Presto入门介绍
Posted lrxvx
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Presto入门介绍相关的知识,希望对你有一定的参考价值。
Presto是由Facebook开发的一个分布式SQL查询引擎,是专门设计为用来专门进行大数据实时查询计算而设计和开发的产品。 它是为了解决Hive的MapReduce模型太慢以及不能通过BI或Dashboards直接展现HDFS数据等问题。
2、presto特点
presto是基于java开发的,对于大部分开发者和使用者而言,presto容易学习并对特定的场景进行二次开发和性能优化等。多数据源、支持SQL、扩展性强、高性能,流水线模式
-
多数据源:目前版本支持20多种数据源,几乎能覆盖所有常见情况,Elasticsearch 、Hive 、JMX 、Kafka Kudu 、Local File、Memory 、MongoDB 、mysql 、Redis等等
-
支持SQL:完成支持ANSI SQL,提供SQL shell
-
扩展性:支持开发自己的特定数据源的connector
-
高性能:presto基于内存计算,在绝大多数情况下,presto的查询性能是hive的10倍以上,完全能实现交互式,实时查询
-
流水线:presto是基于PipeLine设计的,在进行大量设计处理过程中,终端不需要等待所有的数据计算完毕之后才能看到结果,计算一部分就可以看部分结果
3、presto的基本概念和模型
3.1 服务进程
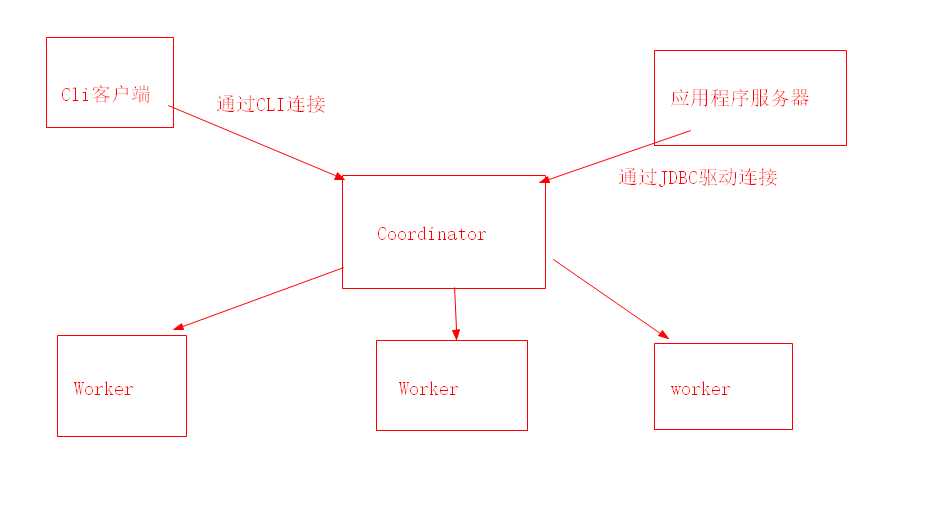
presto集群中有两种进程,Coordinator服务进程和worker服务进程。coordinator主要作用是接收查询请求,解析查询语句,生成查询执行计划,任务调度和worker管理。worker服务进程执行被分解的查询执行任务:task
3.1.1 Coordinator
Coordinator 服务进程部署在集群中的单独节点之中,是整个presto集群的管理节点,主要作用是接收查询请求,解析查询语句,生成查询执行计划Stage和Task并对生成的Task进行任务调度,和worker管理。Coordinator进程是整个Presto集群的master进程,需要与worker进行通信,获取最新的worker信息,有需要和client通信,接收查询请求。Coordinator提供RESTful服务来完成这些工作。
3.1.2 Worker
presto集群中存在一个Coordinator和多个Worker节点,每个Worker节点上都会存在一个worker服务进程,主要进行数据的处理以及Task的执行。worker服务进程每隔一定的时间会发送心跳包给Coordinator。Coordinator接收到查询请求后会从当前存活的worker中选择合适的节点运行task。
3.2 presto模型
3.2.1 Connector
presto就是通过Connector来访问不同的数据源的,相当于访问不同数据源的驱动程序,每种connector都实现了presto的标准SPI接口,因此只要实现了标准SPI接口就可以制定特殊的Connector来访问数据源。
3.2.2 Catalog
presto中Catalog类似于mysql中的一个数据库实例,Schema类似于mysql当中的一个database。如用presto去连接一个hive中的一个库
presto --server ip:port --catalog hive --schema xxx 这样就可以访问hive的中的xxx库
3.2.3 Schema
presto中的schema就相当于mysql中的一个具体的database
3.2.4 Table
presto中的table和mysql中含义一样
4、presto 整体架构
presto是一个完全基于内存的分布式查询执行引擎,presto中的服务有两种,coordinator和worker,所以presto采用的是Master-Slave的拓扑结构,同时还需要客户端
5、入门使用
presto完全支持SQL,所以对于会SQL的人员是特别容易上手的。首先确定数据源,然后确定连接方式,这里主要说cli的方式
presto --server ip:port --catalog hive --user xxxx
--server 是presto服务地址;
--catalog 是默认使用的数据源;
--user 是用户名;
进入终端后: 查看数据源: show catalogs; 查看数据库实例:show schemas;
以上是关于Presto入门介绍的主要内容,如果未能解决你的问题,请参考以下文章