堆排序
Posted dhcao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了堆排序相关的知识,希望对你有一定的参考价值。
一、定义
1.1 堆
? 此处的堆,指数据结构中的堆。而不是内存中的那种内存堆,内存堆是基于数据结构的一种实现。堆的数据结构是一棵完全二叉树,它有如下特点:(具体参考下文链接)
- 堆是一棵完全二叉树
- 它总是最小值在根节点(或最大值在根节点)
- 它上一层比下一层小(大)
- 必定有快速删除根节点,并返回根节点元素的方法
- 在删除根节点(最小元或者最大元)之后,自动调节使之依然保持堆结构。
- 插入节点依然保持堆结构
? 综上,堆结构的基本操作是插入和删除根节点,在操作过程中还会保持堆结构不会被破坏。所以我们可以用堆排序,我们可以通过删除根节点得到最小值,再删除根节点,得到第二小值,如此类推,只要一直取根节点,就能得到从小到大的序列。
1.2 堆排序
? 对一个含有N个元素的数组a,我们利用堆排序的做法:
- 首先建立一个二叉堆(最小元在根节点)。根据二叉堆的特性,此过程运行时间(O(N))。
- 然后执行(N)次删除最小元(deleteMin)操作,按照顺序,最小的元素先离开堆。
- 将这些元素记录到第二个数组中,得到一个排序之后的数组(可避免使用第二个数组)。
- 再将这些数组拷贝回来,得到(N)个元素的排序。
? 图解:
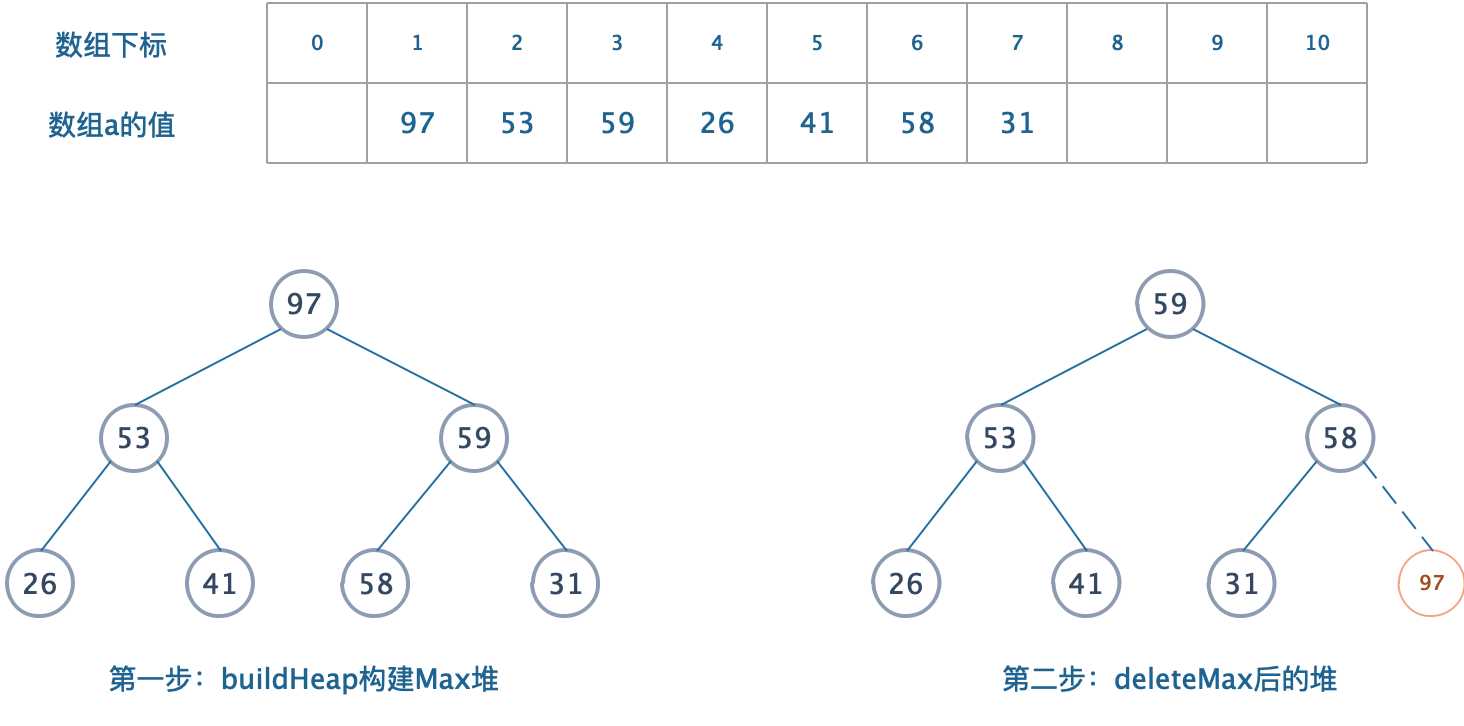
图解描述
? 我们对数组a进行堆排序,采用根节点存放最大值(最大最小都一样)并且避免使用第二个数组。
- 构建一个Max堆,最大值在根节点,父节点必定比子节点大。
- deleteMax,堆缩小1。
- 将刚刚删除的元素放在空出来的位置。
- 依次类推,我们借助二叉堆一个重要的特性:删除时,总是空出最后一个元素。这是为了保持它是一个完全二叉树。
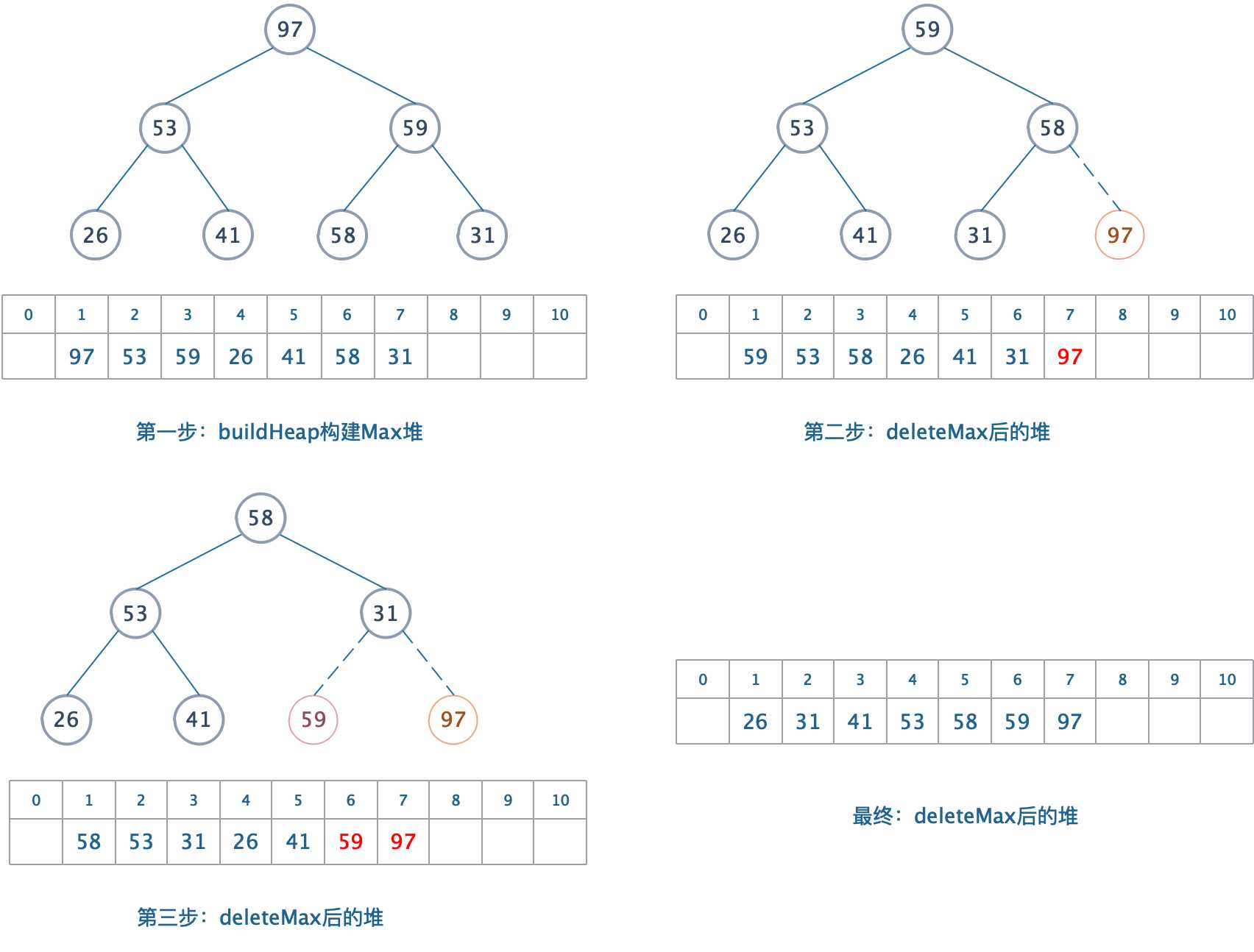
以上做法,我们避免使用第二个数组,而是直接在第一个数组中构建一个堆。然后将堆排序!
二、算法分析
? 堆排序耗费的时间可以分为2个部分。第一阶段构建堆,第二阶段是循环删除根元素(deleteMax)。
? 第一阶段:从堆的性质我们可以知道,构建N个元素的堆,需要2N次比较。(这是因为堆的性质是父节点大于子节点,所以要选出父节点,需要根左右子节点相互比较)
? 第二阶段:循环deleteMax。第(i)次deleteMax最多用到(2lfloor logi floor)次比较,这个时间来自于堆的deleteMax时间分析,删除最大值之后,我们需要重新构建堆,那么就需要最后一个位置放入根节点所在的空穴(根节点作为最大值已经被删除,只剩下空穴一个)中,然后采用下沉的方式,将它放到合适的位置,重新构建堆只需要满足父节点大于子节点,所以下沉过程只需要根左子节点和右子节点比较,而二叉树的高是(logN)。
? 所以总时间是:
[
第二阶段+第一阶段时间 2(sum_{i=1}^{N}logi )+2N=2(log1+log2+···+logN)+2N=2(log(1*2*3*···*N))+2N=2(logN!)+2N=2(log(sqrt{2pi N}frac{N^N}{e^N})+2N=2(frac{1}{2}log(2pi)+frac{1}{2}logN + NlogN -Nloge)+2N =O(2NlogN-O(N))
]
关于堆的构建和删除可以参照:https://www.cnblogs.com/dhcao/p/10591282.html
?
? 堆排序的时间是:(O(2NlogN-O(N)))
三、代码地址
https://github.com/dhcao/dataStructuresAndAlgorithm/blob/master/src/chapterSeven/HeasportEx.java
以上是关于堆排序的主要内容,如果未能解决你的问题,请参考以下文章