TensorFlow 神经网络教程
Posted t198520
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TensorFlow 神经网络教程相关的知识,希望对你有一定的参考价值。
TensorFlow 是一个用于机器学习应用程序的开源库。它是谷歌大脑的第二代系统,在取代了近源的 DistBelief 之后,被谷歌用于研究和生产应用。TensorFlow 提供了很多种语言接口,包括 Python、C++、Go、Java 和 C 等等。考虑到普遍性和易学性,本文将采用 Python 版本,并且会简单介绍下 TensorFlow 的安装和它的一些低阶 API,以及从头开始构建基于真实数据集的前馈神经网络。
在更为复杂的应用场景下,神经网络的训练时长往往是一种特别需要克服的因素。由于神经网络以及其他机器学习算法主要在处理矩阵乘法,因此在 GPU 上运行要比在 CPU 上快得多(当然有个别情况除外)。
TensorFlow 支持 CPU 和 GPU,Google 甚至还研究出了 TensorFlow 专用的云计算硬件,叫做 Tensor Processing Unit(TPU),可在训练中达到更好的性能。
安装
虽然 TPU 仅在云中可用,但 TensorFlow 在本地计算机上的安装可以安装 CPU 版或者 GPU 版的。要安装GPU 版本,你的电脑必须有 NVIDIA 显卡,并且还要满足。
基本上,安装至少有5种不同的选项,使用:virtualenv,pip,Docker,Anaconda,以及从源代码安装。
最常见和最简单的安装方式是通过 virtualenv 和 pip,因此它们将在本文中进行解释。
如果你已经使用了 Python 一段时间,你可能知道 pip 。以下是如何在 Ubuntu 上安装:
# Install pip sudo apt-get install python-pip python-dev # Python 2.7 sudo apt-get install python3-pip python3-dev # Python 3.x
在 Ubuntu 和 Mac OSX(不支持 GPU) 机器上安装 TensorFlow:
# CPU support pip install tensorflow # Python 2.7 pip3 install tensorflow # Python 3.x # GPU support pip install tensorflow-gpu # Python 2.7 pip3 install tensorflow-gpu # Python 3.x
上述命令也适用于 Windows 系统,但仅适用于 Python 3.5.x 和 3.6.x 版本。
在单独的环境中安装 TensorFlow 可以通过 virtualenv 或 conda(Anaconda的一部分)来完成。同样的代码一样可以安装,不过使用前需要创建和激活虚拟环境:
virtualenv --system-site-packages ~/tensorflow
source ~/tensorflow/bin/activate
这可以很好地把虚拟环境与系统上全局安装的软件包分离开来。
核心API组件
TensorFlow 提供了高阶 API 和低阶 API。最低级别的一级称为 Core,它与基本组件一起使用:Tensors、Graphs 和 Sessions。
更高级别的API,例如 tf.estimator,用于简化工作流程和自动化,包括数据集管理、学习、评估等过程。无论如何,了解库的核心功能才能更好地利用 TensorFlow 这个利器。
Core API 的重点是构建一个计算图,其中包含一系列排列在节点图中的操作。每个节点可以具有多个张量(基本数据结构)作为输入并对它们执行操作以计算输出,该输出随后可以表示对多层网络中的其他节点的输入。这种类型的架构适用于机器学习应用,比如神经网络。
张量
张量是 TensorFlow 中的基本数据结构,它以任意数量的维度存储数据,类似于 NumPy 中的多维数组。张量有三种基本类型:常量,变量和占位符。
- 常量是不可变类型的张量。它们可以被视为没有输入的节点,输出它们在内部存储的单个值。
- 变量是可变类型的
tensors,其值可以在图形运行期间改变。在ML应用中,变量通常存储需要优化的参数(例如,神经网络中节点之间的权重)。在通过显式调用特殊操作运行图形之前,需要初始化变量。 - 占位符是存储来自外部源的数据的张量。它们代表了一个“承诺”,即在运行图形时将提供一个值。在机器学习应用程序中,占位符通常用于向学习模型输入数据。
以下几行给出了三种张量类型的示例:
import tensorflow as tf tf.reset_default_graph() # Define a placeholder a = tf.placeholder("float", name=‘pholdA‘) print("a:", a) # Define a variable b = tf.Variable(2.0, name=‘varB‘) print("b:", b) # Define a constant c = tf.constant([1., 2., 3., 4.], name=‘consC‘) print("c:", c)
a: Tensor("pholdA:0", dtype=float32) b: <tf.Variable ‘varB:0‘ shape=() dtype=float32_ref> c: Tensor("consC:0", shape=(4,), dtype=float32)
请注意,此时张量不包含值,并且只有在会话中运行图形时,它们的值才可用。
图
此时,图仅保存未连接的树张量。让我们在我们的张量上运行一些操作:
d = a * b + c d <tf.Tensor ‘add:0‘ shape=<unknown> dtype=float32>
结果输出又是一个名为 add 的张量,我们的模型现在如下图所示。你可以使用 TensorFlow 的内置功能TensorBoard 来探索图和其他参数。
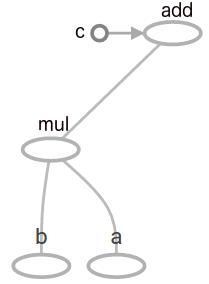
图1:包含乘法和加法的 TensorFlow 图。
另一个用于探索图的有用工具如下,它可以打印出其中的所有操作。
# call the default graph graph = tf.get_default_graph() # print operations in the graph for op in graph.get_operations(): print(op.name) pholdA varB/initial_value varB varB/Assign varB/read consC mul add
会话
最后,我们的图应该在会话中运行。要注意的是,变量是预先初始化的,而占位符通过feed_dict属性接收具体值。
# Initialize variables init = tf.global_variables_initializer() # Run a session and calculate d sess = tf.Session() sess.run(init) print(sess.run(d, feed_dict={a: [[0.5], [2], [3]]})) sess.close() [[ 2. 3. 4. 5.] [ 5. 6. 7. 8.] [ 7. 8. 9. 10.]]
以上示例是学习模型的简化。无论哪种方式,它都展示了如何将基本tf组件组合在一个图中并在会话中运行。此外,它还说明了操作是如何在不同形状的张量上运行的。
下面我们将使用 Core API 构建一个神经网络,用于在真实数据上进行机器学习。
神经网络模型
我们来使用 TensorFlow 的核心组件从头开始构建前馈神经网络。
鸢尾花数据集
鸢尾花数据集 由150个植物实例组成,每个植物都有4个维度(用做输入特征)及其类型(需要预测的输出值)。这些植物可能属于三种类型中的一种( setosa,virginica 和 versicolor )。让我们首先从TensorFlow 的网站下载数据 - 它分为训练和测试子集,每个子??集分别包含 120 和 30 个实例。
# Import the needed libraries import numpy as np import pandas as pd import tensorflow as tf import urllib.request as request import matplotlib.pyplot as plt
# Download dataset IRIS_TRAIN_URL = "http://download.tensorflow.org/data/iris_training.csv" IRIS_TEST_URL = "http://download.tensorflow.org/data/iris_test.csv" names = [‘sepal-length‘, ‘sepal-width‘, ‘petal-length‘, ‘petal-width‘, ‘species‘] train = pd.read_csv(IRIS_TRAIN_URL, names=names, skiprows=1) test = pd.read_csv(IRIS_TEST_URL, names=names, skiprows=1) # Train and test input data Xtrain = train.drop("species", axis=1) Xtest = test.drop("species", axis=1) # Encode target values into binary (‘one-hot‘ style) representation ytrain = pd.get_dummies(train.species) ytest = pd.get_dummies(test.species)
模型和学习
神经网络的输入和输出层的形状将对应于数据的形状,即输入层将包含表示四个输入特征的四个神经元,而由于要给这三个物种编码,输出层将包含三个神经元。例如,‘setosa‘ 物种可以用向量 [1,0,0] 编码,‘virginica‘ 用 [0,1,0] 等编码。
我们为隐藏层中的神经元数量选择三个值:5、10 和 20,因此网络大小为(4-5-3),(4-10-3)和(4-20-3)。这意味着我们的第一个网络将拥有 4 个输入神经元,5 个“隐藏”神经元和 3 个输出神经元。
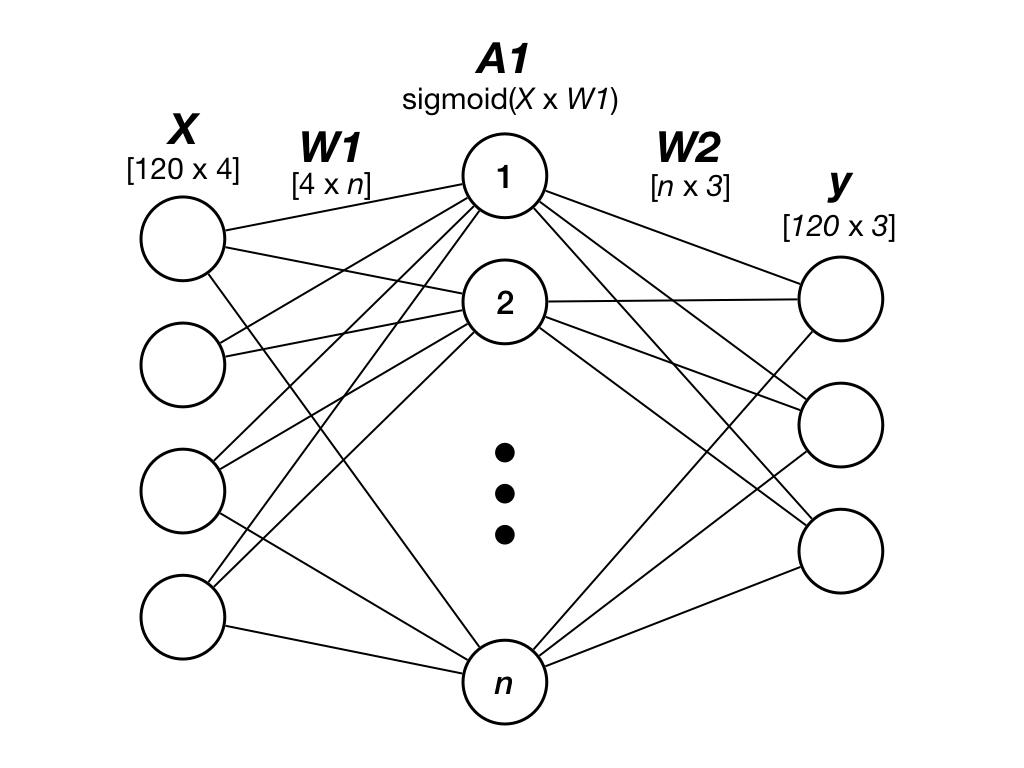
图 2:三层前馈神经网络。
下面的代码定义了一个函数,我们在其中创建模型,定义需要最小化的损失函数,并运行2000次迭代的会话以学习最佳权重W_1和W_2。如上文所述,输入和输出矩阵被馈送到 tf.placeholder 张量,权重表示为变量,因为它们的值在每次迭代中都会发生变化。损失函数定义为我们的预测 y_est 与实际物种类型 y 之间的均方误差,使用的激活函数是 sigmoid。 create_train_model 函数返回学习的权重并打印出损失函数的最终值。
# Create and train a tensorflow model of a neural network def create_train_model(hidden_nodes, num_iters): # Reset the graphtf.reset_default_graph() # Placeholders for input and output dataX = tf.placeholder(shape=(120, 4), dtype=tf.float64, name=‘X‘)y = tf.placeholder(shape=(120, 3), dtype=tf.float64, name=‘y‘) # Variables for two group of weights between the three layers of the networkW1 = tf.Variable(np.random.rand(4, hidden_nodes), dtype=tf.float64)W2 = tf.Variable(np.random.rand(hidden_nodes, 3), dtype=tf.float64) # Create the neural net graphA1 = tf.sigmoid(tf.matmul(X, W1))y_est = tf.sigmoid(tf.matmul(A1, W2)) # Define a loss functiondeltas = tf.square(y_est - y)loss = tf.reduce_sum(deltas) # Define a train operation to minimize the lossoptimizer = tf.train.GradientDescentOptimizer(0.005)train = optimizer.minimize(loss) # Initialize variables and run sessioninit = tf.global_variables_initializer()sess = tf.Session()sess.run(init) # Go through num_iters iterationsfor i in range(num_iters):sess.run(train, feed_dict={X: Xtrain, y: ytrain})loss_plot[hidden_nodes].append(sess.run(loss, feed_dict={X: Xtrain.as_matrix(), y: ytrain.as_matrix()}))weights1 = sess.run(W1)weights2 = sess.run(W2) print("loss (hidden nodes: %d, iterations: %d): %.2f" % (hidden_nodes, num_iters, loss_plot[hidden_nodes][-1]))sess.close()return weights1, weights2
创建三个网络架构,并在迭代上绘制损失函数。
# Run the training for 3 different network architectures: (4-5-3) (4-10-3) (4-20-3) # Plot the loss function over iterations num_hidden_nodes = [5, 10, 20] loss_plot = {5: [], 10: [], 20: []} weights1 = {5: None, 10: None, 20: None} weights2 = {5: None, 10: None, 20: None} num_iters = 2000 plt.figure(figsize=(12,8)) for hidden_nodes in num_hidden_nodes: weights1[hidden_nodes], weights2[hidden_nodes] = create_train_model(hidden_nodes, num_iters) plt.plot(range(num_iters), loss_plot[hidden_nodes], label="nn: 4-%d-3" % hidden_nodes) plt.xlabel(‘Iteration‘, fontsize=12) plt.ylabel(‘Loss‘, fontsize=12) plt.legend(fontsize=12) loss (hidden nodes: 5, iterations: 2000): 31.82 loss (hidden nodes: 10, iterations: 2000): 5.90 loss (hidden nodes: 20, iterations: 2000): 5.61 <matplotlib.legend.Legend at 0x123b157f0>
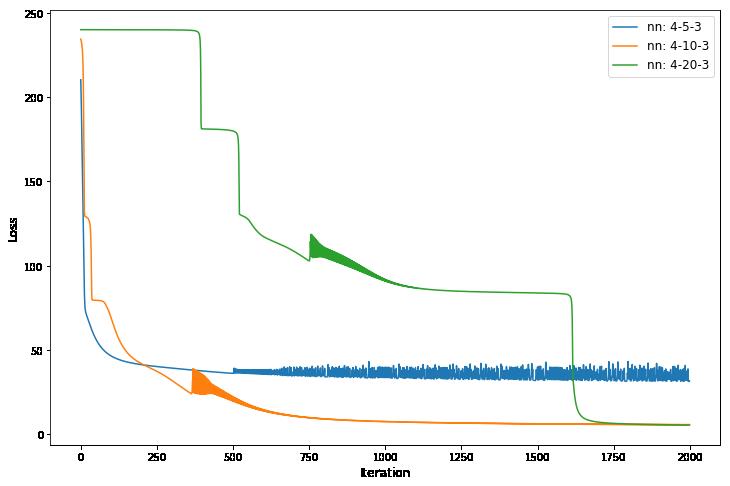
图 3:不同结构的神经网络 2000 次迭代损失函数对比。
我们可以看到,具有 20 个隐藏神经元的网络需要更多时间才能达到最小值,这是由于其更高的复杂性。具有 5 个隐藏神经元的网络陷入局部最小值,并且不会产生满意的结果。
无论如何,对于像 Iris 这样简单的数据集,即使是具有5个隐藏神经元的小型网络也应该能够学习一个好的模型。在我们的例子中,只是一个随机事件,模型陷入局部最小值,如果我们一次又一次地运行代码,它就不会经常发生。
模型评估
最后,评估模型。我们使用学习的权重W_1,W_2并向前传播测试集的示例。精度度量被定义为正确预测的示例的百分比。
# Evaluate models on the test set X = tf.placeholder(shape=(30, 4), dtype=tf.float64, name=‘X‘) y = tf.placeholder(shape=(30, 3), dtype=tf.float64, name=‘y‘) for hidden_nodes in num_hidden_nodes: # Forward propagationW1 = tf.Variable(weights1[hidden_nodes])W2 = tf.Variable(weights2[hidden_nodes])A1 = tf.sigmoid(tf.matmul(X, W1))y_est = tf.sigmoid(tf.matmul(A1, W2)) # Calculate the predicted outputsinit = tf.global_variables_initializer()with tf.Session() as sess:sess.run(init)y_est_np = sess.run(y_est, feed_dict={X: Xtest, y: ytest}) # Calculate the prediction accuracycorrect = [estimate.argmax(axis=0) == target.argmax(axis=0) for estimate, target in zip(y_est_np, ytest.as_matrix())]accuracy = 100 * sum(correct) / len(correct)print(‘Network architecture 4-%d-3, accuracy: %.2f%%‘ % (hidden_nodes, accuracy)) Network architecture 4-5-3, accuracy: 90.00% Network architecture 4-10-3, accuracy: 96.67% Network architecture 4-20-3, accuracy: 96.67%
总的来说,我们通过简单的前馈神经网络实现了相当高的精度,使用非常小的数据集尤其令人惊讶。
结语:
另外我们还准备了吴恩达的机器学习免费路线,还会带你们一起实践人工智能项目,《图像风格迁移》《人脸识别》《图像追踪》《聊天机器人》等等项目都会手把手教。有兴趣的老铁可以加我微信!!!

以上是关于TensorFlow 神经网络教程的主要内容,如果未能解决你的问题,请参考以下文章