爬虫模块介绍--Beautifulsoup
Posted shizhengquan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫模块介绍--Beautifulsoup相关的知识,希望对你有一定的参考价值。
Beautiful Soup 是一个可以从html或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间.你可能在寻找 Beautiful Soup3 的文档,Beautiful Soup 3 目前已经停止开发,官网推荐在现在的项目中使用Beautiful Soup 4, 移植到BS4
#安装 Beautiful Soup pip install beautifulsoup4 #安装解析器 Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,其中一个是 lxml .根据操作系统不同,可以选择下列方法来安装lxml: $ apt-get install Python-lxml $ easy_install lxml $ pip install lxml 另一个可供选择的解析器是纯Python实现的 html5lib , html5lib的解析方式与浏览器相同,可以选择下列方法来安装html5lib: $ apt-get install Python-html5lib $ easy_install html5lib $ pip install html5lib
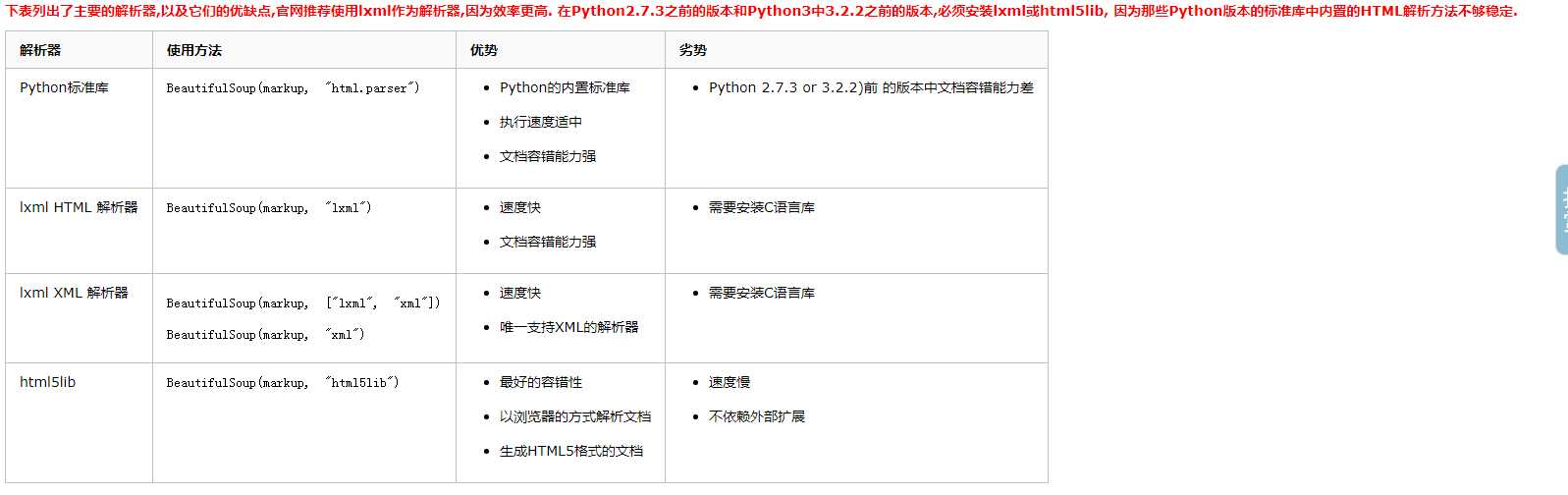
以上是关于爬虫模块介绍--Beautifulsoup的主要内容,如果未能解决你的问题,请参考以下文章