《NLP中数据增强的综述,快速的生成大量的训练数据》2020-05,作者:amitness ,编译:ronghuaiyang
Posted cheesezh
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《NLP中数据增强的综述,快速的生成大量的训练数据》2020-05,作者:amitness ,编译:ronghuaiyang相关的知识,希望对你有一定的参考价值。
原文链接:https://amitness.com/2020/05/data-augmentation-for-nlp/
译文链接:https://blog.csdn.net/u011984148/article/details/106233312/
semantically invariant transformation,“语义不变变换” 使得数据增强成为计算机视觉研究中的一个重要工具。
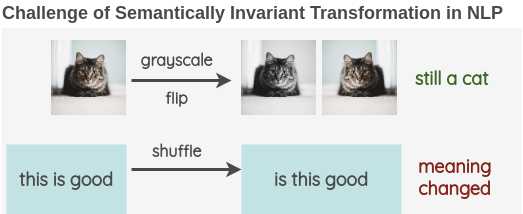
1. 词汇替换 / Lexical Substitution
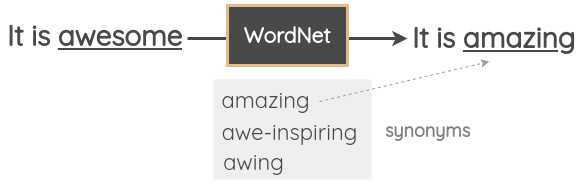
基于词典的替换 / Thesaurus-based substitution
在这种技术中,我们从句子中随机取出一个单词,并使用同义词词典将其替换为同义词。例如,我们可以使用WordNet的英语词汇数据库来查找同义词,然后执行替换。
应用案例&资源
- Zhang et al.在其2015年的论文“Character-level Convolutional Networks for Text Classification”中使用了这一技术 https://arxiv.org/abs/1509.01626
- Mueller et al.使用了类似的策略来为他们的句子相似模型生成了额外的10K训练样本 https://www.aaai.org/ocs/index.php/AAAI/AAAI16/paper/download/12195/12023
- Wei et al也使用了这个技术,作为他们论文“Easy Data Augmentation”四种随机生成策略的一种 https://arxiv.org/abs/1901.11196
- NLTK提供了对WordNet的编程接口
- 还可以使用TextBlob API
- 有一个名为PPDB的数据库,其中包含数百万条词的解释
基于词向量的替换
在这种方法中,我们采用预先训练好的单词嵌入,如Word2Vec、GloVe、FastText、Sent2Vec,并使用嵌入空间中最近的相邻单词替换句子中的某些单词。

应用案例&资源
- Jiao et al.在他们的论文“TinyBert”中使用了这种技术,以提高他们的语言模型在下游任务上的泛化能力 https://arxiv.org/abs/1909.10351
- Wang et al.使用它来增加学习主题模型所需的tweet https://www.aclweb.org/anthology/D15-1306.pdf
- 使用像Gensim这样的包来访问预先训练好的字向量和获取最近的邻居是很容易的
# pip install gensim
import gensim.downloader as api
model = api.load(‘glove-twitter-25‘)
model.most_similar(‘awesome‘, topn=5)
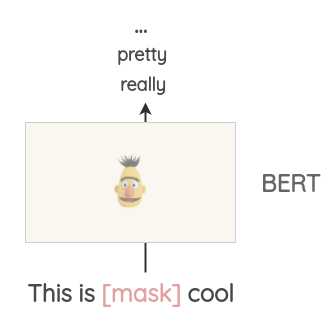
Masked Language Model
像BERT、ROBERTA和ALBERT这样的Transformer模型已经接受了大量的文本训练,使用一种称为“Masked Language Modeling”的预训练,即模型必须根据上下文来预测遮盖的词汇。这可以用来扩充一些文本。例如,我们可以使用一个预训练的BERT模型并屏蔽文本的某些部分。然后,我们使用BERT模型来预测遮蔽掉的token。 因此,我们可以使用mask预测来生成文本的变体。与之前的方法相比,生成的文本在语法上更加连贯,因为模型在进行预测时考虑了上下文。
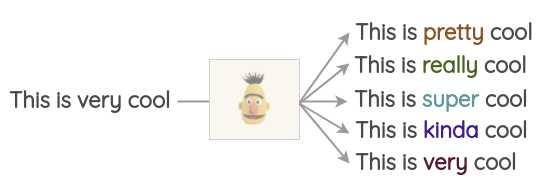
资源
- 使用开源库这很容易实现,如Hugging Face的transformers。你可以将你想要替换的token设置为
<mask>并生成预测。然而,这种方法的一个问题是,决定要屏蔽文本的哪一部分并不是一件小事。你必须使用启发式的方法来决定掩码,否则生成的文本将不保留原句的含义。https://github.com/huggingface/transformers
from?transformers?import?pipeline
nlp?=?pipeline(‘fill-mask‘)
nlp(‘This?is?<mask>?cool‘)
[{‘score‘:?0.515411913394928,
??‘sequence‘:?‘<s>?This?is?pretty?cool</s>‘,
??‘token‘:?1256},
?{‘score‘:?0.1166248694062233,
??‘sequence‘:?‘<s>?This?is?really?cool</s>‘,
??‘token‘:?269},
?{‘score‘:?0.07387523353099823,
??‘sequence‘:?‘<s>?This?is?super?cool</s>‘,
??‘token‘:?2422},
?{‘score‘:?0.04272908344864845,
??‘sequence‘:?‘<s>?This?is?kinda?cool</s>‘,
??‘token‘:?24282},
?{‘score‘:?0.034715913236141205,
??‘sequence‘:?‘<s>?This?is?very?cool</s>‘,
??‘token‘:?182}]
基于TF-IDF的词替换
这种增强方法是由Xie et al.在无监督数据增强论文中提出的。https://arxiv.org/abs/1904.12848
其基本思想是,TF-IDF分数较低的单词不能提供信息,因此可以在不影响句子的ground-truth的情况下替换它们。

要替换的单词是从整个文档中TF-IDF分数较低的整个词汇表中选择的。你可以参考原文中的代码实现:
https://github.com/google-research/uda/blob/master/text/augmentation/word_level_augment.py
https://github.com/google-research/uda
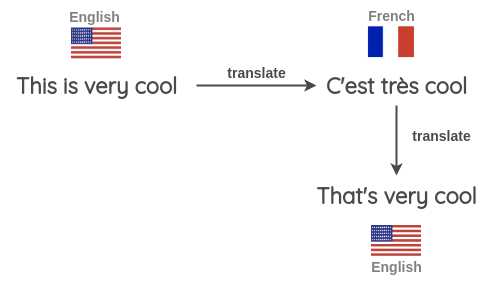
2. 反向翻译 / Back Translation
Xie et al.使用这种方法来扩充未标注的文本,并在IMDB数据集中学习一个只有20个有标注样本的半监督模型
反向翻译过程如下:
- 把一些句子(如英语)翻译成另一种语言,如法语
- 将法语句子翻译回英语句子。
- 检查新句子是否与原来的句子不同。如果是,那么我们使用这个新句子作为原始文本的数据增强。
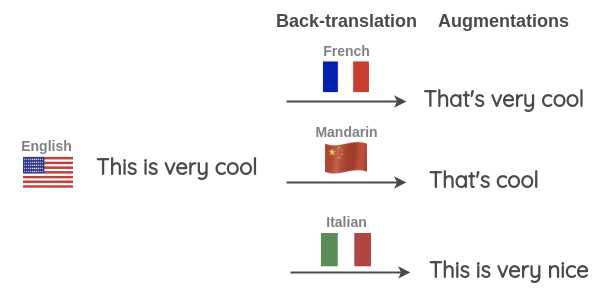
你还可以同时使用不同的语言运行反向翻译以生成更多的变体。如下图所示,我们将一个英语句子翻译成三种目标语言:法语、汉语、意大利语,然后再将其翻译回英语。
应用案例&资源
- 这项技术被用在了的Kaggle上的“Toxic Comment Classification Challenge”的第一名解决方案中 https://www.kaggle.com/c/jigsaw-toxic-comment-classification-challenge/discussion/52557
- 对于反向翻译的实现,可以使用TextBlob
- 也可以使用Google Sheets,并按照此处给出的说明:https://amitness.com/2020/02/backtransling-ingooglesheets/,免费申请谷歌翻译。
3. 文本表面转换 / Text Surface Transformation
这些是使用正则表达式的简单的模式匹配的转换,由Claude Coulombe在他的论文中介绍。 https://arxiv.org/abs/1812.04718
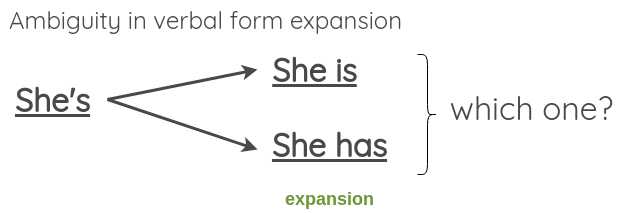
在本文中,他给出了一个将动词形式由简写转化为完整形式或者反过来的例子

既然转换不应该改变句子的意思,我们可以看到,在扩展模棱两可的动词形式时,这可能会失败
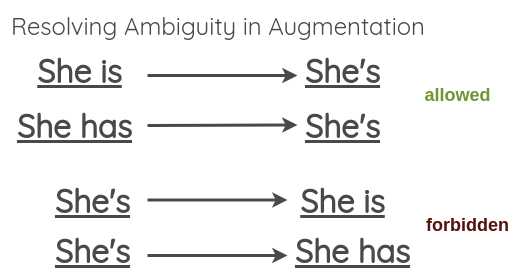
为了解决这一问题,本文提出允许模糊收缩,但跳过模糊展开。
英文缩略语列表:https://en.wikipedia.org/wiki/wiki/wikipedia%3Alist_of_english_contractions
展开库:https://github.com/kootenpv/contractions
4. 随机噪声注入 / Random Noise Injection
拼写错误注入
我们在句子中的一些随机单词上添加拼写错误。这些拼写错误可以通过编程方式添加
也可以使用常见拼写错误的映射,如:https://github.com/makcedward/nlpaug/blob/master/model/spelling_en.txt
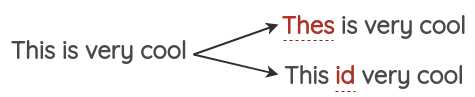
QWERTY键盘错误注入
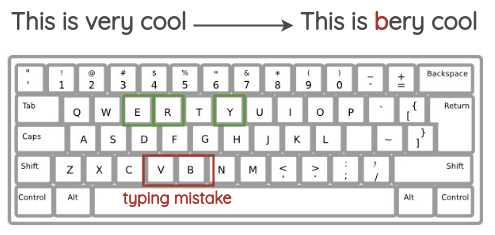
该方法试图模拟在QWERTY布局键盘上输入时发生的常见错误,这些错误是由于按键之间的距离非常近造成的。错误是根据键盘距离注入的。
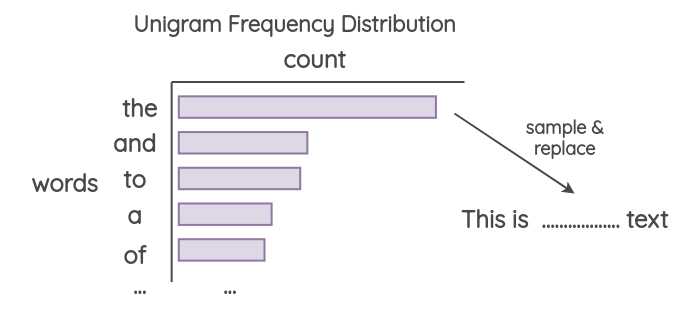
Unigram噪声
该方法已被Xie et al.( https://arxiv.org/abs/1703.02573 )和UDA论文( https://arxiv.org/abs/1904.12848 )所采用。其思想是用从单字符频率分布中采样的单词进行替换。这个频率基本上就是每个单词在训练语料库中出现的次数。
Blank Noising
这个方法是由Xie et al.在他们的论文中提出的。其思想是用占位符标记替换一些随机单词。本文使用“_”作为占位符标记。在论文中,他们将其作为一种避免特定上下文过拟合的方法,以及语言模型的平滑机制。该技术有助于提高perplexity和BLEU评分。

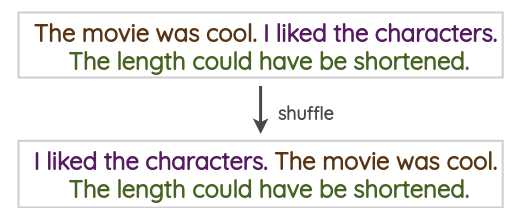
句子打乱
这是一种朴素的技术,我们将训练文本中的句子打乱,以创建一个增强版本。
随机插入 / 交换 / 删除
Easy Data Augmentation,https://arxiv.org/abs/1901.11196


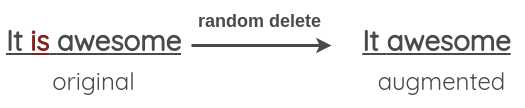
5. 实例交叉增强
这项技术是由Luque在他的关于TASS 2019情绪分析的论文中提出的。 https://arxiv.org/abs/1909.11241
这项技术的灵感来自于遗传学中发生的染色体交叉操作。
一个tweet被分为两半,相同极性的tweet可以交换一半。这样,尽管可能不符合语义,但是仍然会保留极性。
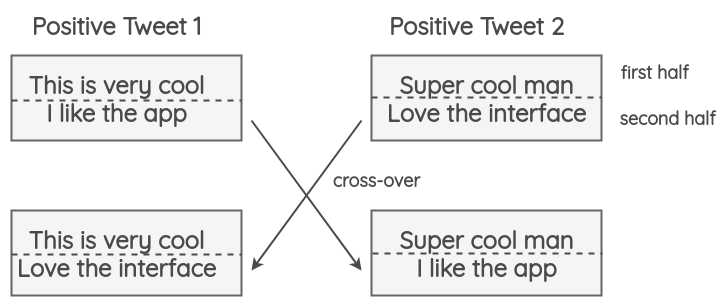
这样对acc没有影响,但是会提升F1.
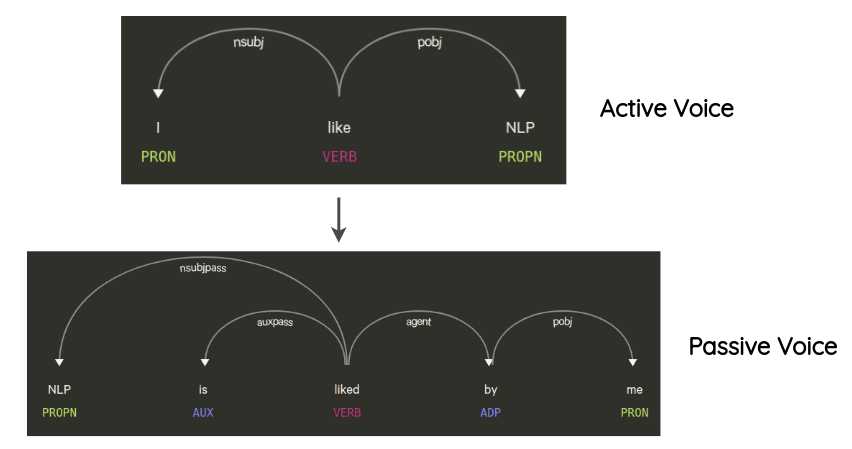
6. 操纵语法树 / Syntax-tree Manipulation
该方法由Coulombe提出,https://arxiv.org/abs/1812.04718
思想是解析并生成原句的依存语法树,然后通过规则进行转换,生成复述的句子。例如从主动句转换成被动句。
7. 文本混合
这个技术在2017年的这篇文章被提出:https://arxiv.org/abs/1710.09412
思路就是从一个mini-batch中随机挑两张图片,然后按比例合成新的图片,这些图片就合并了两个类别的信息,在训练过程中起到正则化的作用。

在NLP领域,Guo et al针对文本修改了Mixup方法,并提出了两种应用Mixup到文本的方法,https://arxiv.org/abs/1905.08941
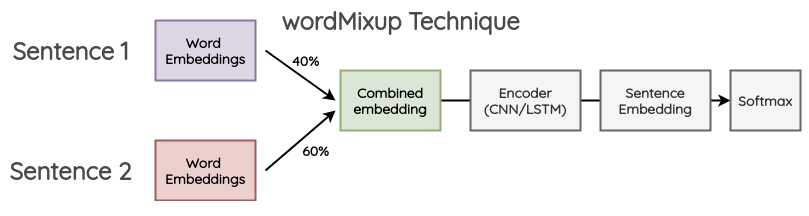
wordMixup
- 从Mini-batch中随机选2个句子,这两个句子是经过zero-pad且等长的;
- 将两个句子的word embeddings按比例合并;
- 将合并后的word embedding传入神经网络
- 交叉熵loss用于给定比例的原始文本的类别(The cross-entropy loss is calculated for both the labels of the original text in the given proportion.)
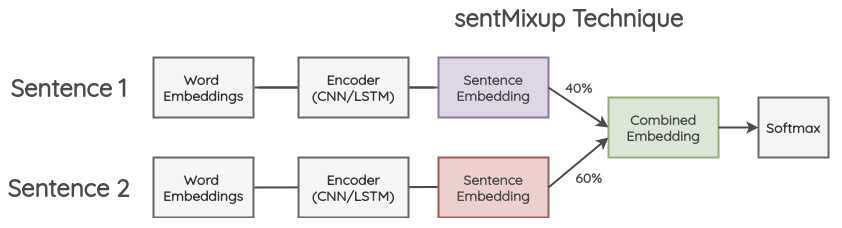
sentMixup
流程与wordMixup相似。
8. 生成模型 / Generative Methods
Conditional Pre-trained Language Models
这个技术由Kumar等人在论文 https://arxiv.org/abs/2003.02245 中提出,使用transformers模型来扩展训练数据。具体流程如下
- 在每条训练数据中前置类别标签,转换成新的数据
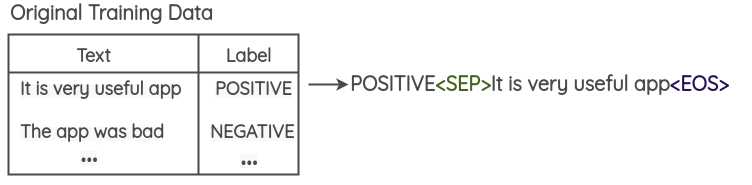
- 用新的数据微调预训练模型(BERT/GPT2/BART等),对于GPT2微调任务是generation,对于BERT微调目标是masked token prediction。

- 使用微调过的语言模型,输入类标标签和少量起始词,比如3个。

实现
https://github.com/makcedward/nlpaug
https://github.com/QData/TextAttack
References
Qizhe Xie, et al. “Unsupervised Data Augmentation for Consistency Training”
Claude Coulombe “Text Data Augmentation Made Simple By Leveraging NLP Cloud APIs”
Xiaoqi Jiao, et al. “TinyBERT: Distilling BERT for Natural Language Understanding”
Xiang Zhang, et al. “Character-level Convolutional Networks for Text Classification”
Franco M. Luque “Atalaya at TASS 2019: Data Augmentation and Robust Embeddings for Sentiment Analysis”
Ziang Xie, et al. “Data Noising as Smoothing in Neural Network Language Models”
Hongyu Guo, et al. “Augmenting Data with Mixup for Sentence Classification: An Empirical Study”
Hongyi Zhang, et al. “mixup: Beyond Empirical Risk Minimization”
Varun Kumar, et al. “Data Augmentation using Pre-trained Transformer Models”
Jason Wei, et al. “EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks”
以上是关于《NLP中数据增强的综述,快速的生成大量的训练数据》2020-05,作者:amitness ,编译:ronghuaiyang的主要内容,如果未能解决你的问题,请参考以下文章