JPA学习总结
Posted shadowdoor
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JPA学习总结相关的知识,希望对你有一定的参考价值。
JPA总结
一. 背景相关
JDK:1.8
IDE:IntelliJ IDEA
db:mysql
Spring Boot 结合 JPA
Spring Boot版本:v2.0.2.RELEASE
使用maven管理jar包
二:POM
1 <dependencies> 2 <dependency> 3 <groupId>org.springframework.boot</groupId> 4 <artifactId>spring-boot-starter-test</artifactId> 5 <scope>test</scope> 6 </dependency> 7 <!--JPA--> 8 <dependency> 9 <groupId>org.springframework.boot</groupId> 10 <artifactId>spring-boot-starter-data-jpa</artifactId> 11 </dependency> 12 <!--热部署--> 13 <dependency> 14 <groupId>org.springframework.boot</groupId> 15 <artifactId>spring-boot-devtools</artifactId> 16 <scope>runtime</scope> 17 <optional>true</optional> 18 </dependency> 19 <!--MySql数据库--> 20 <dependency> 21 <groupId>mysql</groupId> 22 <artifactId>mysql-connector-java</artifactId> 23 <scope>runtime</scope> 24 </dependency> 25 <!--Pageable使用QPageRequest需要这个--> 26 <dependency> 27 <groupId>com.querydsl</groupId> 28 <artifactId>querydsl-jpa</artifactId> 29 </dependency> 30 </dependencies> 31 32 <build> 33 <plugins> 34 <plugin> 35 <groupId>org.springframework.boot</groupId> 36 <artifactId>spring-boot-maven-plugin</artifactId> 37 <configuration> 38 <fork>true</fork> 39 </configuration> 40 </plugin> 41 </plugins> 42 </build>
三:材料准备
两张实体表 teacher、studnett
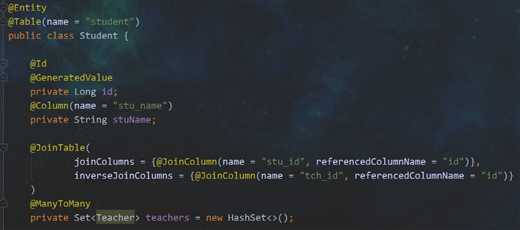
1 @Entity 2 @Table(name = "student") 3 public class Student { 4 5 @Id 6 @GeneratedValue 7 private Long id; 8 @Column(name = "stu_name") 9 private String stuName; 10 11 ....
注意: get、set方法自行完善
四. 主要总结内容
(1)Repository
(2)CrudRepository
(3)PagingAndSortingRepository
(4)JpaRepository
(5)JpaSpecificationExecutor
1. repository继承图示
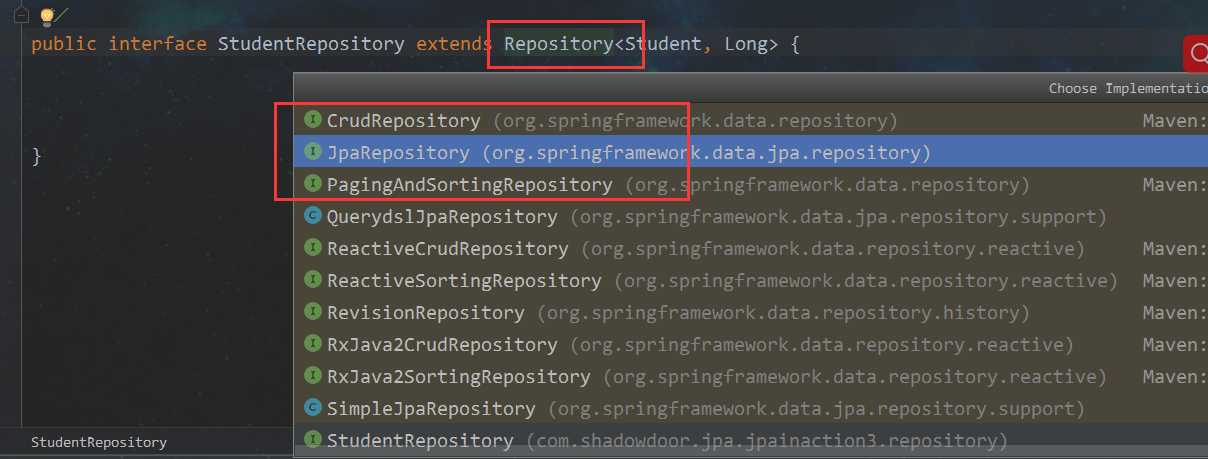
继承关系是:
JpaRepository 继承PagingAndSortingRepository,PagingAndSortingRepository继承CrudRepository,CrudRepository继承Repository
可以看出:
(1)都是接口
(2)上面的的继承关系中并没有JpaSpecificationExecutor,这个是独立的
2. Repository接口
先点进去,看看,是一个空接口,也就是一个标记接口
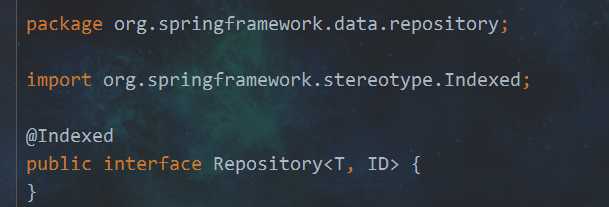
继承这个接口能干什么?查询
满足其一定的命名规范去书写方法名,可以不用自己写sql语句,直接执行查询
示例:
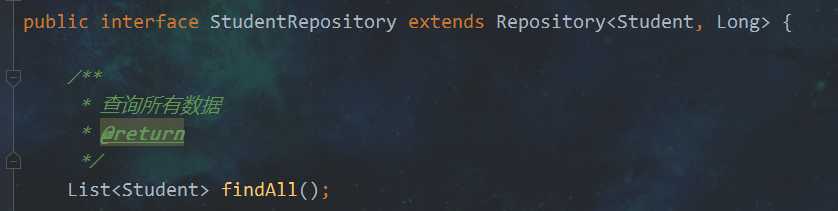
测试:
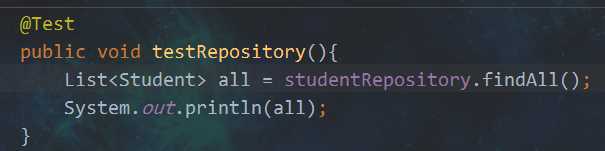
结果:

解释:
我们可以在Repository里自定义方法,但是命名规范是定死的,不是大风刮来的,比如说,方法名的开头一般以 find | get | read 为开头
看图:
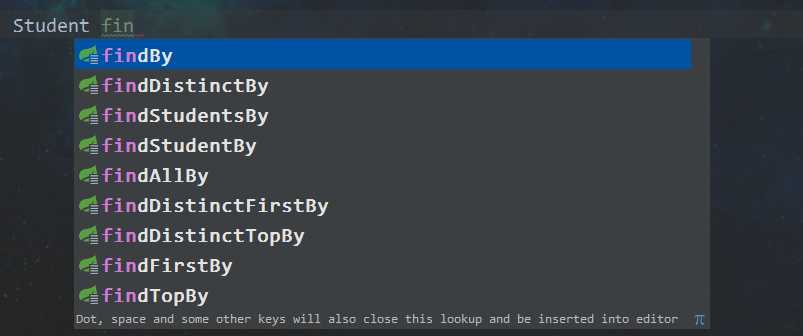
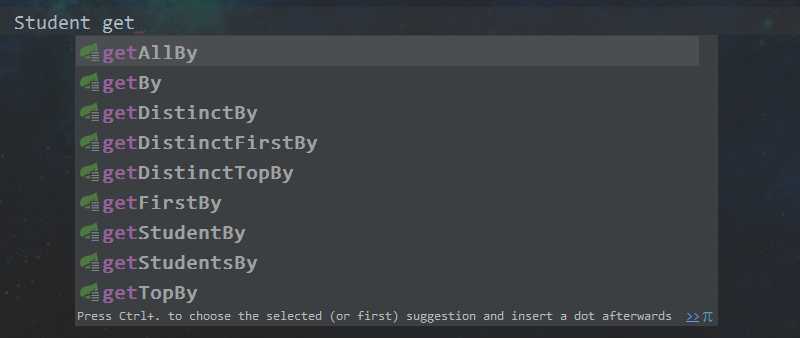
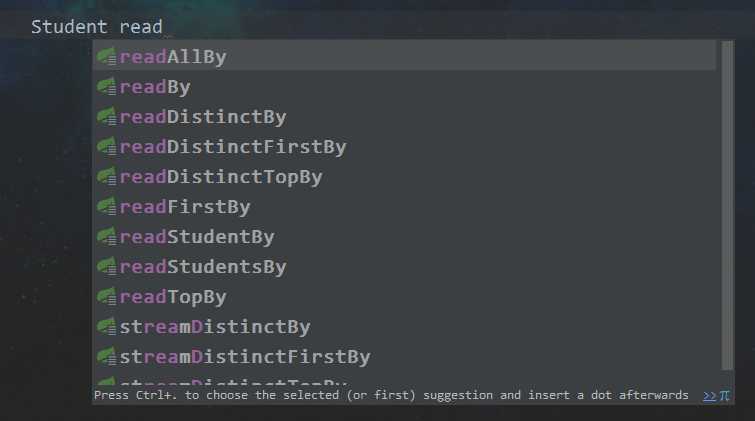
具体的命名规范,建议看官方文档https://docs.spring.io/spring-data/jpa/docs/2.0.7.RELEASE/reference/html/
总结:
自定义一个接口,继承Repository接口,满足一定命名规范书写方法名,就可以不用手写sql语句,执行查询操作
[email protected]注解
上面已经说了,继承Repository接口,即可实现查询,那么增删改查呢中的增删改呢?
好的,使用@Query注解,可以实现增、删、改。
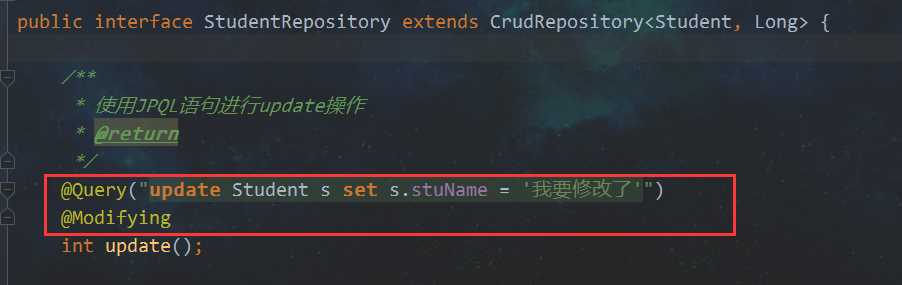
准备:A. 此时,需要书写JPQL语句,并且需要用到三个注解@Query、@Modifying、@Transactional
B. 方法分为有参和无参
(1)以更新操作为例子
1)这里先以无参方法为例,实现一个修改的操作
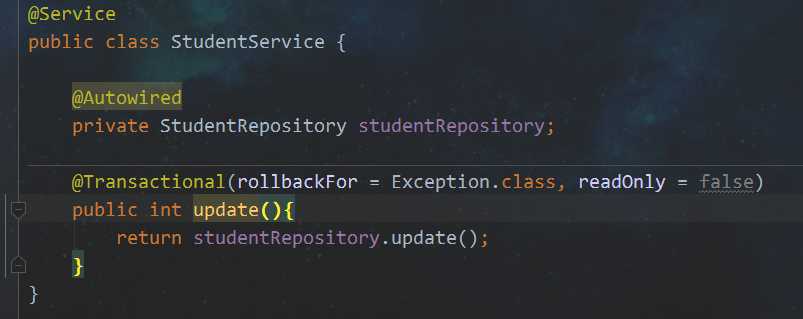
一般在service层开启注解
开始测试:
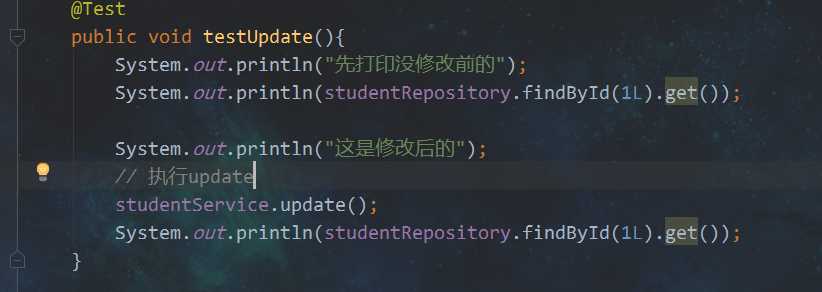
结果:

2)带参方法,实现一个修改的操作
传参方式有两种:命名参数、占位符
先来第一种:
英文的冒号 ‘ :’ ,后面加上自定义的名字,冒号和名字之间无空格
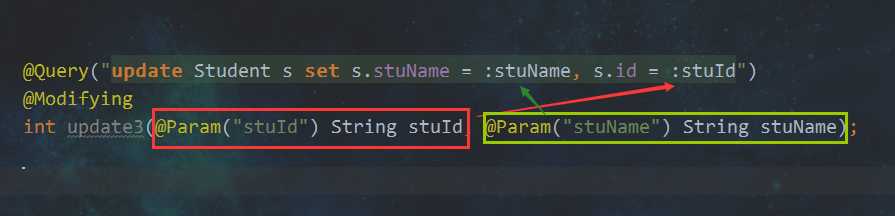
这里还漏了一点,使用命名参数传参,需要在参数中使用@Param注解,里面的值要和JPQL里定义参数名的一样
A. 使用命名参数示例:
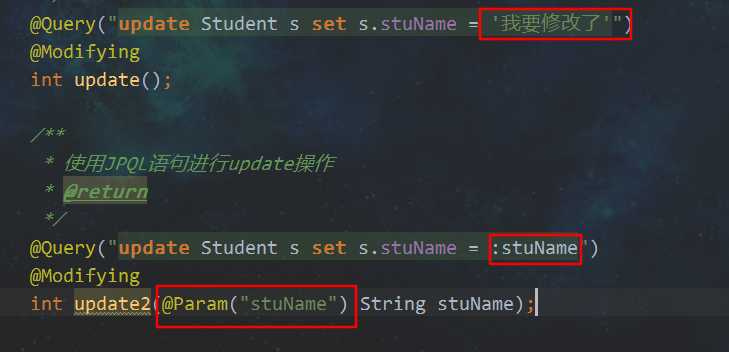
service层记住开启注解

测试:
结果:

注意:其实还有一点,这一点可以和接下来的占位符进行比较,
当有参方法有两个及以上参数时,比如下面这个

参数的传递顺序随意,因为有@Param限定好了
B. 使用占位符示例:

英文的 ‘?‘ ,后面跟着的1啊、2啊或者3456等等,组合起来就表示第一个占位符,第二个占位符...
注意:因为使用占位符,参数传递顺序严格按照JPQL语句中的顺序,不能乱,这与使用命名参数传参的不同
所以,我建议使用命名参数传参,免得错乱!
(3)如果不熟JPQL语句怎么办?用原生sql语句查询
将上面那个改造一下

nativeQuery = true 即为使用原生sql
注意:因为是原生sql语句,所有记得表名和字段都要和数据库字段属性一一对应起来
(4)为什么会有JPQL语句?为什么还支持原生sql语句?
就用官方事先实现好的,以及满足JPA命名规范的自定义方法去查询或者更新不行吗?
还真不行!
比如说,我这有个子查询,怎么查?查不了吧。。。
这里用JPQL或者原生sql就很简单

(5)like模糊查询
这里讲讲使用@Query的模糊查询,主要是 ‘%‘的用法,有两种
1)传递参数时,在参数两边用%

2)直接写在@Query里

推荐使用第二种,传参就老老实实传参,别瞎折腾
总结:
1> 记住 @Query、@Modifying、@Transactional、@Param 这四个注解的用处
2> 使用JPQL语句可以执行查询、修改、删除的操作,不能进行增加数据的操作
3> 使用原生sql语句可以实现增的操作,就是nativeQuery = true(上面忘记说了)
4> 默认情况下,spring Data 的每个方法上都有事务,但都是只读事务(read-only),是无法完成修改数据的操作行为的,所以,若是涉及到对数据进行改动的操作,请开启事务@Transactional
5> 带参方法传参有两种方式,命名参数、占位符,我个人推荐命名参数
6> like 模糊查询传参也有两种方式,个人建议直接写在JPQL语句内更好
4. CrudRepository接口
先点进去,看看,可以看出官方已经定义好了一些常用CRUD的方法
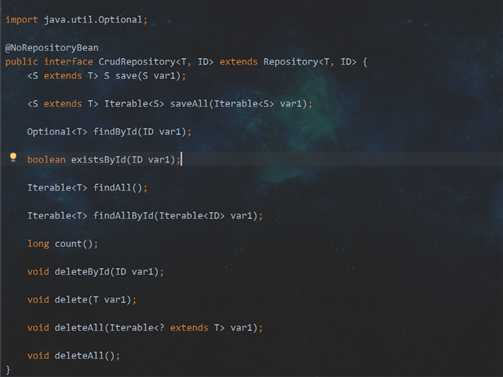
方法都是见名知义啊,就不多做解释了
举个例子吧:
之前我们已经写好一个findAll的方法,现在我把他给注释了

然后就报错了
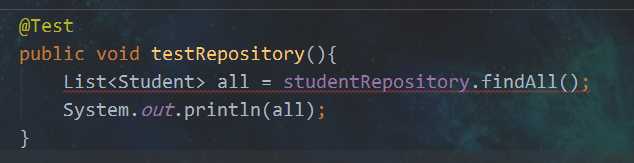
因为我的返回类型和官方的不一样

改改呗:
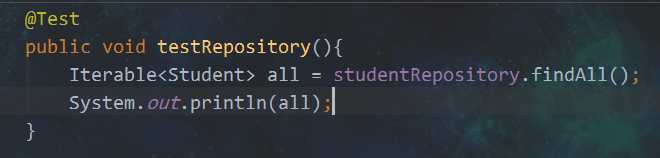
这种时候,这些简单CRUD方法,就不用自己写了,也就是说,自己既可以不用写sql,也不用写自定义方法,用官方提供的现成的就行
总结:
自定义一个接口,继承CrudRepository接口,直接就可以调用官方提供的一套现成的CRUD方法,美滋滋
5. PagingAndSortingRepository接口
这个也是见名知义的 --分页、排序用的
点进去,看看
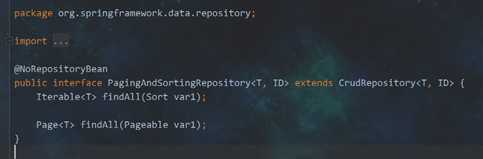
好的,来实现一个分页排序功能
在这之前,我先把之前的表删了,重新生成,再造点数据,都是官方提供的deleteAll、save方法啊
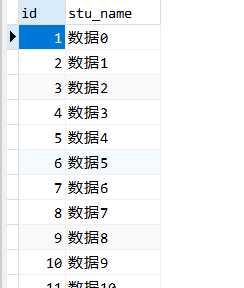
现在数据库中的数据长这样
(1)分页
我想把写好的方法给大家看看,之后再解释
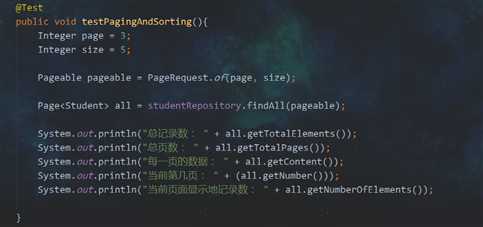
然后结果:

每页显示5条记录,第三页,id从16开始,这不扯犊子吗?id不应该从11开始吗?
这是第一个问题:page的索引是从0开始的,所以,改一下

结果:

第二个问题:这个id是从11开始了,但是这应该是第三页啊。
再改
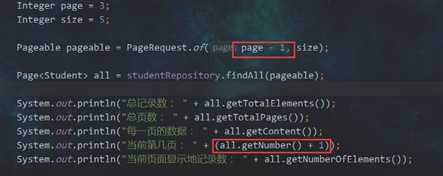

(2)分页好了,还有排序


总结:
PagingAndSortingRepository接口主要就是用来实现分页排序的
6. JpaRepository接口
老规矩,点进去看看
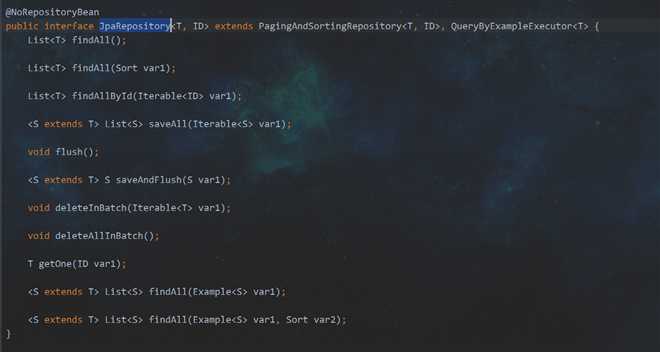
总结:
这个嘛,没什么好说的,看方法名就可以了
7. JpaSpecificationExecutor接口,最后一个
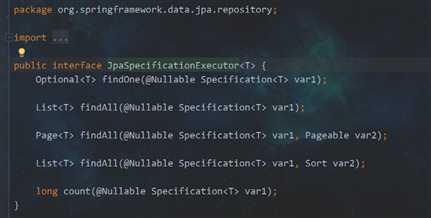
问题:他是用来干嘛的?
解释:还是用来分页,但是是用他来组合条件分页
回想一下上面实现的分页功能,除了传进去一个起始页和一个每页显示记录数以及排序条件,还传了什么?
没了,就这三个。够用吗,不够啊。
我想带个参数模糊查询不给啊?
我想带个id比较比较不给啊?
OK!
在上面实现分页的基础上,我增加两个条件,一个是模糊查询,一个是id比较
先看,之后我再解释
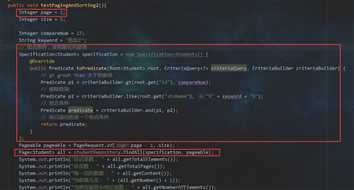
结果:

解释一下:
root: 代表查询的实体类。(这里即为Student)
criteriaQuery: 可以从中可到Root对象,即告知JPA Criteria查询要查询哪一个实体类, 还可以来添加查询条件,还可以结合EntityManager对象得到最终查询的TypedQuery对象。
CriteriaBuilder : 用于创建Criteria 相关对象的工厂。当然可以从中获取到Predicate对象
Predicate 类型,代表一个查询条件。
或者再将上面改改,毕竟参数都是传递过来的,不是大风刮来的
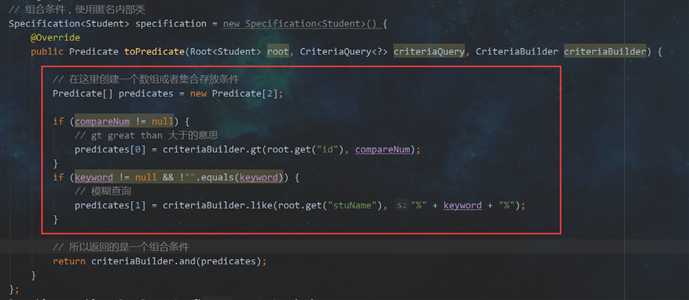
其实这样还是有问题,思考一下,由于业务的变更,需求变更,即要判断的条件可能更多了
这种时候,一开始就用一个数组存放条件不够优雅,毕竟数组的大小是写死的
来来来,换成集合走一波
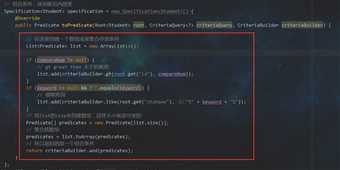
总结:
当你想用组合条件分页查,继承JpaRepository<T, ID>, JpaSpecificationExecutor<T>呗
综上,
日常使用,自定义一个接口,继承JpaRepository接口,
又想组合条件分页查,继承JpaSpecificationExecutor接口
以上是关于JPA学习总结的主要内容,如果未能解决你的问题,请参考以下文章