聊聊我的知识体系
Posted chanshuyi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了聊聊我的知识体系相关的知识,希望对你有一定的参考价值。
不知不觉树义已经工作 5 年了,一路走来磕磕碰碰但总算有了自己的一点小体会。对于一个 Java 开发人员来说,到了 5 年的关键节点,需要掌握哪些知识点呢?经过我自己的总结,我列出了下面的思维导图。
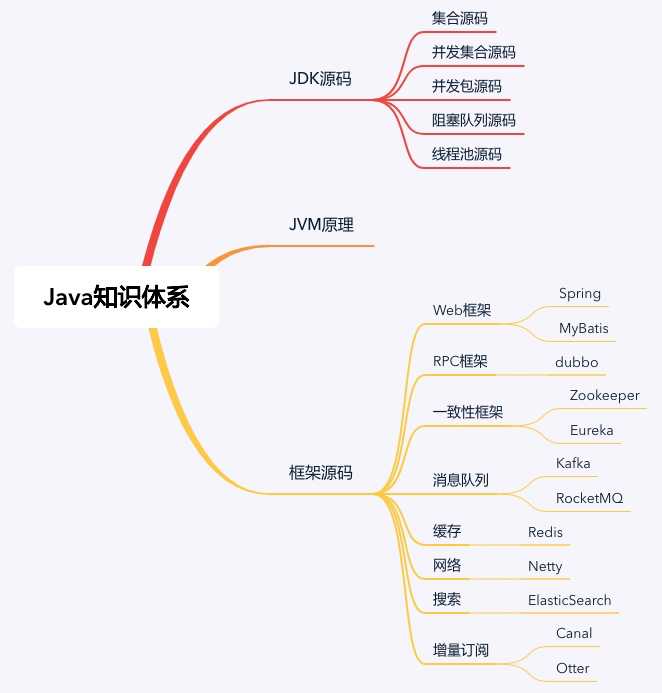
从上面的图片我们可以看出大致分为三个部分:JDK 源码、JVM 原理、框架源码。
JDK源码
JDK 源码是一切的基础,许多框架都参考了 JDK 源码的实现思路,因此弄懂 JDK 源码是一件非常重要的事情。而 JDK 源码又可以分为下面 4 大块:
- 集合源码
- 并发集合源码
- 并发包源码
- 阻塞队列源码
- 线程池源码
集合源码
说到集合,我们大家都非常熟悉,这可是我们工作中用得非常多的一类 API。但会用了,还得知道它到底是如何实现的,这样才可以避免踩坑。JDK 源码中的集合并不是特别多,大概有 四大类大概 14 个常用的 API。
List集合
- ArrayList:列表集合经典实现。
- Vector:列表集合经典实现,线程安全,与 ArrayList 对应。
- LinkedList:链表结构的经典实现。
- Stack:栈结构的经典实现,先进后出的数据结构。继承了 Vector,线程安全。
Set集合
- HashSet:Set 集合的哈希实现。
- LinkedHashSet:Set 集合的哈希实现,维护了元素插入顺序。
- TreeSet:Set 集合的有序实现。
Queue集合
- PriorityQueue:优先级队列
- LinkedList:双向队列实现
- ArrayDeque:双向循环队列实现
Map集合
- HashMap:Map 集合的经典哈希实现。
- LinkedHashMap:在 HashMap 的基础上,增加了对插入元素的链表维护。
- WeakedHashMap:在 HashMap 的基础上,使强引用变为弱引用。
- TreeMap:Map 集合的有序实现。底层是红黑树的经典实现。
在这 14 个常用的 API 中虽然有一些我们还没使用过,但如果你要建立起一套完整的知识体系,那么还是有必要去仔细琢磨一下它们的作用,并且对它们进行横向比较的。
并发集合源码
我们前面说到的集合源码,它们大部分都是线程不安全的,它们在多线程的环境下使用会产生各种各样的问题。而线程安全与并发安全又不一样,线程安全考虑的是绝对的安全,而并发安全则是牺牲部分特性来提高并发效率。也就是说并发集合适合在多线程环境下使用,并且效率足够高,能够应对高并发的情况。
在 JDK 的并发集合源码中,一共有 7 个常用的并发集合。
- ConcurrentHashMap:高并发的HashMap
- ConcurrentSkipListMap:高并发下的TreeMap(基于跳表实现)
- ConcurrentSkipListSet:内部使用ConcurrentSkipListMap实现
- CopyOnWriteArrayList:高并发的ArrayList,适合读场景。
- CopyOnWriteArraySet:高并发的Set集合,使用CopyOnWriteArrayList实现。
- ConcurrentLinkedQueue:高并发的链表队列。
- ConcurrentLinkedDeque:高并发的双向链表队列。
虽然有 7 个并发集合,但是实际上只有 5 个左右,因为另外两个都直接用代理的方式委托实现。例如:CopyOnWriteArraySet 类内部并没有具体的逻辑实现,而是直接委托 CopyOnWriteArrayList 实现。
并发包源码
我们前面说过许多集合都是线程不安全的,在多线程环境、甚至高并发环境需要使用并发集合。那么并发集合到底是怎么实现线程安全的呢?在 JDK1.8 之后,并发集合大部分都使用 CAS 来实现线程安全。而其实在 JDK1.8 之前,许多线程安全都是使用锁来实现的。而说到锁,我们就必须了解一下并发包源码。
并发包源码从零开始定义了一整套实现并发安全的机制,并且还提供了不少方便使用的并发工具。我们通过并发包就可以非常方便地实现多线程下的线程安全和并发控制,后面说到的阻塞队列都是以这个为基础的。
并发包是一整套接口和实现的定义,其主要的类和实现如下:
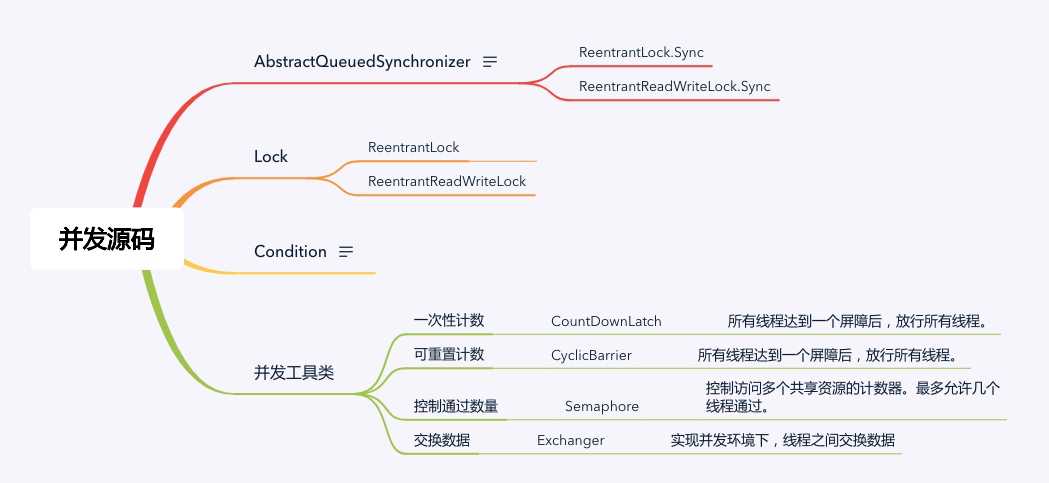
在并发源码最顶层的是 AbstractQueueSynchronizer 接口,其定义了并发控制最为基础的几个接口,之后的 Lock、ReentrantLock、ReentrantReadWriteLock 都是在这基础上实现的。而 Condition 接口则是继 AbstractQueueSynchronizer 接口之后的另一个重要接口,其定义了分支条件,使得并发适用于更复杂的业务。
定义好了 AbstractQueueSynchronizer 和 Condition 接口,并发包的基础就搭建好了。并发包中提供了 CountDownLatch、CyclicBarrier 等并发工具类来实现常用的并发操作,这些工具类都是使用前面提到的 Lock 来实现的。
阻塞队列源码
阻塞队列其实是属于并发包的一部分,但因为其功能性特别明显,所以我们专门挑出来单独说。阻塞队列用于在高并发环境下进行数据的交换,其实现基础是我们前面说到的并发包,没有并发包就没有阻塞队列。
在 JDK 中,阻塞队列一共可以分为三大类一共 8 个常用的阻塞队列。
基础实现
这块是阻塞队列最基础的实现
- ArrayBlockingQueue:数组组成的有界阻塞队列
- LinkedBlockingQueue:链表组成的无界阻塞队列
- LinkedBlockingDeque:链表组成的双向阻塞队列
有序延迟实现
这块的阻塞队列还实现了元素的排序以及延迟功能,只有时间到了才能出队列。
- PriorityBlockingQueue:支持优先级排序的无界阻塞队列
- DelayQueue:支持优先级实现的无界延迟阻塞队列
- DelayedWorkQueue:线程池中的延迟阻塞队列
数据交换实现
这块阻塞队列主要用于多线程之间的数据交换
- SynchronousQueue:不存储元素的数据交换阻塞队列
- LinkedTransferQueue:链表组成的数据交换无界阻塞队列

线程池源码
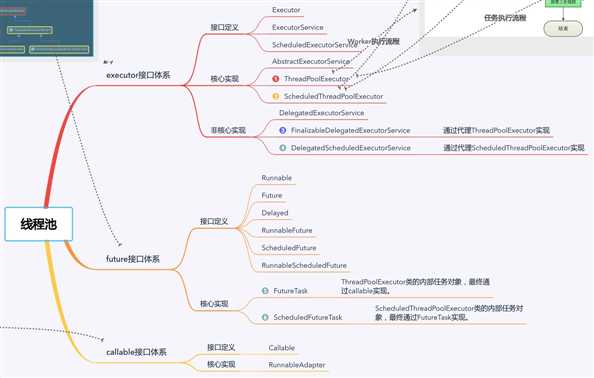
线程池也是 JDK 源码中非常重要的一块,妥善利用线程池可以提高效率。而线程池的基础其实就是我们前面讲到的阻塞队列,线程池的延迟功能都是使用阻塞队列实现的。线程池的整体架构比较多,但是并不复杂,也没有什么难点。如果弄懂了线程池的整体类结构,那么线程池也就没什么太大的问题了。
JVM原理
JVM 可以说是 Java 程序员必须要掌握的基础知识了。初学者或许会搞不懂这些东西到底有什么用,一开始学习都是为了面试用。但老司机告诉你学习 JVM 原理有下面两个非常重要的用处:
- 理解 Java 语言特性。Java 代码写出来的只是语言层面的东西,当我们要了解一个特性是如何实现的,我们就需要深入到字节码层面。例如:boolean 这个类型,在 Java 语言层面是存在的。但是其在字节码层面是不存在的,其在字节码层面是使用 Integer 的 1 和 0 表示 true 和 false。
- 学习排查线上问题。我们遇到线上 JVM 问题,经常提示说:
OutOfMemoryError: Java heap space。这时候你会不知道从何入手,这是因为你不懂 JVM 的内存结构。所以你必须去学习 JVM 的内存结构,如何排查问题发生在哪块内存,如何解决问题。而这一切的基础就是 JVM 的基础知识。
关于 JVM 的基础知识,我写了一个系列的文章来介绍,有兴趣的可以阅读以下:JVM系列文章
框架源码
学习完 JDK 的源码,我们就需要把我们常用的框架源码都弄清楚。这样在遇到框架问题的时候,我们才可以快速地排查问题。
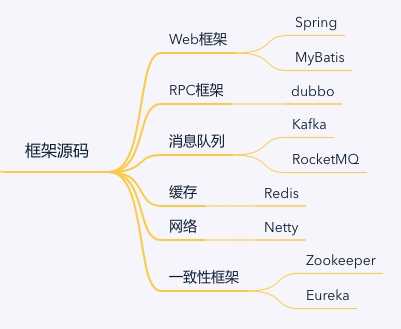
上面的思维导图从上到下都是逐次递进的。我们学习了 JDK 源码,再学习 Web 框架就可以实现简单的 Web 项目。而随着业务增长,我们需要加入 RPC 服务化框架将其服务化。而随着业务复杂化和井喷,我们需要加入消息队列和缓存来进一步提高业务的稳定性。
Web框架
Spring 和 MyBatis 可以说是 Java Web 开发者必学的两个框架了,因此对这两个框架有必要做一个深入的了解。
对于 Spring 来说,其整个源码体系太过于复杂,所以我们还是得抓住重点。对于 Spring 来说,最重要的是其 AOP 和 IoC 的实现,以及其容器体系和常用的接口。而对于 MyBatis 来说,其体系相对没有 Spring 那么复杂,所以可以稍微深入一些。
RPC框架
在所有 RPC 框架中,dubbo 可以说是最通用的一个了。所以如果你所在的公司没有自研的 RPC 框架,那么你不妨可以将 dubbo 作为你的学习框架。
对于 RPC 框架来说,其实无非就是封装对象代理,最后通过与服务提供者进行网络通信。但是如何进行封装,如果进行负载均衡的实现,这就考验一个框架设计者的功力了。
一致性框架
对于分布式系统,非常重要的一个组件就是一致性框架。在这些框架中,最常见的两个是 Zookeeper 和 Eureka。Zookeeper 实现了 CAP 中的 CP(即注重强一致性),而 Eureka 则是实现了 CAP 中的 AP(即注重可用性)。
虽然平常我们都将 Zookeeper 和 Eureka 作为服务化的协调组件,基本上没有什么机会深入学习。但是有机会还是可以深入了解一下的。
消息队列
消息队列可以说是实现业务解耦以及突发流量的利器。而在大型业务场景中,最常用的就是 Kafka 和 RocketMQ 了,因此弄懂这两个消息队列的原理基本上就足够用了。
对于消息队列,建议先选择一个深入研究,先弄懂其基本原理,之后再阅读源码验证想法。因为 RocketMQ 是基于 Kafka 改进的,所以建议先从 Kafka 入手研究。Kafka 研究得差不多了,RocketMQ 的研究也会进展飞速。
缓存框架
缓存框架可以说是高并发下必用的一个框架了,但我们经常只是使用它,而不知道起内部的原理和构造。因此找个时间深入学习下原理,还是很有必要的。
网络框架
对于一些网络项目,例如聊天 IM 等,就需要用到 Netty 等框架。而 Netty 又是这类网络框架的佼佼者,通过对其源码的研究,可以学到不少知识。
搜索框架
对于一些搜索功能的项目,单纯的数据库 SQL 查询已经无法满足需求了,这时候 ElasticSearch 的学习和研究就提上议程了。有时间的话,研究学习一下还是很有必要的。
增量订阅框架
Canal 和 Otter 框架可以帮助你获得数据库的变化信息,从而更方便地做业务扩展。对于这类框架,属于特定领域的细分框架,有时间可以研究一下。
总结
作为一个工作了 5 年的开发,上面的知识体系还是未能完全消化,只能说是对于部分有些掌握。如果你也想构建自己的知识体系,那么我建议你可以按照我列出的顺序去学习。先研究学习 JDK 源码,之后学习 JVM 原理,最后再去研究学习框架源码。而框架源码的研究也从该框架的常用程度排序,对于 ElasticSearch 这类不常用的,可以放在后面。而对于 Spring 这些用得很多的,则需要放在前面。
今天也只是简略地提了一下整个知识体系,后续有空闲时间会继续慢慢分享相关文章。有兴趣的朋友不妨关注一下我,这样能及时查看后续文章。
以上是关于聊聊我的知识体系的主要内容,如果未能解决你的问题,请参考以下文章