //不自动回滚
public void testCascadeAdd() {
Customer customer = new Customer();
customer.setCustName("淘宝");
LinkMan linkMan = new LinkMan();
linkMan.setLkmName("小s");
linkMan.setCustomer(customer);
customer.getLinkMans().add(linkMan);
customerDao.save(customer);
}
3.5.3.2 级联删除
级联删除
案例:当我删除一个客户的同时删除此客户的所有联系人
/**
* 级联删除:
* 删除15号客户的同时,删除15号客户的所有联系人
*/
@Test
@Transactional //配置事务
@Rollback(false) //不自动回滚
public void testCascadeRemove() {
//1.查询15号客户
Customer customer = customerDao.findOne(15l);
//2.删除15号客户
customerDao.delete(customer);
}
第四章 JPA中的多对多
4.1 示例分析
我们采用的示例为用户和角色。
用户:指的是咱们班的每一个同学。
角色:指的是咱们班同学的身份信息。
比如A同学,它是学生,其中有个身份就是学生,还是家里的孩子,那么他还有个身份是子女。
同时B同学,它也具有学生和子女的身份。
那么任何一个同学都可能具有多个身份。同时学生这个身份可以被多个同学所具有。
所以我们说,用户和角色之间的关系是多对多。
4.2 表关系建立
多对多的表关系建立靠的是中间表,其中用户表和中间表的关系是一对多,角色表和中间表的关系也是一对多,如下图所示:
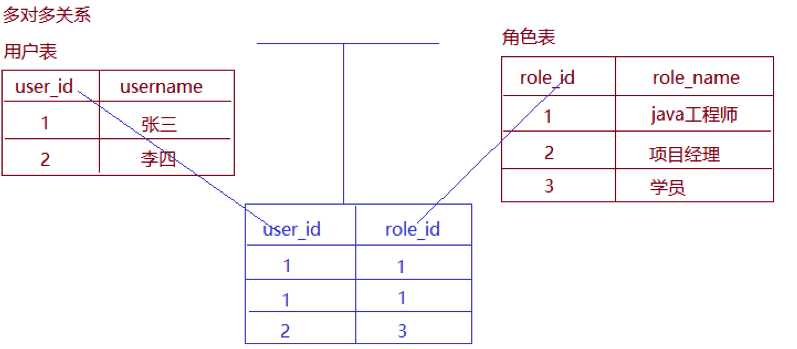
4.3 实体类关系建立以及映射
cascade: n 瀑布
一个用户可以具有多个角色,所以在用户实体类中应该包含多个角色的信息,代码如下:
package org.example.domain;
import javax.persistence.*;
import java.util.HashSet;
import java.util.Set;
/**
* @author HackerStar
* @create 2020-05-18 15:38
*/
@Entity
@Table(name = "sys_user")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "user_id")
private Long userId;
@Column(name = "user_name")
private String userName;
@Column(name = "user_age")
private Integer age;
/**
* 配置用户到角色的多对多关系
* 配置多对多的映射关系
* 1.声明表关系的配置
* @ManyToMany(targetEntity = Role.class) //多对多
* targetEntity:代表对方的实体类字节码
* 2.配置中间表(包含两个外键)
* @JoinTable
* name : 中间表的名称
* joinColumns:配置当前对象在中间表的外键
* @JoinColumn的数组
* name:外键名
* referencedColumnName:参照的主表的主键名
* inverseJoinColumns:配置对方对象在中间表的外键
* name:外键名
* referencedColumnName:参照的主表的主键名
*/
@ManyToMany(targetEntity = Role.class, cascade = CascadeType.ALL)
@JoinTable(name = "sys_user_role",
//joinColumns,当前对象在中间表中的外键
joinColumns = {@JoinColumn(name = "sys_user_id", referencedColumnName = "user_id")},
//inverseJoinColumns,对方对象在中间表的外键
inverseJoinColumns = {@JoinColumn(name = "sys_role_id", referencedColumnName = "role_id")}
)
private Set<Role> roles = new HashSet<>();
@Override
public String toString() {
return "User{" +
"userId=" + userId +
", userName=‘" + userName + ‘‘‘ +
", age=" + age +
‘}‘;
}
public Long getUserId() {
return userId;
}
public void setUserId(Long userId) {
this.userId = userId;
}
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public Set<Role> getRoles() {
return roles;
}
public void setRoles(Set<Role> roles) {
this.roles = roles;
}
}
一个角色可以赋予多个用户,所以在角色实体类中应该包含多个用户的信息,代码如下:
package org.example.domain;
import javax.persistence.*;
import java.util.HashSet;
import java.util.Set;
/**
* @author HackerStar
* @create 2020-05-18 15:40
*/
@Entity
@Table(name = "sys_role")
public class Role {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "role_id")
private Long roleId;
@Column(name = "role_name")
private String roleName;
//配置多对多
@ManyToMany(mappedBy = "roles") //配置多表关系
private Set<User> users = new HashSet<>();
@Override
public String toString() {
return "Role{" +
"roleId=" + roleId +
", roleName=‘" + roleName + ‘‘‘ +
‘}‘;
}
public Long getRoleId() {
return roleId;
}
public void setRoleId(Long roleId) {
this.roleId = roleId;
}
public String getRoleName() {
return roleName;
}
public void setRoleName(String roleName) {
this.roleName = roleName;
}
public Set<User> getUsers() {
return users;
}
public void setUsers(Set<User> users) {
this.users = users;
}
}
4.4 映射的注解说明
@ManyToMany
作用:用于映射多对多关系
属性:
cascade:配置级联操作。
fetch:配置是否采用延迟加载。
targetEntity:配置目标的实体类。映射多对多的时候不用写。
@JoinTable
作用:针对中间表的配置
属性:
nam:配置中间表的名称
joinColumns:中间表的外键字段关联当前实体类所对应表的主键字段
inverseJoinColumn:中间表的外键字段关联对方表的主键字段
@JoinColumn
作用:用于定义主键字段和外键字段的对应关系。
属性:
name:指定外键字段的名称
referencedColumnName:指定引用主表的主键字段名称
unique:是否唯一。默认值不唯一
nullable:是否允许为空。默认值允许。
insertable:是否允许插入。默认值允许。
updatable:是否允许更新。默认值允许。
columnDefinition:列的定义信息。
4.5 多对多的操作
4.5.1 保存
package org.example.test;
import org.example.dao.IRoleDao;
import org.example.dao.IUserDao;
import org.example.domain.Role;
import org.example.domain.User;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.test.annotation.Rollback;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import org.springframework.transaction.annotation.Transactional;
/**
* @author HackerStar
* @create 2020-05-18 15:54
*/
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations = "classpath:applicationContext.xml")
public class Many2ManyTest {
@Autowired
private IUserDao userDao;
@Autowired
private IRoleDao roleDao;
/**
* 保存一个用户,保存一个角色
* 多对多放弃维护权:被动的一方放弃
*/
@Test
@Transactional
@Rollback(false)
public void testAdd() {
User user = new User();
user.setUserName("小李");
Role role = new Role();
role.setRoleName("java程序员");
//配置用户到角色关系,可以对中间表中的数据进行维护 1-1
user.getRoles().add(role);
//配置角色到用户的关系,可以对中间表的数据进行维护 1-1
role.getUsers().add(user);
userDao.save(user);
roleDao.save(role);
}
}
//测试级联添加(保存一个用户的同时保存用户的关联角色)
@Test
@Transactional
@Rollback(false)
public void testCasCadeAdd() {
User user = new User();
user.setUserName("小李");
Role role = new Role();
role.setRoleName("java程序员");
//配置用户到角色关系,可以对中间表中的数据进行维护 1-1
user.getRoles().add(role);
//配置角色到用户的关系,可以对中间表的数据进行维护 1-1
role.getUsers().add(user);
userDao.save(user);
}
如果双方都维护关联关系问题:
* 在保存时,会出现主键重复的错误,因为都是要往中间表中保存数据造成的。
* 解决办法:
? 让任意一方放弃维护关联关系的权利
在多对多(保存)中,如果双向都设置关系,意味着双方都维护中间表,都会往中间表插入数据,中间表的2个字段又作为联合主键,所以报错,主键重复,解决保存失败的问题:只需要在任意一方放弃对中间表的维护权即可,推荐在被动的一方放弃,配置如下:
//放弃对中间表的维护权,解决保存中主键冲突的问题 @ManyToMany(mappedBy="roles") private Set<User> users = new HashSet<>();
4.5.2 删除
/**
* 案例:删除id为1的用户,同时删除他的关联对象
* 删除操作
* 在多对多的删除时,双向级联删除根本不能配置
* 禁用
* 如果配了的话,如果数据之间有相互引用关系,可能会清空所有数据
*/
@Test
@Transactional
@Rollback(false)
public void testCasCadeRemove() {
//查询1号用户
User user = userDao.findOne(1l);
//删除1号用户
userDao.delete(user);
}
第五章 Spring Data JPA中的多表查询
5.1 对象导航查询
对象图导航检索方式是根据已经加载的对象,导航到他的关联对象。它利用类与类之间的关系来检索对象。例如:我们通过ID查询方式查出一个客户,可以调用Customer类中的getLinkMans()方法来获取该客户的所有联系人。对象导航查询的使用要求是:两个对象之间必须存在关联关系。
package org.example.test;
import org.example.dao.ICustomerDao;
import org.example.dao.ILinkManDao;
import org.example.domain.Customer;
import org.example.domain.LinkMan;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import org.springframework.transaction.annotation.Transactional;
import java.util.Set;
/**
* @author HackerStar
* @create 2020-05-18 16:24
*/
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations = "classpath:applicationContext.xml")
public class ObjectQueryTest {
@Autowired
private ICustomerDao customerDao;
@Autowired
private ILinkManDao linkManDao;
//could not initialize proxy - no Session
//测试对象导航查询(查询一个对象的时候,通过此对象查询所有的关联对象)
@Test
@Transactional //解决在java代码中的no session问题
public void testQuery1() {
//查询id为1的客户
Customer customer = customerDao.getOne(12l);
//对象导航查询,此客户下的所有联系人
Set<LinkMan> linkMans = customer.getLinkMans();
linkMans.forEach(linkMan -> {
System.out.println(linkMan);
});
System.out.println(linkMans);
}
}
对象导航查询的问题分析:
问题1:我们查询客户时,要不要把联系人查询出来?
分析:如果我们不查的话,在用的时候还要自己写代码,调用方法去查询。如果我们查出来的,不使用时又会白白的浪费了服务器内存。
解决:采用延迟加载的思想。通过配置的方式来设定当我们在需要使用时,发起真正的查询。(默认从一查询多时,使用的是延迟加载,默认从多查询一时,使用的是立即加载)
配置方式:
fetch: verb If you fetch something or someone, you go and get them from the place where they are.去拿;去取;去接
/**
* 在对象的@OneToMany注解中添加fetch属性
* FetchType.EAGER :立即加载
* FetchType.LAZY :延迟加载
*/
@OneToMany(mappedBy = "customer",cascade = CascadeType.ALL, fetch = FetchType.LAZY)
private Set<LinkMan> linkMans = new HashSet<>();
问题2:我们查询联系人时,要不要把客户查询出来?
分析:例如:查询联系人详情时,肯定会看看该联系人的所属客户。如果我们不查的话,在用的时候还要自己写代码,调用方法去查询。如果我们查出来的话,一个对象不会消耗太多的内存。而且多数情况下我们都是要使用的。
解决: 采用立即加载的思想。通过配置的方式来设定,只要查询从表实体,就把主表实体对象同时查出来。
配置方式:
/**
* 在联系人对象的@ManyToOne注解中添加fetch属性
* FetchType.EAGER :立即加载
* FetchType.LAZY :延迟加载
*/
@ManyToOne(targetEntity = Customer.class, fetch = FetchType.EAGER)
@JoinColumn(name = "lkm_cust_id", referencedColumnName = "cust_id")
private Customer customer;
测试代码:
/**
* 对象导航查询:
* 默认使用的是延迟加载的形式查询的
* 调用get方法并不会立即发送查询,而是在使用关联对象的时候才会查询
* 延迟加载!
* 修改配置,将延迟加载改为立即加载
* fetch,需要配置到多表映射关系的注解上
*/
@Test
@Transactional // 解决在java代码中的no session问题
public void testQuery2() {
//查询id为1的客户
Customer customer = customerDao.findOne(1l);
//对象导航查询,此客户下的所有联系人
Set<LinkMan> linkMans = customer.getLinkMans();
System.out.println(linkMans.size());
}
/**
* 从联系人对象导航查询他的所属客户
* * 默认 : 立即加载
* 延迟加载:
*/
@Test
@Transactional // 解决在java代码中的no session问题
public void testQuery3() {
LinkMan linkMan = linkManDao.findOne(5l);
//对象导航查询所属的客户
Customer customer = linkMan.getCustomer();
System.out.println(customer);
}
5.2 使用Specification查询
/**
* Specification的多表查询
*/
@Test
public void testFind() {
Specification<LinkMan> spec = new Specification<LinkMan>() {
@Override
public Predicate toPredicate(Root<LinkMan> root, CriteriaQuery<?> criteriaQuery, CriteriaBuilder criteriaBuilder) {
//Join代表链接查询,通过root对象获取
//创建的过程中,第一个参数为关联对象的属性名称,第二个参数为连接查询的方式(left,inner,right)
//JoinType.LEFT : 左外连接,JoinType.INNER:内连接,JoinType.RIGHT:右外连接
Join<LinkMan, Customer> join = root.join("customer",JoinType.INNER);
return criteriaBuilder.like(join.get("custName").as(String.class),"Goo%");
}
};
List<LinkMan> list = linkManDao.findAll(spec);
list.forEach(linkMan -> System.out.println(linkMan));
}
以上是关于JPA第三天的主要内容,如果未能解决你的问题,请参考以下文章