Raft 协议
Posted buttercup
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Raft 协议相关的知识,希望对你有一定的参考价值。
Paxos 存在的问题
Paxos 算法的描述偏学术化,缺失了很多细节,没有办法直接应用于工程领域。实际工程应用中的分布式算法大多是 Paxos 的变种,验证这些算法的正确性也成为了一个难题。
举个例子:上一篇文章的 最后 介绍了一个应用 Paxos 算法的工程模型,这个模型存在明显的写性能瓶颈:
- 使用多主架构,写入冲突的概率高
- 每次更新操作都需要至少 2 轮以上的网络通信,通信开销大
为了提高这个模型的性能,仍需要在很多细节上做进一步调整,最终实现出来的算法已经和原始的版本的 Paxos 相去甚远。
为了解决以上问题,另一个高性能且易于理解的一致性算法横空出世:Raft
基本概念
Raft 算法基于 复制状态机Replicated State Machine模型,本质上就是一个管理 日志复制 的算法。
Raft 集群采用 Single Leader 架构,集群中有唯一的 Leader 进程负责管理日志复制,其职责有:
- 接受 Client 发送的请求
- 将日志记录同步到其他进程
- 告知其他进程的何时能够提交日志
复制状态机
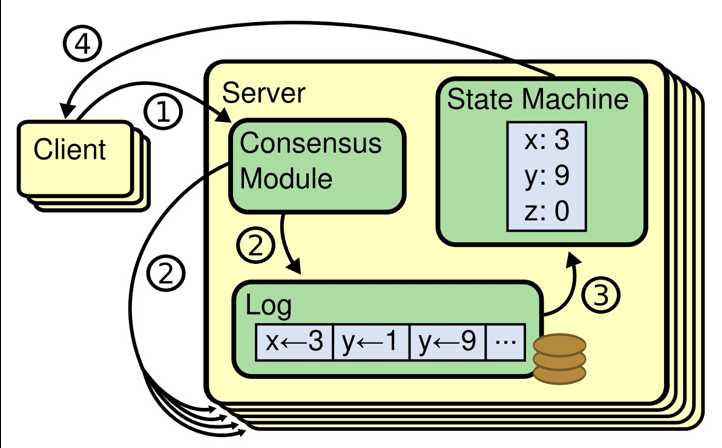
复制状态机的本质就是:Paxos + WAL
State Machine,并且使用一个日志存储其所要执行指令。
如果两个状态机执行按照相同的顺序,执行相同的指令,则这两个进程最终能够收敛到同个状态。如果能保证所有进程的日志一致,则每个进程的状态必定也是一致的。
任期
为了减少不必要的网络通信,日志追加顺序由集群唯一的 Leader 决定,无须与其他节点协商。通信开销从最低 2 次降为固定的 1 次,从而大幅提高了算法的性能。
为了保证集群的可用性,当前 Leader 下线后,集群需要从存活的节点中挑选一个新的 Leader,这个过程被称为选举 election。
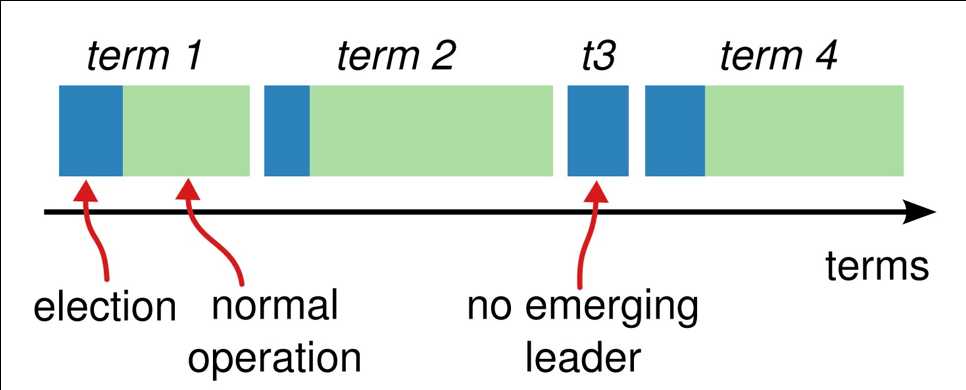
每次选举都会产生一个新的任期号 term(单调递增),如果选举中产生了一个新的 Leader,那么这个任期号会伴随这个 Leader 直到其下线。每个 参与者 进程都会维护一个 current_term 用于表示已知的最新任期,进程之间通过彼此交换该值来感知 Leader 变化。
/**
* 基础信息
*/
public abstract class RaftMember implements RaftParticipant {
// 响应 RPC 前需要持久化以下两个属性
protected final long currentTerm; // 已知的最新的 term(初始为 0)
protected final ID lastCandidate; // 最近一次赞成投票的 candidate
protected RaftMember(long term, ID candidate) {
this.currentTerm = term;
this.lastCandidate = candidate;
stableStorage().persist(currentTerm, lastCandidate);
}
/**
* @see RaftParticipant#currentTerm()
*/
@Override
public long currentTerm() {
return currentTerm;
}
/**
* @see RaftParticipant#votedFor()
*/
@Override
public ID votedFor() {
return lastCandidate;
}
}
日志
日志是 Raft 的核心概念。Raft 保证日志是连续且一致的,并且最终能够被所有进程按照日志索引的顺序提交。
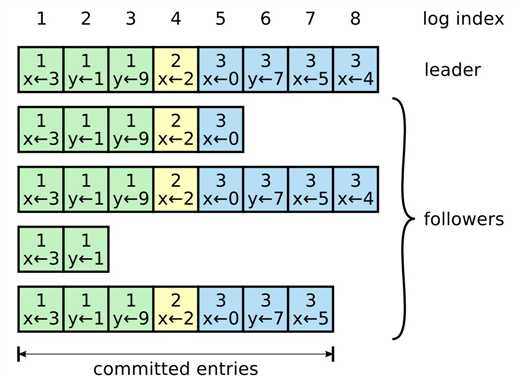
每条日志记录包含:
- 任期
term:生成该条记录的 Leader 对应的任期 - 索引
index:其在日志中的顺序 - 命令
command:可执行的状态机指令
一旦某条日志中的命令被状态机执行了,那么我们称这条记录为已提交committed,Raft 保证已提交的记录不会丢失。
角色
Raft集群中每个进程只能担任其中一个角色:
- Leader:发送心跳、管理日志复制与提交
- Follower:被动响应其他节点发送过来的请求
- Candidate:主动发起并参与选举
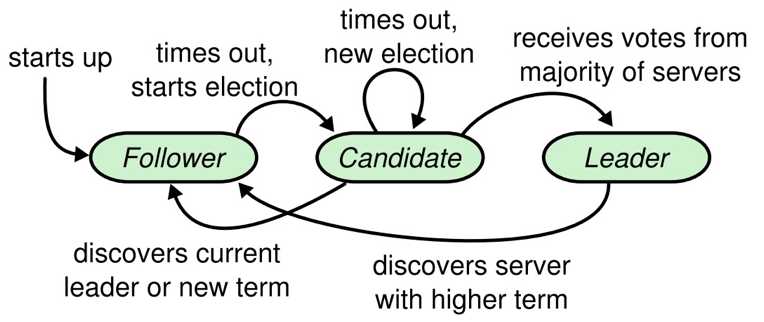
Raft 进程间使用 RPC 的方式进行通信,实现最基础的共识算法只需 两种RPC:
- RequestVote:用于选举产生 Leader
- AppendEntries:复制日志与发送心跳
/**
* RPC 接口
* */
public interface RaftService {
/**
* 复制日志+发送心跳(由 leader 调用)
* @param term leader 任期
* @param leaderId leader 在集群中的唯一标识
* @param prevLogIndex 紧接在新的之前的日志条目索引
* @param prevLogTerm prevLogIndex 对应的任期
* @param entries 日志条目(发送心跳时为空)
* @param leaderCommit leader 已经提交的日志条目索引
* @return 当 follower 中的日志包含 prevLogIndex 与 prevLogTerm 匹配的日志条目返回 true
* */
Async<RaftResponse> appendEntries(
long term, ID leaderId,
long prevLogIndex, long prevLogTerm,
Entry[] entries, long leaderCommit) throws Exception;
/**
* 选主(由 candidate 调用)
* @param term candidate 任期
* @param candidateId candidate 在集群中的唯一标识
* @param lastLogIndex candidate 最后一条日志条目的索引
* @param lastLogTerm candidate 最后一条日志条目的任期
* @return 当收到赞成票时返回 true
* */
Async<RaftResponse> requestVote(
long term, ID candidateId,
long lastLogIndex, long lastLogTerm) throws Exception;
}
算法流程
基于 Single Leader 模型,Raft 将一致性问题分解为 3 个独立的子问题:
- Leader 选举
Election:Leader 进程失效后能够自动选举出一个新的 Leader - 日志复制
Replication:Leader 保证其他节点的日志与其保持一致 - 状态安全
Safety:Leader 保证状态机执行指令的顺序与内容完全一致
为了方便理解,下面结合 动画 进行介绍。
选举
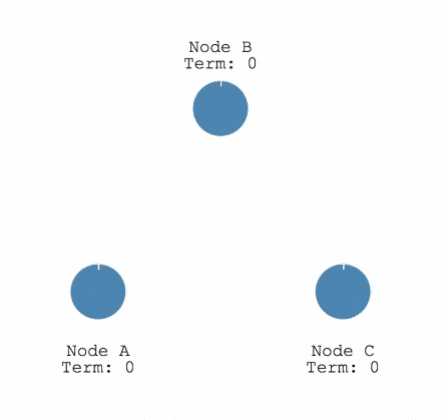
使用 心跳超时heartbeat timeout机制来触发 Leader 选举:
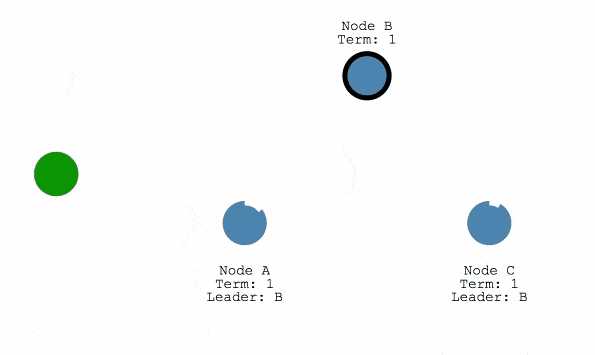
- 节点启动时默认处于 Follower 状态,如果 Follower 超时未收到 Leader 心跳信息,会转换为 Candidate 并向其他节点发起 RequestVote 请求。
- 当 Candidate 收到半数以上的选票之后成为 Leader,开始定时向其他节点发起 AppendEntries 请求以维持其 Leader 的地位。
- Leader 失效之后停止发送心跳,Follower 的心跳超时机制又会被触发,开始新一轮的选举。
复制
未提交日志 已提交日志
集群中只有 Leader 对外提供服务:
当 Leader 在接收到命令之后,首先会将命令转换为一条对应的 日志记录log entry,并追加到本地的日志中。然后调用 AppendEntries 将这条日志复制到其他节点的日志中。
当日志被复制到过半数节点上时,Leader 会将这条日志中包含的命令 提交commit状态机执行,最后将执行结果告知客户端。
网络分区
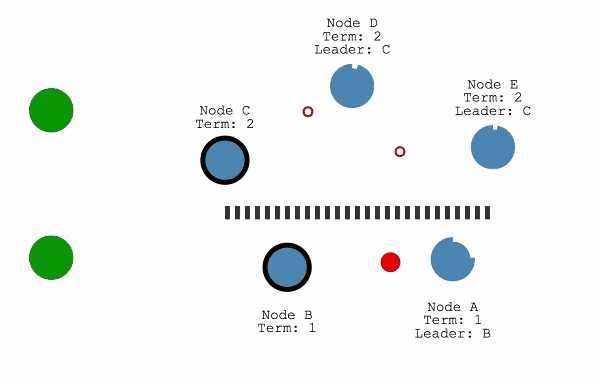
使用 过半数majority机制来处理脑裂:
如果日志无法复制到多数节点,Leader 会拒绝提交这些日志,当网络分区消失后,集群会自动恢复到一致的状态。
安全性保证
选举时…
保证新的 Leader 拥有所有已经提交的日志
- 每个 Follower 节点在投票时会检查 Candidate 的日志索引,并拒绝为日志不完整的 Candidate 投赞成票
- 半数以上的 Follower 节点都投了赞成票,意味着 Candidate 中包含了所有可能已经被提交的日志
提交日志时…
Leader 只主动提交自己任期内产生的日志
- 如果记录是当前 Leader 所创建的,那么当这条记录被复制到大多数节点上时,Leader 就可以提交这条记录以及之前的记录
- 如果记录是之前 Leader 所创建的,则只有当前 Leader 创建的记录被提交后,才能提交这些由之前 Leader 创建的日志
总结
一致性算法的本质:一致性与可用性之间的权衡。
Raft 的优点:Single Leader 的架构简化日志管理
Raft 的缺点:对日志的连续性有较高要求
限于篇幅限制,本文只展示了 Raft 算法大致的轮廓。
此前在学习算法的过程中,使用 Java 实现了一个简化版的 Raft 协议:rafting
代码忠实于论文原文,包含了其中的众多算法细节,希望对各位学习 Raft 的朋友有所帮助。
以上是关于Raft 协议的主要内容,如果未能解决你的问题,请参考以下文章