第三章 存储器之高速缓冲存储器(超重点)
Posted by1314
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第三章 存储器之高速缓冲存储器(超重点)相关的知识,希望对你有一定的参考价值。
高速缓冲存储器(每年必考)
一、概述
1. 问题的提出
- 避免 CPU “空等” 现象
- CPU 和 主存(DRAM)之间速度的差异
| 缓存 | 主存 |
|---|---|
| 容量小 | 容量大 |
| 速度高 | 速度低 |
- 程序访问的局部性原理
- 空间的局部性(冯·诺依曼机,重复访问):空间局部性是指如果一个存储单元被访问,则该单元邻近的单元也可能很快被访问。
- 时间的局部性:时间局部性是指如果一个存储单元被访问,则可能该单元会很快被再次访问。这是因为程序存在着循环。
2. Cache 的工作原理
??Cache 保存的信息只是主存中最急需执行的若干块的副本。用主存地址的块号字段访问 Cache 标记,并将取出的标记和主存地址的标记字段相比较。若相等,说明访问 Cache 有效,称 Cache 命中;若不相等,说明访问Cache 无效,称 Cache 不命中或失效。
(1)主存和缓存的存储:主存和缓存按块存储,块的大小相同
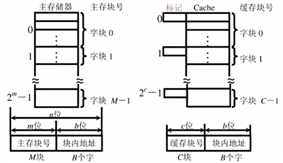
(2)命中与未命中
缓存共有 C 块,主存共有 M 块(M >> C)
-
命中:主存块调入缓存,主存块与缓存块建立了对应关系,用标记记录与某缓存块建立了对应关系的主存块号
-
未命中:主存块未调入缓存,主存块与缓存块未建立对应关系
(3)Cache 的命中率 -
CPU 访问的信息在 Cache 中的比率
-
命中率与 Cache 的容量与块长有关,一般每块可取 4~8 个字
-
块长取一个存取周期从主存调出的信息长度,同时块长取多少存储字与多体交叉也有关系
(4)Cache -主存系统的效率 -
假设 Nc 为访问 Cache 的总命中次数,Nm 为访问内存的总次数,则命中率为:h = Nc /(Nc+Nm)
-
设 Cache 命中率为 h,访问 Cache 的时间为 tc,访问主存的时间按为 tm(tc << tm)
-
平均访问时间(同步)=h × tc+(1-h) × tm ——————> 同步:地址线传输会到达Cache也会到达内存,如果数据在 Cache 中命中,那么数据直接送到 CPU ,内存不动;如果没中就到内存中传输。
-
平均访问时间(异步)=tc + (1-h) × tm ——————> 异步:首先访问 Cache,如果没命中再次访问内存,从内存中取出数据。h × tc+(1-h) × (tc+tm)
-
无特殊说明全按同步计算
-
-
效率 e 与命中率有关
- e = 访问 Cache 的时间 / 平均访问时间 × 100%
例题:假设 Cache 的工作速度是主存的5倍,且 Cache 被访问命中概率为 95%,则采用 Cache 后存储器的性能提高了多少?
设 Cache 速度为 t,内存为 5t,[(0.95×t+0.05×5t)/5t]- 1
- e = 访问 Cache 的时间 / 平均访问时间 × 100%
3. Cache 的基本结构
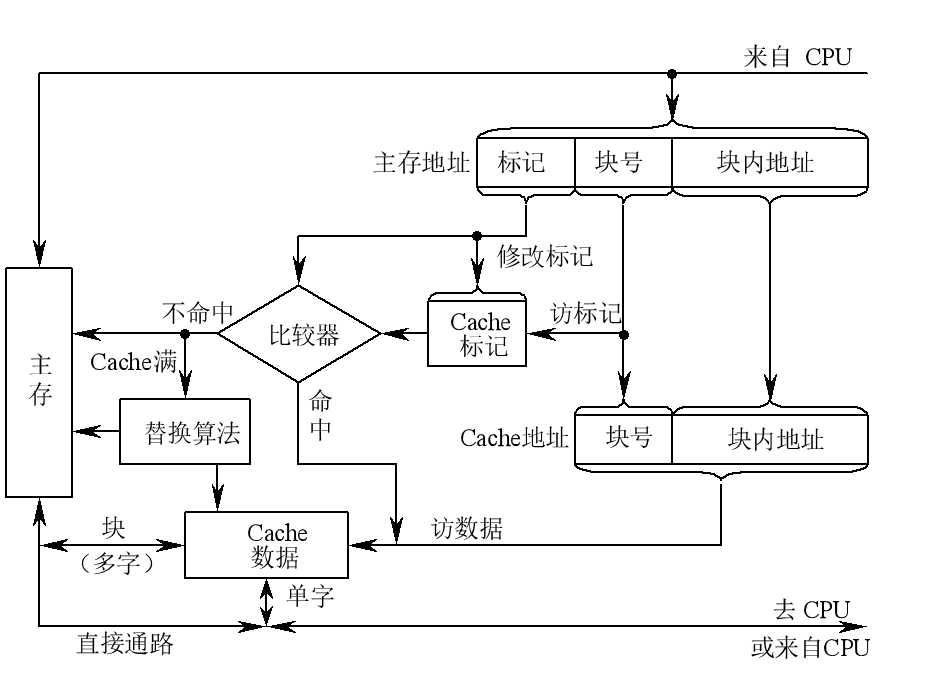
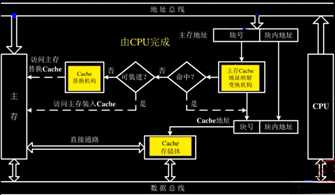
4. Cache 的读写操作
(1)Cache 的读操作
??当 CPU 发出读请求时,如果 Cache 命中,就直接对 Cache 进行读操作,与主存无关;如果 Cache 不命中,则仍需访问主存,并把该块信息一次从主存调入Cache内。若此时Cache已满,则须根据某种替换算法,用这个块替换掉Cache中原来的某块信息。
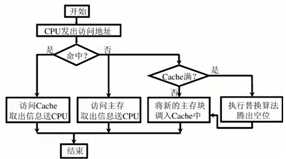
(2)Cache 的写操作
??由于 Cache 中保存的只是主存的部分副本,这些副本与主存中的内容能否保持一致,是 Cache 能否可靠工作的一个关键问题。当 CPU 发出写请求时,如果 Cache 命中,有可能会遇到 Cache 与主存中的内容不一致的问题。处理的方法有:写直达法和写回法。如果写Cache不命中,就直接把信息写入主存,并有两种处理方法:不按写分配法和按写分配法。
- 写直达法(Write through):写操作时数据写入 Cache 又写入主存
- 写操作时间就是访问主存的时间,读操作时不涉及对贮存的写操作,更新策略比较容易实现。
- 写回法(Write back):写操作时只把数据写入 Cache 而不写入主存,当 Cache 数据被替换出去时才写回主存
- 写操作时间就是访问 Cache 的时间,读操作 Cache 失效发生数据替换时,被替换的块需写回主存,增加了 Cache 的复杂性(简单的说就是我先把数据放到 Cache 中,啥时候 Cache 不要了,再将主存中的数据替换)
- 写回法在 Cache 需要增加修改位(dirty bit)与标记放在一起,不论是写回法还是写直法还需要一个有效位(存在位)与标记并行,来判断访问是否是Cache,也就是是否命中。
5. Cache 的改进(注意有的高校可能会考多级Cache的命中率)
- 增加 Cache 的级数
- 片载(片内)Cache
- 片外 Cache
- 统一缓存和分立缓存
流水线工作解决结构相关性(结构冒险)————> 把指令与数据分离即可解决- 分为指令 Cache 和数据 Cache
- 与主存结构有关
- 与指令执行的控制方式有关(是否流水)
二、Cache - 主存的地址映射
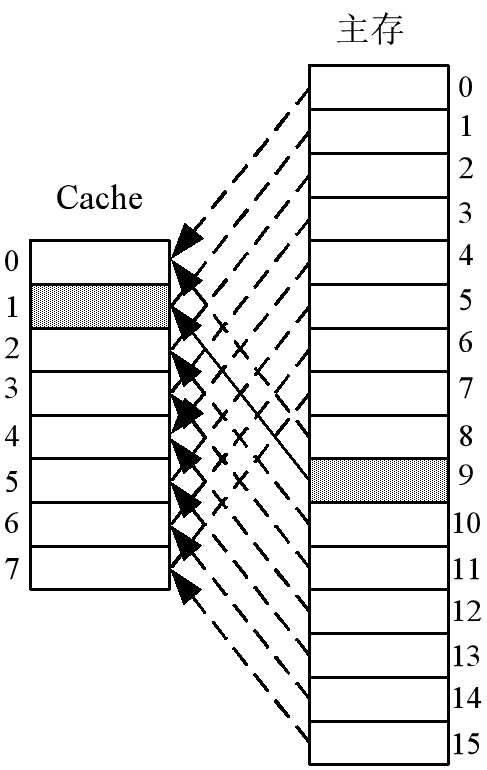
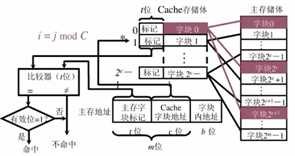
1. 直接映射
??直接映像是指主存中的每一个块只能被放置到Cache中惟一的一个指定位置,若这个位置已有内容,则产生块冲突,原来的块将无条件地被替换出去。直接映像方式是最简单的地址映象方式,成本低,易实现,地址变换速度快,而且不涉及其它两种映像方式中的替换算法问题。但这种方式不够灵活,Cache的块冲突概率最高、空间利用率最低。
- 可能会发生冲突,导致高速缓存造成浪费
??例如增加一个标记位,假如现在有 50 组[编号049]**学生要考试,每组学生10人**[学生编号000499,前两位组号,中间行号,最后一位列号],只有一个房间进行考试,该房间是10×10 座位,行列编号分别从0~9。现随机抽取组号进行考试,不巧抽取123、223、323、423进行考试,在同一座位考试究竟谁来考试??发生冲突。
- i:第 i 个缓存块,j:第 j 个主存块,C:Cache 的块数;(i=j%C)
- 每个缓存块 i 可以和若干个主存块对应
- 每个主存块 j 只能和一个缓存块对应
- 比较器后进行有效位判断,如果标记相同但里面存储内容不同,访问的是主存在 Cache 中没有命中
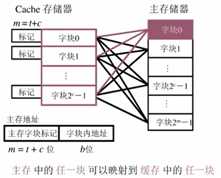
2. 全相联映像
??全相联映像就是让主存中任何一个块均可以映像装入到Cache中任何一个块的位置上。全相联映像方式比较灵活,Cache的块冲突概率最低、空间利用率最高,但是地址变换速度慢,而且成本高,实现起来比较困难。
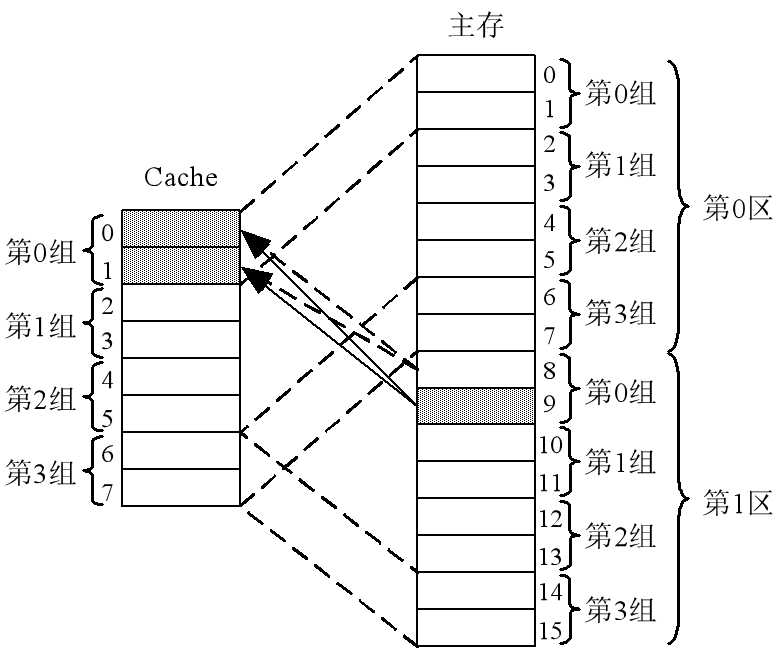
3. 组相联映射(看教材吧,主存可能不一样)
??组相联映像将主存空间按 Cache 大小等分成区后,再将 Cache 空间和主存空间中的每一区都等分成大小相同的组。让主存各区中某组中的任何一块,均可直接映像装入Cache中对应组的任何一块位置上,即组间采取直接映像,而组内采取全相联映像。
下图为:二路组相联
| 标记 | 组号 | Cache 块地址 | 字块内地址 |
|---|
主存不分组(某一主存块 j 按模 Q 映射到缓存的第 i 组中的任何一块) 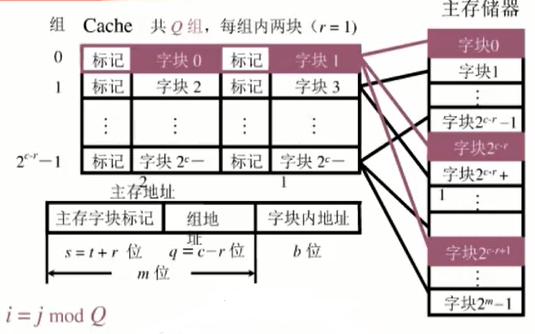 |标记|组地址|字块内地址| |---|---|---|---|
小结:
| 直接 | 某一主存块只能固定映射到某一缓存块 |
|---|---|
| 全相联 | 某一主存块能映射到任一缓存块 |
| 组相联 | 某一主存块只能映射某一缓存组中的人一块 |
三、替换算法(主要针对组相联)
1. 先进先出(FIFO)
??按调入Cache的先后决定淘汰的顺序,即在需要更新时,将最先进入Cache的块作为被替换的块。这种方法要求为每块做一记录,记下它们进入Cache的先后次序。这种方法容易实现,而且系统开销小。其缺点是可能会把一些需要经常使用的程序块(如循环程序)也作为最早进入Cache的块替换掉。
2. 近期最少使用(LRU)算法(局部性)
??LRU算法是把 CPU 近期最少使用的块作为被替换的块。这种替换方法需要随时记录Cache中各块的使用情况,以便确定哪个块是近期最少使用的块。LRU算法相对合理,但实现起来比较复杂,系统开销较大。通常需要对每一块设置一个称为“年龄计数器”的硬件或软件计数器,用以记录其被使用的情况。
四、试题
1. 假设主存容量为 512 KB,Cache 容量为 4KB,每个子块为16字,诶个字 32 位
(1)Cache 地址有多少位?可容纳多少块?
(2)主存地址有多少位?可容纳多少块?
(3)在直接映射方式下,主存的第几块映射到 Cache 的第5块(假设开始字块为第1块)?
(4)画出直接映射方式下主存地址字段中各段的位数。
解析:地址线的位数与容量有关
512KB = 219 B
4KB = 212 B
16 个字 = 24
32bit/8 = 4B = 22B
答案:
(1)由于地址线的位数与容量有关,故Cache 地址有 12 位;212/(24×22)= 64(块)
(2)19;8K
(3)第 5 个缓存块,j:第 j 个主存块,C:Cache 的块数**;(4=j%64)————> 假设开始字块为第1块
(4)
| 标记 | Cache块地址 | 块内地址 |
|---|---|---|
| 19-6=7 | 12-6=6 | 6 |
***
2. 假设主存容量为 512K×16位,Cache 容量为 4096×16位,块长为4个16位字,访存地址为字地址。
(1)直接映射方式下,设计主存地址格式
(2)全相联映射方式下,设计主存地址格式
(3)二路组相联映射方式下,设计主存地址格式
(4)若主存容量为 512×32位,块长不变,在四路组相联映射方式下,设计主存地址格式
答案:按字编址,每个字2B
(1)直接映射:Cache 地址线(地址线的位数与容量有关)= Cache块地址线 + 块内地址线
| 标记 | Cache块地址 | 块内地址 |
|---|---|---|
| 19-10=9 | 12-2=10 | 2 |
(2)全相联
| 标记 | Cache块内地址 |
|---|---|
| 17 | 2 |
(3)二路组相联,Cache块两块一组
| 标记 | Cache块地址 | 块内地址 |
|---|---|---|
| 17-9=8 | 210/2=29(二路) | 2 |
(4)块长不变,Cache块地址地址线 + 标记地址线 + 块内地址线 = 主存所需要的地址线
| 标记 | Cache块地址 | 块内地址 |
|---|---|---|
| 20-8-2=10 | 210/22=28(四路) | 2 |
注:为什么主存需要20根地址线?
若主存容量为 512×32位,按字编址
- 512KB = 219 B
- 32bit/8 = 4B = 22B
- 主存容量= 219B × 22B / 2B = 220 ————> 20根地址线
以上是关于第三章 存储器之高速缓冲存储器(超重点)的主要内容,如果未能解决你的问题,请参考以下文章