机器学习——模型评估与选择
Posted yeshengcqupt
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习——模型评估与选择相关的知识,希望对你有一定的参考价值。
- 一些评估方法
1.留出法
它将数据集D划分为两个互斥的集合,其中一个集合作为训练集S,S的补集作为测试集T。在S上训练出模型后,用T来评估其测试误差,作为对泛化的估计。
2.交叉验证法
将数据集划分为k个大小相似的互斥子集,D=D1 U D2 U...Dk,每个子集都尽可能保持分布一致性。每次选择k-1个子集作为训练集,余下的第k个子集作为测试集合。从而获得k次训练和测试,最终返回的是k个测试结果的均值。通常称为“k折交叉验证”。
3.自助法
给定m个样本的数据集D,采样产生数据集D‘,每次随机从D中挑选一个样本,将其拷贝进入D‘(只是拷贝不是剪切)将这个过程重复m次,就得到包含m个样本的数据集D‘,此时用D‘作为训练集,用DD‘作为测试集。自助法对于数据集比较小,难以划分训练集和测试集的时候很有用。
- 性能度量方法
1.查准率、查全率、F1
首先对于算法的预测结果,可符合一些这样的情况。
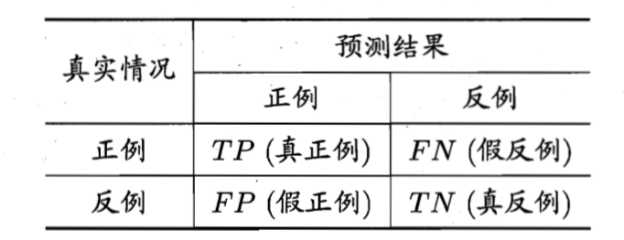
查准率(recall)P=TP/(TP+FP)
查全率(precision)R=TP/(TP+FN)
但实际上,P和R他们是矛盾的,他们成反比,因为为了更好地度量算法的性能,P-R曲线更能综合P和R的结果。(这里个人认为recall更能直观看出算法的应用性能)
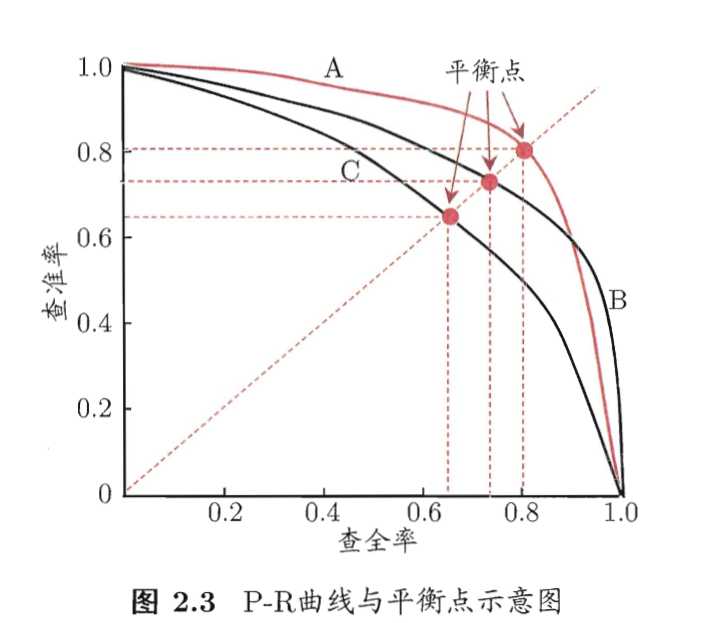
P-R曲线越饱满,算法性能越好,但为了具体比较两个类似A模型和B模型的性能,引入了平衡点(BEP)。它指的是P=R的时候P-R曲线的取值。BEP越大,则算法更好。
为了进一步比较两个算法性能,引入F1度量。
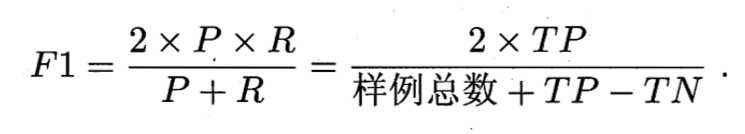
但在一些具体应用中,对P和R的重视程度有所不同。则F1度量的一般形式更能归纳不同偏好
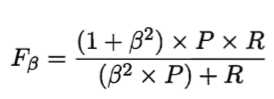
ß度量了查全率对查准率的重要性。ß=1,则退化为基本的F1度量。
以上是关于机器学习——模型评估与选择的主要内容,如果未能解决你的问题,请参考以下文章