stacking融合
Posted liuyicai
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了stacking融合相关的知识,希望对你有一定的参考价值。
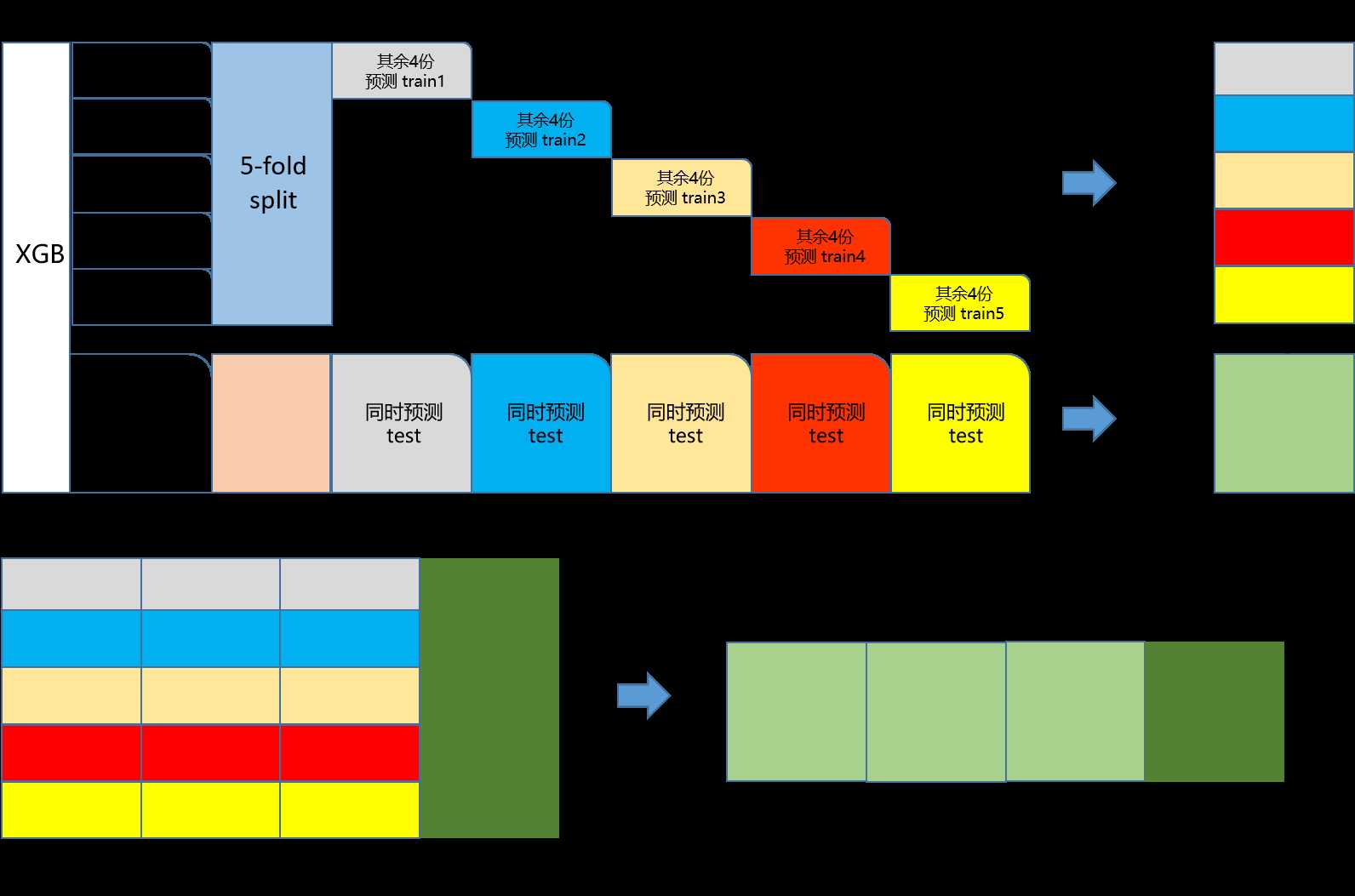
import pandas as pd import numpy as np from sklearn.linear_model import Lasso from sklearn.ensemble import GradientBoostingRegressor from sklearn.pipeline import make_pipeline from sklearn.preprocessing import RobustScaler from sklearn.base import BaseEstimator, TransformerMixin, RegressorMixin, clone from sklearn.model_selection import KFold, cross_val_score, train_test_split import xgboost as xgb import lightgbm as lgb ## 采用stacking的方法训练预测,最终的提交文件为stacking_submit.csv all_train = pd.read_csv(‘all_train.csv‘,sep=‘ ‘) test_set = pd.read_csv(‘test_set.csv‘,sep=‘ ‘) result_name = test_set[[‘USRID‘]] train = all_train.drop([‘USRID‘, ‘FLAG‘], axis=1) y_train = all_train[‘FLAG‘].values test = test_set.drop([‘USRID‘], axis=1) #线下的交叉验证函数 n_folds = 5 def auc_cv(model): kf = KFold(n_folds, shuffle=True, random_state=42).get_n_splits(train.values) auc = cross_val_score(model, train.values, y_train, scoring="roc_auc", cv = kf) return(auc) lasso = make_pipeline(RobustScaler(), Lasso(max_iter=1000,alpha=0.0005,fit_intercept=True,random_state=1)) GBoost = GradientBoostingRegressor(n_estimators=500, learning_rate=0.01, max_depth=18, max_features=‘sqrt‘, min_samples_leaf=16, min_samples_split=10, random_state =5) model_xgb = xgb.XGBRegressor(colsample_bytree=0.9, objective = ‘binary:logistic‘, learning_rate=0.02, max_depth=6, eval_metric = ‘auc‘, min_child_weight=10, n_estimators=842, subsample=0.7, silent=1, random_state =0, nthread = -1) model_lgb = lgb.LGBMRegressor(objective=‘binary‘,metric =‘auc‘,num_leaves=35, learning_rate=0.01, n_estimators=842, max_bin = 55, bagging_fraction = 0.8, bagging_freq = 3, feature_fraction = 0.9, feature_fraction_seed=9, bagging_seed=9, min_data_in_leaf =370, min_sum_hessian_in_leaf = 11) # 单模型的线下得分 score_lasso = auc_cv(lasso) print(" Lasso score: {:.4f} ({:.4f}) ".format(score_lasso.mean(), score_lasso.std())) score_GBoost = auc_cv(GBoost) print("Gradient Boosting score: {:.4f} ({:.4f}) ".format(score_GBoost.mean(), score_GBoost.std())) score_lgb = auc_cv(model_lgb) print("LightGBM score: {:.4f} ({:.4f}) ".format(score_lgb.mean(), score_lgb.std())) score_xgb = auc_cv(model_xgb) print("XGBoost score: {:.4f} ({:.4f}) ".format(score_xgb.mean(), score_xgb.std())) ## 定义stacking的类 class StackingAveragedModels(BaseEstimator, RegressorMixin, TransformerMixin): def __init__(self, base_models, meta_model, n_folds=5): self.base_models = base_models self.meta_model = meta_model self.n_folds = n_folds def fit(self, X, y): self.base_models_ = [list() for x in self.base_models] self.meta_model_ = clone(self.meta_model) kfold = KFold(n_splits=self.n_folds, shuffle=True, random_state=156) out_of_fold_predictions = np.zeros((X.shape[0], len(self.base_models))) ##初始化矩阵 for i, model in enumerate(self.base_models): for train_index, holdout_index in kfold.split(X, y): instance = clone(model) self.base_models_[i].append(instance) ##五折交叉验证,一个基模型有5个instance instance.fit(X[train_index], y[train_index]) y_pred = instance.predict(X[holdout_index]) out_of_fold_predictions[holdout_index, i] = y_pred self.meta_model_.fit(out_of_fold_predictions, y) return self def predict(self, X): meta_features = np.column_stack([ np.column_stack([model.predict(X) for model in base_models]).mean(axis=1) for base_models in self.base_models_]) return self.meta_model_.predict(meta_features) stacked_averaged_models = StackingAveragedModels(base_models = (GBoost,model_xgb,model_lgb), meta_model = lasso) # stacking模型的线下得分 score = auc_cv(stacked_averaged_models) print("Stacking Averaged models score: {:.4f} ({:.4f})".format(score.mean(), score.std())) stacked_averaged_models.fit(train.values, y_train) stacked_pred = stacked_averaged_models.predict(test.values) result_name[‘RST‘] = stacked_pred result_name.to_csv(‘stacking_submit.csv‘,index=None,sep=‘ ‘)
以上是关于stacking融合的主要内容,如果未能解决你的问题,请参考以下文章
Cg入门19:Fragment shader - 片段级模型动态变色