ARMR模型简单实践
Posted cheflone
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ARMR模型简单实践相关的知识,希望对你有一定的参考价值。
1.概念简述

(1)AR模型
在ARMA/ARIMA这样的自回归模型中,模型对时间序列数据的平稳是有要求的,因此,需要对数据或者数据的n阶差分进行平稳检验,而一种常见的方法就是ADF检验,即单位根检验。
平稳随机过程
在数学中,平稳随机过程(Stationary random process)或者严平稳随机过程(Strictly-sense stationary random process),又称狭义平稳过程,是在固定时间和位置的概率分布与所有时间和位置的概率分布相同的随机过程:即随机过程的统计特性不随时间的推移而变化。这样,数学期望和方差这些参数也不随时间和位置变化。
平稳在理论上有严平稳和宽平稳两种,在实际应用上宽平稳使用较多。宽平稳的数学定义为:
对于时间序列 ytyt,若对任意的t,k,mt,k,m,满足:
$$E(y_t) = E(y_{t+m})
cov(y_t, y_{t+k}) = cov(y_{t+k}, y_{t+k+m})$$
则称时间序列 ytyt 是宽平稳的。
平稳是自回归模型ARMA的必要条件,因此对于时间序列,首先要保证应用自回归的n阶差分序列是平稳的。
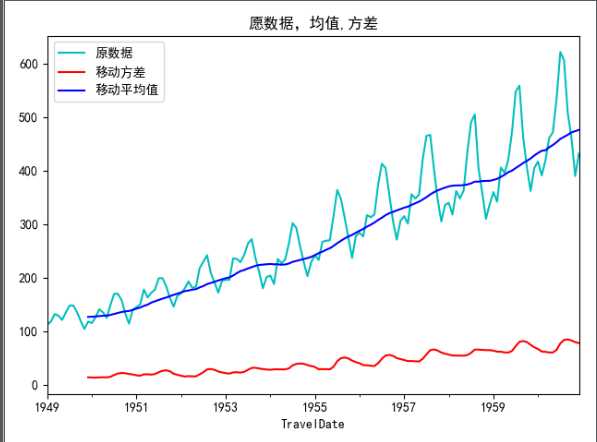
def draw_rend(timerise, size):
# print(timerise)
f = plt.figure(facecolor=‘white‘) # 画图板
rol_mean = timerise.rolling(window=size).mean() # 对数据时间移动平均计算
rol_std = timerise.rolling(window=size).std()
# rol_ = timerise.rolling(window=size).std()
timerise.plot(color=‘c‘, label=‘原数据‘)
rol_std.plot(color=‘red‘, label="移动方差")
rol_mean.plot(color=‘blue‘, label="移动平均值")
plt.title("愿数据,均值,方差")
plt.legend(loc=‘best‘)
plt.show()
def teststationayity(ts):
dftest = adfuller(ts) # 实例化检验得到数值源
# print(dftest)
dfoutput = pd.Series(dftest[0:4], index=[‘Test Statistic‘, ‘p_value‘, ‘#Lags Used‘,
‘Number of Observation Uesd‘])
# print(dfoutput)
#n阶差分
# _data=pd.Series(ts)
# data=_data.diff(1)[1:]
# # print(data)
# data.plot()
# plt.show()
# plt.savefig(‘./diff_1.svg‘)
for key, value in dftest[4].items():
dfoutput[‘Critical Value({})‘.format(key)] = value
return dfoutput
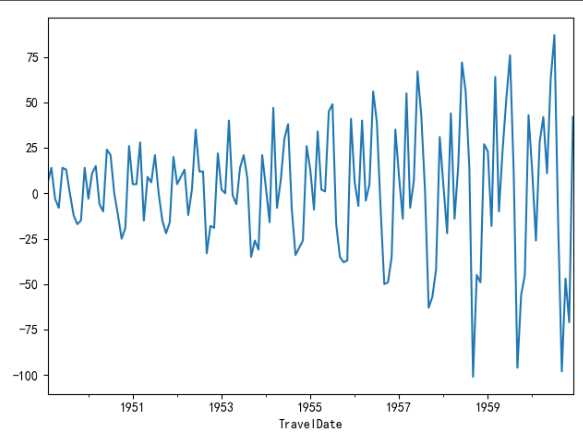
一阶差分后很明显是不平稳的波动
(差分:差分的目的主要是消除一些波动 使数据趋于平稳
你说的没错 一阶差分后的确就是增量 这还比较好解释 而有时候一阶差分都未必能达到平稳,此时还要做二阶差分 这个就很难解释意义了
所以对于多变量的时序 一般如果不平稳 我们会选择检验他们是否同阶单整然后在同阶单整的情况下做协整分析 只要有协整关系 就可以用原始数据来建模 我的理解就是放宽了平稳的要求 毕竟经济数据要平稳很多时候是难以达到的)
3.光看图没底儿,故而再瞅瞅单位根检验(adf):
(1)概念简述:
ADF检验
在使用很多时间序列模型的时候,如 ARMA、ARIMA,都会要求时间序列是平稳的,所以一般在研究一段时间序列的时候,第一步都需要进行平稳性检验,除了用肉眼检测的方法,另外比较常用的严格的统计检验方法就是ADF检验,也叫做单位根检验。
ADF检验全称是 Augmented Dickey-Fuller test,顾名思义,ADF是 Dickey-Fuller检验的增广形式。DF检验只能应用于一阶情况,当序列存在高阶的滞后相关时,可以使用ADF检验,所以说ADF是对DF检验的扩展。
单位根(unit root)
在做ADF检验,也就是单位根检验时,需要先明白一个概念,也就是要检验的对象——单位根。
当一个自回归过程中: ,如果滞后项系数b为1,就称为单位根。当单位根存在时,自变量和因变量之间的关系具有欺骗性,因为残差序列的任何误差都不会随着样本量(即时期数)增大而衰减,也就是说模型中的残差的影响是永久的。这种回归又称作伪回归。如果单位根存在,这个过程就是一个随机漫步(random walk)。
ADF检验的原理
ADF检验就是判断序列是否存在单位根:如果序列平稳,就不存在单位根;否则,就会存在单位根。
所以,ADF检验的 H0 假设就是存在单位根,如果得到的显著性检验统计量小于三个置信度(10%,5%,1%),则对应有(90%,95,99%)的把握来拒绝原假设。
ADF检验的python实现
ADF检验可以通过python中的 statsmodels 模块,这个模块提供了很多统计模型。
使用方法如下:
导入adfuller函数
from statsmodels.tsa.stattools import adfuller
adfuller函数的参数意义分别是:
x:一维的数据序列。
maxlag:最大滞后数目。
regression:回归中的包含项(c:只有常数项,默认;ct:常数项和趋势项;ctt:常数项,线性二次项;nc:没有常数项和趋势项)
autolag:自动选择滞后数目(AIC:赤池信息准则,默认;BIC:贝叶斯信息准则;t-stat:基于maxlag,从maxlag开始并删除一个滞后直到最后一个滞后长度基于 t-statistic 显著性小于5%为止;None:使用maxlag指定的滞后)
store:True False,默认。
regresults:True 完整的回归结果将返回。False,默认。
返回值意义为:
adf:Test statistic,T检验,假设检验值。
pvalue:假设检验结果。
usedlag:使用的滞后阶数。
nobs:用于ADF回归和计算临界值用到的观测值数目。
icbest:如果autolag不是None的话,返回最大的信息准则值。
resstore:将结果合并为一个dummy。
adf概念 refer 原文链接:https://blog.csdn.net/FrankieHello/java/article/details/86766625
(2)判断
adfuller(dta)后我得到的return;
Test Statistic 0.815369
p_value 0.991880
#Lags Used 13.000000
Number of Observation Uesd 130.000000
Critical Value(1%) -3.481682
Critical Value(5%) -2.884042
Critical Value(10%) -2.578770
dtype: float64
如何确定该序列能否平稳呢?主要看:
1%、%5、%10不同程度拒绝原假设的统计值和ADF Test result的比较,ADF Test result同时小于1%、5%、10%即说明非常好地拒绝该假设,本数据中,adf结果(Test Statistic)为0.8, 大于三个level的统计值。
看P-value是否非常接近0. 本数据中,P-value 为 0.99,不够接近0.
ADF检验的原假设是存在单位根,只要这个统计值是小于1%水平下的数字就可以极显著的拒绝原假设,认为数据平稳。注意,ADF值一般是负的,也有正的,但是它只有小于1%水平下的才能认为是及其显著的拒绝原假设。
对于ADF结果在1% 以上 5%以下的结果,也不能说不平稳,关键看检验要求是什么样子的。
但是对于本例,,数据是显然不平稳的了。
2020-05-24
以上是关于ARMR模型简单实践的主要内容,如果未能解决你的问题,请参考以下文章