高级视图
Posted liqiongming
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了高级视图相关的知识,希望对你有一定的参考价值。
常用的请求method:
- GET请求:向服务器索取数据,但不会向服务器提交数据,不会对服务器的状态进行更改。比如向服务器获取某篇文章的详情。
- POST请求:向服务器提交数据,会对服务器的状态进行更改。比如提交一篇文章给服务器。
- 限制请求装饰器:Django内置的视图装饰器可以给视图提供一些限制。
django.http.decorators.http.require_http_methods:这个装饰器需要传递一个允许访问的方法的列表。比如只能通过 GET 或 POST 的方式访问。
1 # 导入的装饰器 2 from django.views.decorators.http import require_http_methods,require_GET,require_POST,require_safe
1 # 使用相对安全的方式来访问视图。因为GET和HEAD不会对服务器产生增删改的行为; 2 require_safe = @require_http_methods([‘GET‘,‘HEAD‘]) 3 # 只进行GET请求; 4 require_GET = require_http_methods([‘GET‘]) 5 # 只进行POST请求; 6 require_POST = require_http_methods([‘POST‘])
GET请求:
1 @require_GET 2 def index(requset): 3 # articles = Article(title=‘三国演义‘,content=‘内容。。‘,price=90) 4 # articles.save() 5 # return HttpResponse(‘index‘) 6 # 首页返回所有文章; 7 # 只能使用GET请求来访问这个视图函数; 8 articles = Article.objects.all() 9 return render(requset,‘index.html‘,context={‘articles‘:articles})
POST请求:
1 # 使用POST方法提交数据 2 @require_POST 3 def add_article(request): 4 title = request.POST.get(‘title‘) 5 content = request.POST.get(‘content‘) 6 Article.objects.create(title=title,content=content) 7 return HttpResponse(‘success‘)
两个请求同时存在:
1 # 使用GET请求访问这个视图函数时返回一个添加书籍的html页面; 2 # 当添加书籍时,使用POST请求访问这个视图函数时获取提交的数据,并保存到数据库中; 3 @require_http_methods([‘GET‘,‘POST‘]) 4 def add_book(request): 5 if request.method == ‘GET‘: 6 return render(request,‘add_books.html‘) 7 else: 8 title = request.POST.get(‘title‘) 9 content = request.POST.get(‘content‘) 10 Article.objects.create(title=title,content=content) 11 return HttpResponse(‘success‘)
1 <body> 2 <form action="{% url ‘add_books‘ %}" method="POST"> 3 <table> 4 <tbody> 5 <tr> 6 <td>标题:</td> 7 <td><input type="text" name="title"></td> 8 </tr> 9 <tr> 10 <td>内容:</td> 11 <td><textarea name="content" id="" cols="30" rows="10"></textarea></td> 12 </tr> 13 <tr> 14 <td></td> 15 <td><input type="submit" value="提交"></td> 16 </tr> 17 </tbody> 18 </table> 19 </form> 20 </body>
重定向
- 永久性重定向:http的状态码是301,多用于旧网址被废弃了要转到一个新的网址确保用户的访问;
- 暂时性重定向:http的状态码是302,表示页面的暂时性跳转。如访问一个需要权限的网址,如果当前用户没有登录,应该重定向到登录页面。
(重定向 redirect(to, *args, permanent=False, **kwargs) 。 to :是一个url; permanent :代表的是这个重定向是否是一个永久的重定向,默认是False。)
1 # 没参数传入时进入重定向 2 from django.shortcuts import reverse,redirect 3 def profile(request): 4 if request.GET.get("username"): 5 return HttpResponse("%s,欢迎来到个人中心页面!") 6 else: 7 return redirect(reverse("user:login"))
WSGIRequest对象
Django在接收到http请求之后,会根据http请求携带的参数以及报文信息创建一个WSGIRequest对象,并且作为视图函数第一个参数传给视图函数。也就是request参数。
WSGIRequest对象常用属性:
- path:请求服务器的完整“路径”,但不包含域名和参数。如http://www.baidu.com/xxx/yyy/,那么path就是/xxx/yyy/。
- method:代表当前请求的http方法。比如是GET还是POST。
- GET:一个django.http.request.QueryDict对象。操作起来类似于字典。包含了所有以 ?xxx=xxx 的方式上传上来的参数。
- POST:包含了所有以POST方式上传上来的参数。
- FILES:包含了所有上传的文件。
- COOKIES:一个标准的Python字典,包含所有的cookie,键值对都是字符串类型。
- session:一个类似于字典的对象。用来操作服务器的session。
- META:存储的客户端发送上来的所有header信息。
- CONTENT_LENGTH:请求的正文的长度(是一个字符串)。
- CONTENT_TYPE:请求的正文的MIME类型。
- HTTP_ACCEPT:响应可接收的Content-Type。
- HTTP_ACCEPT_ENCODING:响应可接收的编码。
- HTTP_ACCEPT_LANGUAGE: 响应可接收的语言。
- HTTP_HOST:客户端发送的HOST值。
- HTTP_REFERER:在访问这个页面上一个页面的url。
- QUERY_STRING:单个字符串形式的查询字符串(未解析过的形式)。
- REMOTE_ADDR:客户端的IP地址。如果服务器使用了nginx做反向代理或者负载均衡,那么这个值返回的是127.0.0.1,这时候可以使用HTTP_X_FORWARDED_FOR来获取,所以获取ip地址的代码片段如下:
1 if request.META.has_key(‘HTTP_X_FORWARDED_FOR‘): 2 ip = request.META[‘HTTP_X_FORWARDED_FOR‘] 3 else: 4 ip = request.META[‘REMOTE_ADDR‘]
- REMOTE_HOST:客户端的主机名。
- REQUEST_METHOD:请求方法。一个字符串类似于GET或者POST。
- SERVER_NAME:服务器域名。
- SERVER_PORT:服务器端口号,是一个字符串类型。
WSGIRequest对象常用方法:
- is_secure():是否是采用https协议。
- is_ajax():是否采用ajax发送的请求。判断请求头中是否存在 X-Requested-With:XMLHttpRequest 。
- get_host():服务器的域名。如果在访问的时候还有端口号,那么会加上端口号。如www.baidu.com:9000。
- get_full_path():返回完整的path。如果有查询字符串,还会加上查询字符串。如/music/bands/?print=True。
- get_raw_uri():获取请求的完整url。
QueryDict对象:
(request.GET和request.POST都是QueryDict对象,这个对象继承自dict,用法跟dict相差无几。)
- get方法:用来获取指定key的值,如果没有这个key,那么会返回None。
- getlist方法:如果浏览器上传上来的key对应的值有多个,那么就需要通过这个方法获取。
HttpResponse对象
Django服务器接收到客户端发送过来的请求后,会将提交上来的这些数据封装成一个 HttpRequest对象 传给视图函数。那么视图函数在处理完相关的逻辑后,也需要返回一个响应给浏览器。而这个响应,我们必须返回HttpResponseBase或者他的子类的对象。而HttpResponse则是HttpResponseBase用得最多的子类。
常用属性:
- content:返回的内容。
- status_code:返回的HTTP响应状态码。
- content_type:返回的数据的MIME类型,默认为text/html。浏览器会根据这个属性,来显示数据。如果是text/html,那么就会解析这个字符串,如果text/plain,那么就会显示一个纯文本。常用的Content-Type如下:
- text/html(默认的,html文件)
- text/plain(纯文本)
- text/css(css文件)
- text/javascript(js文件)
- multipart/form-data(文件提交)
- application/json(json传输)
- pplication/xml(xml文件)
- 设置请求头:response[‘X-Access-Token‘] = ‘xxxx‘。
常用方法:
- set_cookie:用来设置cookie信息。后面讲到授权的时候会着重讲到。
- delete_cookie:用来删除cookie信息。
- write:HttpResponse是一个类似于文件的对象,可以用来写入数据到数据体(content)中。
JsonResponse类:
用来对象 dump 成 json 字符串,然后返回将 json 字符串封装成 Response对象 返回给浏览器。并且其 Content-Type 是 application/json 。
1 def jsonresponse_views(request): 2 persons = { 3 ‘username‘:‘jack‘, 4 ‘age‘:18, 5 ‘height‘:180 6 } 7 # 将json字符串封装成response对象;(可直接使用:response = JsonResponse(person),省略下方代码) 8 # persons_str = json.dumps(persons) 9 # response = HttpResponse(persons_str,content_type=‘application/json‘) 10 # return response 11 # 如果传入的参数不是字典,需添加:safe=False;如:JsonResponse(persons,safe=False); 12 response = JsonResponse(persons) 13 return response
生成CSV文件:
- 生成小的CSV文件:
用Python内置的csv模块来处理csv文件,并且使用HttpResponse来将csv文件返回回去。
1 import json,csv 2 3 def csv_views(request): 4 # 生成可作为附件下载的CSV文件; 5 response = HttpResponse(content_type=‘text/csv‘) 6 # 告知浏览器如何处理文件,attachment:不显示并作为附件的形式下载; 7 response[‘Content-Disposition‘] = "attachment;filename=‘abc.csv‘" 8 # writer = csv.writer(response) 9 # writer.writerow([‘username‘,‘age‘]) 10 # writer.writerow([‘jack‘,18]) 11 context = { 12 ‘rows‘: [ 13 [‘username‘,‘age‘], 14 [‘jack‘,18], 15 ] 16 } 17 # 获取模板;并用render方法将context对象填充进模板中; 18 template = loader.get_template(‘abc.txt‘) 19 csv_template = template.render(context) 20 response.content = csv_template 21 return response
Content-Type为text/csv:告诉浏览器,这是一个csv格式的文件而不是一个HTML格式的文件,默认值为 html ,那么浏览器将把csv格式的文件按照html格式输出;
Content-Disposition:告诉浏览器该如何处理这个文件,我们给这个头的值设置为 attachment; ,那么浏览器将不会对这个文件进行显示,而是作为附件的形式下载,第二个 filename="somefilename.csv" :用来指定这个csv文件的名字。
writer:使用csv模块的writer方法,将相应的数据写入到 response 中。
将csv文件定义成模板:将csv格式的文件定义成模板,然后使用Django内置的模板系统,并给这个模板传入一个Context对象,这样模板系统就会根据传入的Context对象,生成具体的csv文件。
模板文件 abc.txt :
1 {% for row in rows %}{{ row.0 }},{{ row.1 }} 2 {% endfor %}
- 生成大的CSV文件:
服务器要生成一个大型csv文件,需要的时间可能会超过浏览器默认的超时时间,需借助另外一个类,叫做 StreamingHttpResponse对象 ,这个对象是将响应的数据作为一个流返回给客户端,而不是作为一个整体返回。
1 def large_csv_views(request): 2 response = StreamingHttpResponse(content_type=‘text/csv‘) 3 response[‘Content-Disposition‘] = "attachment;filename=‘large.csv‘" 4 # 生成器 5 rows = ("Row {},{} ".format(row,row) for row in range(0,10000)) 6 response.streaming_content = rows 7 return response 8 # 使用HTTPResponse方法, 9 # response = HttpResponse(content_type=‘text/csv‘) 10 # response[‘Content-Disposition‘] = "attachment;filename=‘large.csv‘" 11 # writer = csv.writer(response) 12 # for row in range(0,1000000): 13 # writer.writerow([‘Row {}‘.format(row),‘{}‘. format(row)]) 14 # return response
1 # 另一种方法: 2 class Echo: 3 """ 4 定义一个可以执行写操作的类,以后调用csv.writer的时候,就会执行这个方法 5 """ 6 def write(self, value): 7 return value 8 9 def large_csv(request): 10 rows = (["Row {}".format(idx), str(idx)] for idx in range(655360)) 11 pseudo_buffer = Echo() 12 writer = csv.writer(pseudo_buffer) 13 response = StreamingHttpResponse((writer.writerow(row) for row in rows),content_type="text/csv") 14 response[‘Content-Disposition‘] = ‘attachment; filename="somefilename.csv"‘ 15 return response
构建一个非常大的数据集rows,并且将其变成一个迭代器。因为 StreamingHttpResponse 的第一个参数只能是一个生成器,因此使用圆括号 (writer.writerow(row) for row in rows) ,且因为文件是csv格式的文件,需调用 writer.writerow 将row变成一个csv格式的字符串,调用时需要一个中间的容器,因此定义一个实现一个write方法的类 Echo ,以后在执行 csv.writer(pseudo_buffer) 的时候,就会调用 Echo.writer 方法。
关于StreamingHttpResponse:
这个类是专门用来处理流数据的。在处理一些大型文件的时候,不会因为服务器处理时间过长而到时连接超时。该类不是继承自 HttpResponse ,两者有以下几点区别:
-
- 该类没有属性 content ,相反是 streaming_content 。
- 该类的 streaming_content 必须是一个可以迭代的对象。
- 该类没有 write 方法,如果给这个类的对象写入数据将会报错。
注意:StreamingHttpResponse会启动一个进程来和客户端保持长连接,所以会很消耗资源。如不是特殊要求,尽量少用这种方法。
类视图
Django除了使用函数作为视图,也可以使用类作为视图。使用类视图可以使用类的一些特性,比如继承等。
View:
django.views.generic.base.View 是主要的类视图,所有的类视图都是继承自他。再根据当前请求的method,来实现不同的方法。如:get方法: get(self,request,*args,**kwargs);post方法: post(self,request,*args,**kwargs) ;
1 from django.views import View 2 3 class BookListView(View): 4 def get(self,request,*args,**kwargs): 5 return render(request,‘article.html‘) 6 7 # url映射 8 urlpatterns = [ 9 path("artilce/",views.BookListView.as_view(),name=‘article‘) 10 ]
除了get方法,View还支持以下方法[‘get‘,‘post‘,‘put‘,‘patch‘,‘delete‘,‘head‘,‘options‘,‘trace‘]。
如果访问了View中没有定义的方法。如类视图只支持get方法,而出现了post方法,那么就会把这个请求转发给 http_method_not_allowed(request,*args,**kwargs) ;
1 # 使用ListView实现列表功能; 2 def add_article(request): 3 articles = [] 4 for x in range(0,101): 5 article = Article(title=‘标题:%s‘ %x,content="内容:%s" %x) 6 articles.append(article) 7 Article.objects.distinct(articles) 8 9 return HttpResponse(‘success‘) 10 11 class ArticleListView(ListView): 12 model = Article 13 template_name = ‘article_list.html‘ 14 paginate_by = 10 15 context_object_name = ‘articles‘ 16 ordering = ‘create_time‘ 17 page_kwarg = ‘page‘ 18 19 # 为context添加新的参数; 20 def get_context_data(self, **kwargs): 21 context = super(ArticleListView, self).get_context_data(**kwargs) 22 context[‘username‘] = ‘jack‘ 23 # print(page_obj.next_page_number()) # 下一页的页码;运行这条代码会使网页最后一页无法显示; 24 print(context) 25 return context 26 27 # 该类默认返回的函数,得到所有的值,可重新自定义; 28 def get_queryset(self): 29 # return Article.objects.all() 30 return Article.objects.filter(id__lte=101)
首先 ArticleListView 是继承自 ListView 。
- model:重写model类属性,指定这个列表是给哪个模型的。
- template_name:指定这个列表的模板。
- paginate_by:指定这个列表一页中展示多少条数据。
- context_object_name:指定这个列表模型在模板中的参数名称。
- ordering:指定这个列表的排序方式。
- page_kwarg:获取第几页的数据的参数名称。默认是page。
- get_context_data:获取上下文的数据。
- get_queryset:如果你提取数据的时候,并不是要把所有数据都返回,那么你可以重写这个方法。将一些不需要展示的数据给过滤掉。
Paginator和Page类:
Paginator和Page类都是用来做分页的。他们在Django中的路径为 django.core.paginator.Paginator 和 django.core.paginator.Page 。
Paginator常用属性和方法:
- count:总共有多少条数据。
- num_pages:总共有多少页。
- page_range:页面的区间。比如有三页,那么就range(1,4)。
Page常用属性和方法:
- has_next:是否还有下一页。
- has_previous:是否还有上一页。
- next_page_number:下一页的页码。
- previous_page_number:上一页的页码。
- number:当前页。
- start_index:当前这一页的第一条数据的索引值。
- end_index:当前这一页的最后一条数据的索引值。
给类视图添加装饰器:
1 # 直接装饰在整个类上: 2 def login_views(func): 3 def wrapper(request,*args,**kwargs): 4 username = request.GET.get(‘username‘) 5 if username: 6 return func(request,*args,**kwargs) 7 else: 8 return redirect(reverse(‘front:login‘)) 9 return wrapper 10 11 def login(request): 12 return HttpResponse(‘login‘) 13 14 @method_decorator(login_views,name=‘dispatch‘) 15 class ProfileView(View): 16 def get(self,request): 17 return HttpResponse(‘个人中心‘)
错误处理
常用的错误码:
- 404:服务器没有指定的url。
- 403:没有权限访问相关的数据。
- 405:请求的method错误。
- 400:bad request,请求的参数错误。
- 500:服务器内部错误,一般是代码出bug了。
- 502:一般部署的时候见得比较多,一般是nginx启动了,然后uwsgi有问题。
自定义错误模板:
碰到如404,500错误的时候,想要返回自己定义的模板。可以直接在 templates 文件夹下创建相应错误代码的 html 模板文件。以后在发生相应错误后,会返回指定的模板。
其它错误的处理:
其他错误类型可以专门定义一个app,用来处理这些错误。
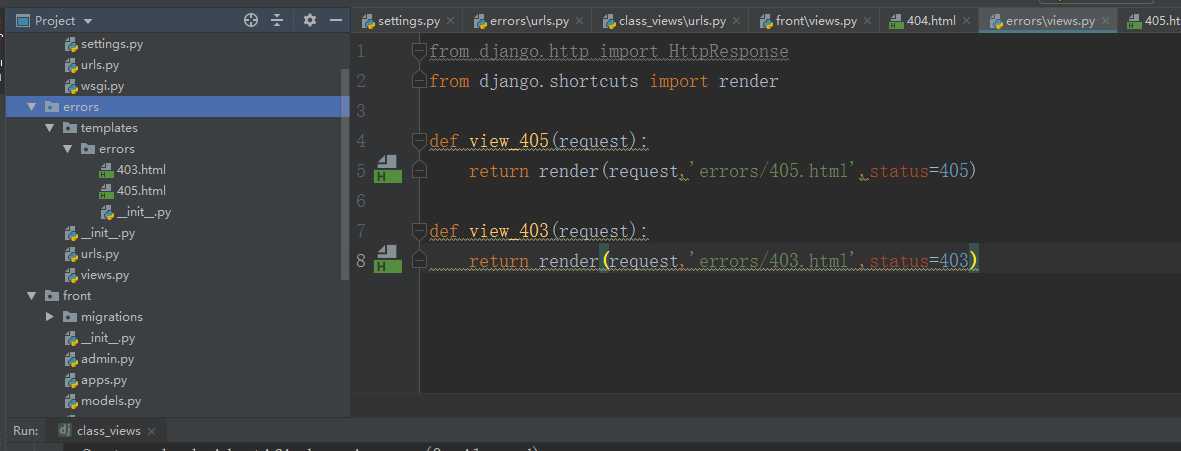
1 # 访问时跳转到errors定义的模板上 2 def login_views(request): 3 username = request.GET.get(‘username‘) 4 if not username: 5 return redirect(reverse(‘errors:403‘)) 6 return HttpRespont("首页")
以上是关于高级视图的主要内容,如果未能解决你的问题,请参考以下文章