英文单词拼写纠错
Posted baobaotql
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了英文单词拼写纠错相关的知识,希望对你有一定的参考价值。
在知乎上看到了一个问题“有哪些你喜欢的逻辑清晰,书写优雅的源代码呢?”
有人po出了大神Peter Norvig的‘Spelling Corrector’(拼写检查器)
by http://norvig.com/spell-correct.html
文章大意:2007年的一个星期,两位朋友(迪恩和比尔)独立告诉我,他们对谷歌的拼写纠正感到惊讶。输入类似spelling的搜索,Google会立即显示结果: 拼写。我认为Dean和Bill是高度成熟的工程师和数学家,他们对这个过程的运作方式有很好的直觉。但他们没有,并且想到它,为什么他们应该知道迄今为止他们的专长?
我认为他们和其他人可以从解释中受益。工业强度法术纠正器的全部细节非常复杂。但我认为,在横贯大陆的飞机旅行过程中,我可以编写和解释一个玩具拼写校正器,在大约半页代码中以每秒至少10个字的处理速度达到80%或90%的准确度。
源代码如下:
1 import re 2 from collections import Counter 3 4 #==== 训练一个带有概率的词库 ==== 5 def words(text): 6 return re.findall(r‘w+‘, text.lower()) 7 8 WORDS = Counter(words(open(‘d:\\big.txt‘).read())) 9 10 def P(word, N=sum(WORDS.values())): 11 "Probability of `word`." 12 return WORDS[word] / N 13 14 #==== 给定单词A,枚举所有可能正确的拼写 ==== 15 def edits1(word): 16 "All edits that are one edit away from `word`." 17 letters = ‘abcdefghijklmnopqrstuvwxyz‘ 18 splits = [(word[:i], word[i:]) for i in range(len(word) + 1)] 19 deletes = [L + R[1:] for L, R in splits if R] 20 transposes = [L + R[1] + R[0] + R[2:] for L, R in splits if len(R)>1] 21 replaces = [L + c + R[1:] for L, R in splits if R for c in letters] 22 inserts = [L + c + R for L, R in splits for c in letters] 23 return set(deletes + transposes + replaces + inserts) 24 25 def edits2(word): 26 "All edits that are two edits away from `word`." 27 return (e2 for e1 in edits1(word) for e2 in edits1(e1)) 28 #==== 返回候选词 ==== 29 def candidates(word): 30 "Generate possible spelling corrections for word." 31 return (known([word]) or known(edits1(word)) or known(edits2(word)) or [word]) 32 33 def known(words): 34 "The subset of `words` that appear in the dictionary of WORDS." 35 return set(w for w in words if w in WORDS) 36 37 #==== 输出概率最大的纠正词 ==== 38 def correction(word): 39 "Most probable spelling correction for word." 40 return max(candidates(word), key=P)
其实自己没有其他博主的讲解是真的看不懂,甚至单词还有自己google翻译......我真是tcl......
一些概率知识
拼写检查器的目的是找到最近似错误输入“w”的正确拼写,但是对于一个错误拼写,其正确的候选者有很多(例如:“lates”应该被纠正为“late”呢,还是“lattes”呢?)。因此我们可以采取概率的思路,在错误拼写w出现的条件下,选择所有可能的备选纠正单词c中概率最大的。

由贝叶斯公式可得:
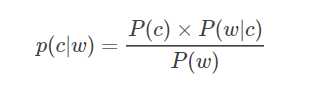
由于P(w)P(w) 对于每个待选择的c都是一样大小的,因此我们就忽略这个因素,最终公式变形为:
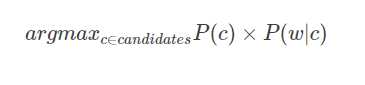
- 这个公式中由四个主要的部分:
- 选择机构:argmax
我们选择备选单词中概率最高的单词作为输出。 - 备选模型:c∈candidatesc∈candidates
这一部分告诉我们考虑哪些单词作为备选。 - 语言模型:P(c)
单词c出现在语料库中的概率。例如,在一个英文语料库中,有7%的单词是“the”,那么P(the)=0.07P(the)=0.07 - 错误模型: P(w|c)
当用户想输入C时,错输入成w的概率。例如,P(teh|the)P(teh|the)应该远大于P(theeexyz|the)P(theeexyz|the)。
我们用条件概率 P(w|c)P(w|c) 和先验概率P(c)P(c) 这两个便于考虑和学习的因素替代了后延概率P(c|w)P(c|w) ,这样问题更容易分析和解决。
python具体实现过程
1、选择机构 :由python的max函数实现
2、备选模型 :通过一些简单的操作(edits),生成一个set作为备选单词库。如:删除一个字母(deletions),交换两个字母的位置(transposes),把一个字母替换成另一个字母(replacement),增加一个字母(insertion)。通过这几个常见的拼写错误,可以扩展出一系列的备选单词,形成一个set。
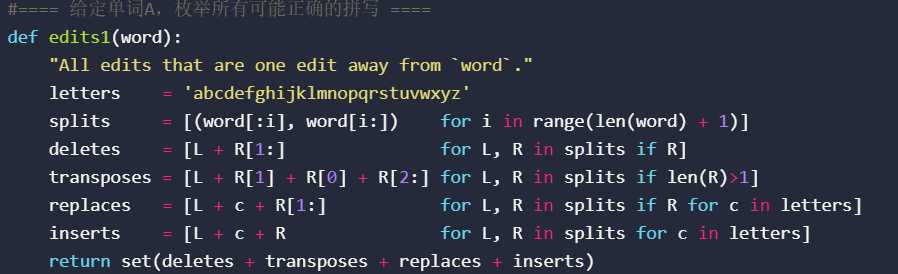
这是一个很大的set,因为对于一个长度为n的单词,会生成n个deletions,n-1个transpositions,26n个replacements,16(n+1)个insertions,总共是(54n+25)个可能性。例如:
>>> len(edits1(‘somthing‘)) 442
然而我们可以定义一个识别这些生成的备选单词正确性的模块,只匹配词典中存在的词。这个set将会变得很小,因为随机生成单词中,许多都是非法拼写的,并非真正存在。
def known(words): return set(w for w in words if w in WORDS) >>> known(edits1(‘somthing‘)) {‘something‘, ‘soothing‘}
同样,我们考虑经过两步骤的简单操作(edits)后得到的纠错备选模型(例如,写错了两个字母,写掉了两个字母),经过两次简单操作的组和将会生成更多的备选单词,但是也仅有很少一部分是正确拼写的单词,例如:
def edits2(word): return (e2 for e1 in edits1(word) for e2 in edits1(e1)) >>> len(set(edits2(‘something‘)) 90902 >>> known(edits2(‘something‘)) {‘seething‘, ‘smoothing‘, ‘something‘, ‘soothing‘} >>> known(edits2(‘somthing‘)) {‘loathing‘, ‘nothing‘, ‘scathing‘, ‘seething‘, ‘smoothing‘, ‘something‘, ‘soothing‘, ‘sorting‘}
经过edits2(w)处理的单词,与原始单词w的edit distance(不知道怎么翻译,翻译为编辑距离?) 为2。
3、语言模型
我们通过统计在语料库中某个词(word)出现的频率来衡量一个词的先验概率P(word)P,这里我们使用一个语料库big.txt来构建我们的语言模型。这个语料库含有100万个单词,里面包含一本书和一些常见词汇的列表。定义函数 word 来把语料文本打碎成一个一个单词的形式,然后构建一个计数器counter,统计每个词的出现频率,概率P代表了每个词出现的概率:
def words(text): return re.findall(r‘w+‘, text.lower()) WORDS = Counter(words(open(‘big.txt‘).read())) def P(word, N=sum(WORDS.values())): return WORDS[word] / N
通过一些简单的NLP操作,我们可以看到这里有32192个单词,所有单词一共出现了1115504次,’the’是出现概率最大的,一共出现了79808次:
>>> len(WORDS) 32192 >>> sum(WORDS.values()) 1115504 >>> WORDS.most_common(10) [(‘the‘, 79808), (‘of‘, 40024), (‘and‘, 38311), (‘to‘, 28765), (‘in‘, 22020), (‘a‘, 21124), (‘that‘, 12512), (‘he‘, 12401), (‘was‘, 11410), (‘it‘, 10681), (‘his‘, 10034), (‘is‘, 9773), (‘with‘, 9739), (‘as‘, 8064), (‘i‘, 7679), (‘had‘, 7383), (‘for‘, 6938), (‘at‘, 6789), (‘by‘, 6735), (‘on‘, 6639)] >>> max(WORDS, key=P) ‘the‘ >>> P(‘the‘) 0.07154434228832886 >>> P(‘outrivaled‘) 8.9645577245801e-07 >>> P(‘unmentioned‘) 0.0
定义出一个函数candidates(),根据优先级产生一个非空的候选单词序列:
- 优先级排序如下
- 1、原始单词
- 2、与原始单词的edit distance为1的单词(即经过一次编辑产生的那些拼写)
3、与原始单词的edit distance为2的单词(即经过两次编辑产生的那些拼写)
4、原始单词,即使那些单词是词典中没有的。
因此我们把条件概率模块替换成了这样一种优先级的排序。或许这其中还有很多不完善的地方,如根据什么别的语料库统计到,人们写单词写错的时候是写掉一个字母比多加一个字母常见,交换两个字母比写错一个字母常见等这些规则是我们在没学习也没数据的时候未知的,也是你在定义自己的拼写纠错器时,可以自己考虑的内容。因为我们现在只是一个玩具代码,所以我们采取了这样一个简单的优先级排序模式来替代这个重要的部分。
def correction(word): return max(candidates(word), key=P) def candidates(word): return known([word]) or known(edits1(word)) or known(edits2(word)) or [word]
模型评价
作者用一个牛津大学的数据集测评了自己的玩具代码,当你完善了自己的纠错模型之后,或许你也可以通过这个方式来测试一下你模型的准确率。测试的代码如下:
def unit_tests(): assert correction(‘speling‘) == ‘spelling‘ # insert assert correction(‘korrectud‘) == ‘corrected‘ # replace 2 assert correction(‘bycycle‘) == ‘bicycle‘ # replace assert correction(‘inconvient‘) == ‘inconvenient‘ # insert 2 assert correction(‘arrainged‘) == ‘arranged‘ # delete assert correction(‘peotry‘) ==‘poetry‘ # transpose assert correction(‘peotryy‘) ==‘poetry‘ # transpose + delete assert correction(‘word‘) == ‘word‘ # known assert correction(‘quintessential‘) == ‘quintessential‘ # unknown assert words(‘This is a TEST.‘) == [‘this‘, ‘is‘, ‘a‘, ‘test‘] assert Counter(words(‘This is a test. 123; A TEST this is.‘)) == ( Counter({‘123‘: 1, ‘a‘: 2, ‘is‘: 2, ‘test‘: 2, ‘this‘: 2})) assert len(WORDS) == 32192 assert sum(WORDS.values()) == 1115504 assert WORDS.most_common(10) == [ (‘the‘, 79808), (‘of‘, 40024), (‘and‘, 38311), (‘to‘, 28765), (‘in‘, 22020), (‘a‘, 21124), (‘that‘, 12512), (‘he‘, 12401), (‘was‘, 11410), (‘it‘, 10681)] assert WORDS[‘the‘] == 79808 assert P(‘quintessential‘) == 0 assert 0.07 < P(‘the‘) < 0.08 return ‘unit_tests pass‘ def spelltest(tests, verbose=False): "Run correction(wrong) on all (right, wrong) pairs; report results." import time start = time.clock() good, unknown = 0, 0 n = len(tests) for right, wrong in tests: w = correction(wrong) good += (w == right) if w != right: unknown += (right not in WORDS) if verbose: print(‘correction({}) => {} ({}); expected {} ({})‘ .format(wrong, w, WORDS[w], right, WORDS[right])) dt = time.clock() - start print(‘{:.0%} of {} correct ({:.0%} unknown) at {:.0f} words per second ‘ .format(good / n, n, unknown / n, n / dt)) def Testset(lines): "Parse ‘right: wrong1 wrong2‘ lines into [(‘right‘, ‘wrong1‘), (‘right‘, ‘wrong2‘)] pairs." return [(right, wrong) for (right, wrongs) in (line.split(‘:‘) for line in lines) for wrong in wrongs.split()] print(unit_tests()) spelltest(Testset(open(‘spell-testset1.txt‘))) # Development set spelltest(Testset(open(‘spell-testset2.txt‘))) # Final test set
下载地址: spell-testset1 http://norvig.com/spell-testset1.txt
spell-testset2.txt http://norvig.com/spell-testset1.txt
unit_tests pass 75% of 270 correct at 41 words per second 68% of 400 correct at 35 words per second None
前人栽树,后人乘凉。感谢前人的经验分享与讲解,让后辈们受益颇多,也特此感谢博主irfan_lcmll的分享https://blog.csdn.net/qq_27879381/article/details/63351483
另附自动纠错github其他开源代码https://github.com/phatpiglet/autocorrect
以上是关于英文单词拼写纠错的主要内容,如果未能解决你的问题,请参考以下文章