urllib库的应用及简单爬虫的编写
Posted whliscoming
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了urllib库的应用及简单爬虫的编写相关的知识,希望对你有一定的参考价值。
1、urllib库基础
1.1爬虫的异常处理
常见状态码及含义
301 Moved Permanently:重定向到新的URL,永久性
302 Found:重定向到临时的URL,非永久性
304 Not Modified:请求的资源未更新
400 Bad Request:非法请求
401 Unauthorized:请求未经授权
403 Forbidden:禁止访问
404 Not Found:没有找到对应页面
500 Internal Server Error:服务器内部出现错误
501 Not Implemented:服务器不支持实现请求所需要的功能
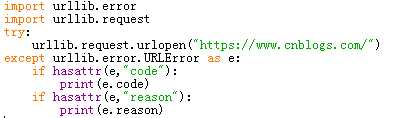
URLError与HTTPError都是异常处理的类,HTTPError是URLError的子类,HTTPError有异常状态码与异常原因,URLError没有异常状态码。不能用URLError直接代替HTTPError,如果要代替,必须要判断是否有状态码属性。
URLError:
1、连不上服务器
2、远程的URL不存在
3、本地没有网络
4、触发了HTTPError(因为HTTPError是它的子类)
1.2爬虫的浏览器伪装技术
想要伪装成浏览器,必须为爬虫添加报头信息。打开浏览器进入网页,F12中network中找到user-agent及其后面的内容,然后创建opener对象,把opener添加为全局(urllib.request.install_opener(opener))。

1.3设置代理服务器

2、爬虫实战
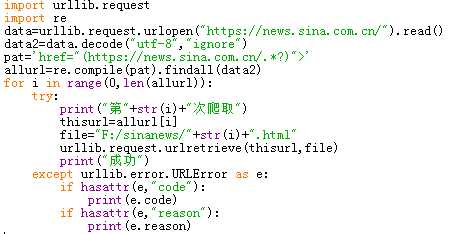
2.1将新浪新闻首页的所有新闻都爬到本地
进入新浪新闻首页,查看网页源代码,根据每个新闻链接的相似度,构造求新闻链接的正则表达式,接着再将网页全部写入到本地。
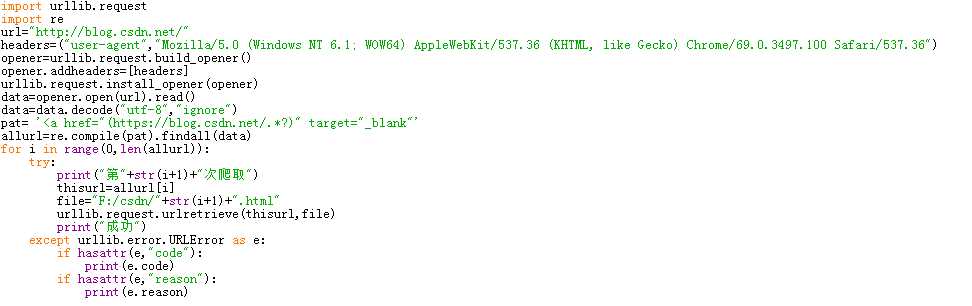
2.2爬取CSDN博客(http://blog.csdn.net/)首页显示的所有文章,每个文章内容单独生成一个本地网页存到本地中。
利用浏览器伪装技术,先爬首页,通过正则表达式筛选出所有文章的url,然后通过循环把这些url下载到本地。
3、爬取网站图片
3.1爬取淘宝网任意搜索目录下高清图
本次爬取淘宝的搜索关键词为“短裙”,在淘宝搜索短裙进入搜索结果页面。对该页面网址及下几页网址进行分析,找出url构造规律。对源代码中进行分析,注意找到图片的url,此时要特别注意图片必须要高清而不是略缩图,这同样需要注意图片地址。利用正则表达式对提取到的信息进行筛选,最后将得到的图片编号存储到本地。

由于是爬取多页的信息,如果对循环不太熟悉的话,可以先爬取一页的图片,然后找出循环的规律在对规定的页数进行循环爬取图片。
3.2对千图网任一类图片进行爬取
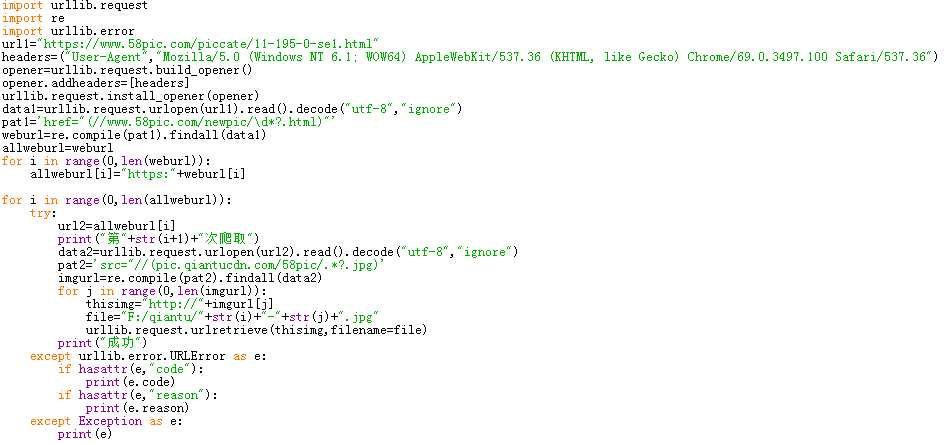
一定要进行异常处理,不然程序很容易崩。尽量每次爬取后都输出一些文字提示,以此来了解进度。
以上是关于urllib库的应用及简单爬虫的编写的主要内容,如果未能解决你的问题,请参考以下文章