前端反爬虫策略--font-face 猫眼数据爬取
Posted wrnmb
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了前端反爬虫策略--font-face 猫眼数据爬取相关的知识,希望对你有一定的参考价值。
2 .font-face加载网络字体,我么可以自己创建一套字体,然后自定义一套字符映射关系表例如设置0xefab是映射字符1,0xeba2是映射字符2,以此类推。当需要显示字符1时,网页的源码只会是0xefab,被采集的也只会是 0xefab,并不是1 3 .但是对于正常的用户来说则没有影响,因为浏览器会加载css的font字体为我们渲染好,实时显示在网页中。 4 .所以我们需要做的是,如何在判断请求web字体的是机器人或者是真人,也就是说,拦截被收敛到了这一个地方
5 .定期更新一批字体文件和映射表来加大难度
6 .他这个破解也很简单,需要一下人工,读出那个请求html文件对应数字的unicode,自己把那个表更新一下,转换那个部分可以做成自动的,还是可以用的。自己手动看一下1-9对应的unicode
实战:猫眼
猫眼电影
首先来看一个页面
https://maoyan.com/films/1212492

来分析一下页面,先来网页源代码看看

可以找的到数据 但是数据是原始编码。
这时候可能想那是不是 对应的就是9,而对应的就是3呢?
好我们来刷新验证一下
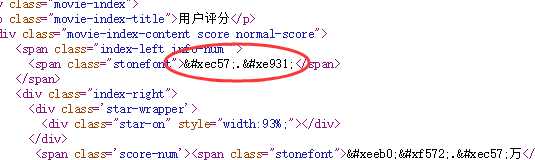
有不一样了这是怎么回事呢,我们来看
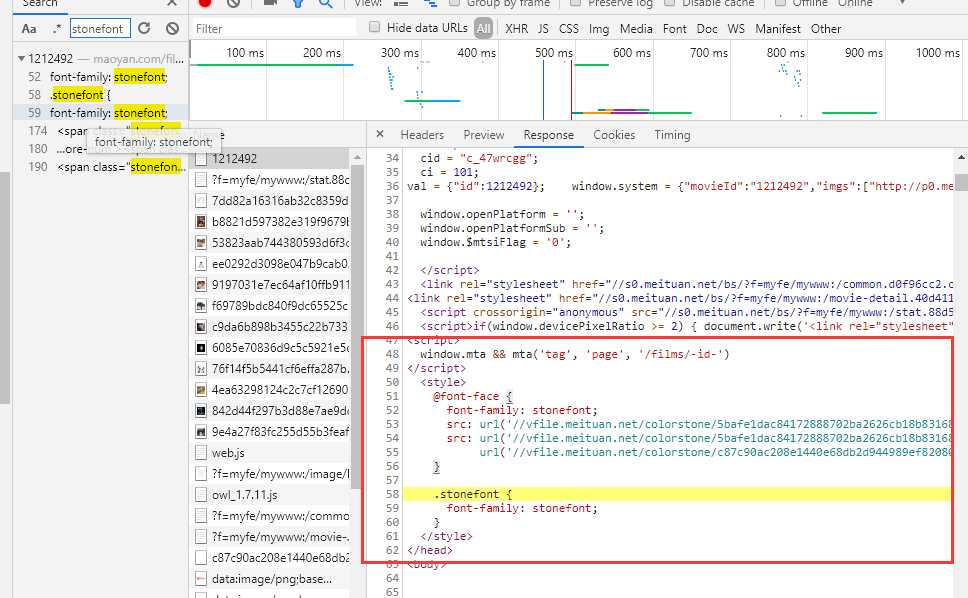
发现这个url是随机的,每次访问的值都不一样。
emm那如果我们想要拿所有的数据就不适合把编码写死了,我们把字体文件下载下来看看里面究竟是怎么回事。它是一个woff的字体文件,我们可以使用python的一个第三方库fonttools来帮助我们查看字体的信息。
fontTools
安装很简单,我的python版本是python3。
pip3 install fonttools
使用起来也很简单,有一些以前的技术博客写的这里的fonttools解析下来的结果是有序的,可能是猫眼升级了反爬措施,但是我解析下来的编码是乱序的,所以只能自己去分析woff文件。
ttf = TTFont(‘./fonts/‘ + link)
self.font.saveXML(‘trans.xml‘) # 将woff文件的信息储存为xml格式, 我们可以在xml里查看一些相关内容
trans.xml的输出信息太长了这里就贴一部分
<TTGlyph name="uniE89E" xMin="0" yMin="-12" xMax="516" yMax="706"> <contour> <pt x="134" y="195" on="1"/> <pt x="144" y="126" on="0"/> <pt x="217" y="60" on="0"/> <pt x="271" y="60" on="1"/> <pt x="335" y="60" on="0"/> <pt x="423" y="158" on="0"/> <pt x="423" y="311" on="0"/> <pt x="337" y="397" on="0"/> <pt x="270" y="397" on="1"/> <pt x="227" y="397" on="0"/> <pt x="160" y="359" on="0"/> <pt x="140" y="328" on="1"/> <pt x="57" y="338" on="1"/> <pt x="126" y="706" on="1"/> <pt x="482" y="706" on="1"/> <pt x="482" y="622" on="1"/> <pt x="197" y="622" on="1"/> <pt x="158" y="430" on="1"/> <pt x="190" y="452" on="0"/> <pt x="258" y="475" on="0"/> <pt x="293" y="475" on="1"/> <pt x="387" y="475" on="0"/> <pt x="516" y="346" on="0"/> <pt x="516" y="243" on="1"/> <pt x="516" y="147" on="0"/> <pt x="459" y="75" on="1"/> <pt x="390" y="-12" on="0"/> <pt x="271" y="-12" on="1"/> <pt x="173" y="-12" on="0"/> <pt x="112" y="42" on="1"/> <pt x="50" y="98" on="0"/> <pt x="42" y="188" on="1"/> </contour> <instructions/> </TTGlyph>
然后我们发现每一个数字编码都对应一个这样的信息,每个信息的内容都不相同。经过细心的比对各个woff文件我们发现不同文件之间相同的数字对应的第一行<pt>内容是相同的,所以只要通过解析出一个woff里编码的数字内容,其他woff的就都可以解析。为此我做了一个解析表
NUM_ATTR = { ‘8‘: {‘x‘: ‘177‘, ‘y‘: ‘388‘, ‘on‘: ‘1‘}, ‘7‘: {‘x‘: ‘47‘, ‘y‘: ‘622‘, ‘on‘: ‘1‘}, ‘6‘: {‘x‘: ‘410‘, ‘y‘: ‘534‘, ‘on‘: ‘1‘}, ‘5‘: {‘x‘: ‘134‘, ‘y‘: ‘195‘, ‘on‘: ‘1‘}, ‘1‘: {‘x‘: ‘373‘, ‘y‘: ‘0‘, ‘on‘: ‘1‘}, ‘3‘: {‘x‘: ‘130‘, ‘y‘: ‘201‘, ‘on‘: ‘1‘}, ‘4‘: {‘x‘: ‘323‘, ‘y‘: ‘0‘, ‘on‘: ‘1‘}, ‘9‘: {‘x‘: ‘139‘, ‘y‘: ‘173‘, ‘on‘: ‘1‘}, ‘2‘: {‘x‘: ‘503‘, ‘y‘: ‘84‘, ‘on‘: ‘1‘}, ‘0‘: {‘x‘: ‘42‘, ‘y‘: ‘353‘, ‘on‘: ‘1‘}, ‘.‘: {‘x‘: ‘20‘, ‘y‘: ‘20‘, ‘on‘: ‘1‘}, }
然后可以根据这个表的内容来解析每一次爬下来的woff文件内容,搞成一个转换表。
def parse_transform(self):
self.font.saveXML(‘trans.xml‘)
tree = etree.parse("trans.xml")
TTGlyph = tree.xpath(".//TTGlyph")
translate_form = {}
for ttg in TTGlyph[1:]:
ttg_dic = dict(ttg.attrib)
attr_dic = dict(ttg.xpath(‘./contour/pt‘)[0].attrib)
name = ttg_dic[‘name‘].replace(‘uni‘, ‘&#x‘).lower() + ‘;‘
ttg_dic.pop(‘name‘)
for num, dic in NUM_ATTR.items():
if dic == attr_dic:
translate_form[name] = num
return translate_form
最好把这表保存一下,这样以后遇到重复的字体就不用重复解析了。
贴一下完整代码,使用的是scrapy框架,没有用其他组件,而且只爬了一个页面,所以只贴爬虫的内容了
# -*- coding: utf-8 -*- import re import os import json import scrapy import requests from fontTools.ttLib import TTFont from lxml import etree NUM_ATTR = { ‘8‘: {‘x‘: ‘177‘, ‘y‘: ‘388‘, ‘on‘: ‘1‘}, ‘7‘: {‘x‘: ‘47‘, ‘y‘: ‘622‘, ‘on‘: ‘1‘}, ‘6‘: {‘x‘: ‘410‘, ‘y‘: ‘534‘, ‘on‘: ‘1‘}, ‘5‘: {‘x‘: ‘134‘, ‘y‘: ‘195‘, ‘on‘: ‘1‘}, ‘1‘: {‘x‘: ‘373‘, ‘y‘: ‘0‘, ‘on‘: ‘1‘}, ‘3‘: {‘x‘: ‘130‘, ‘y‘: ‘201‘, ‘on‘: ‘1‘}, ‘4‘: {‘x‘: ‘323‘, ‘y‘: ‘0‘, ‘on‘: ‘1‘}, ‘9‘: {‘x‘: ‘139‘, ‘y‘: ‘173‘, ‘on‘: ‘1‘}, ‘2‘: {‘x‘: ‘503‘, ‘y‘: ‘84‘, ‘on‘: ‘1‘}, ‘0‘: {‘x‘: ‘42‘, ‘y‘: ‘353‘, ‘on‘: ‘1‘}, ‘.‘: {‘x‘: ‘20‘, ‘y‘: ‘20‘, ‘on‘: ‘1‘}, } class MaoyanspSpider(scrapy.Spider): name = ‘maoyansp‘ start_urls = [‘https://maoyan.com/films/1212492‘] headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36" } def parse(self, response): font_link = re.findall(r‘vfile.meituan.net/colorstone/(w+.woff)‘, response.text)[0] self.get_font(font_link) self.modify_data(response.body) # 但是直接 decode utf-8 or gbk,又会有奇怪的编码错误 # data.decode(encoding=‘utf-8‘) # todo 修改直接读取返回数据的data,不经过硬盘操作 with open(‘data.html‘, ‘r‘, encoding=‘utf-8‘) as f: data = f.read() self.parse_items(data) def parse_items(self, data): movie_content = etree.HTML(data) movie_content = movie_content.xpath( ‘.//div[@class="movie-stats-container"]/div‘) score = movie_content[0].xpath( ‘.//span[@class="stonefont"]/text()‘)[0] score_num = movie_content[0].xpath( ‘.//span[@class="stonefont"]/text()‘)[1] ticket = movie_content[1].xpath( ‘.//span[@class="stonefont"]/text()‘)[0] ticket_unit = movie_content[1].xpath( ‘.//span[@class="unit"]/text()‘)[0] print(score, ‘分‘, ‘ 共有‘, score_num, ‘人评论‘) print(‘票房:‘, ticket, ticket_unit) def download_font(self, link): download_link = ‘http://vfile.meituan.net/colorstone/‘ + link woff = requests.get(download_link, headers=self.headers) with open(r‘./fonts/‘ + link, ‘wb‘) as f: f.write(woff.content) def get_font(self, link): file_list = os.listdir(r‘.fonts‘) if link not in file_list: self.download_font(link) print("字体不在库中:", link) else: print("字体在库中:", link) self.font = TTFont(‘./fonts/‘ + link) self.transform = ‘./transform/‘ + link.replace(‘.woff‘, ‘.json‘) def modify_data(self, data): trans_form = self.get_transform() for name, num in trans_form.items(): data = data.replace(name.encode(‘gbk‘), num.encode(‘gbk‘)) with open(‘data.html‘, ‘wb‘) as f: f.write(data)def get_transform(self): file_list = os.listdir(r‘. ransform‘) if self.transform in file_list: with open(self.transform, ‘r‘) as f: file = f.read() return json.loads(file) translate_form = self.parse_transform() with open(self.transform, ‘w‘) as f: f.write(json.dumps(translate_form)) return translate_form def parse_transform(self): self.font.saveXML(‘trans.xml‘) tree = etree.parse("trans.xml") TTGlyph = tree.xpath(".//TTGlyph") translate_form = {} for ttg in TTGlyph[1:]: ttg_dic = dict(ttg.attrib) attr_dic = dict(ttg.xpath(‘./contour/pt‘)[0].attrib) name = ttg_dic[‘name‘].replace(‘uni‘, ‘&#x‘).lower() + ‘;‘ ttg_dic.pop(‘name‘) for num, dic in NUM_ATTR.items(): if dic == attr_dic: translate_form[name] = num return translate_form
由于使用的python3,scrapy的response.body是Unicode,所以我只能直接通过这个body来修改内容,但是修改过后的内容直接encode又会报错,但是通过一次文件读写就不会报错了,很奇怪的bug。这点希望有大牛可以指教。
以上是关于前端反爬虫策略--font-face 猫眼数据爬取的主要内容,如果未能解决你的问题,请参考以下文章