ZooKeeper
Posted xuejiale
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ZooKeeper相关的知识,希望对你有一定的参考价值。
一、理论篇(一)
1.1 概述
Zookeeper是一个开源的分布式的,为分布式应用提供协调服务的Apache项目。
Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper就将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应,从而实现集群中类似Master/Slave管理模式
Zookeeper=文件系统+通知机制
1.2 应用场景
提供的服务包括:
- 分布式消息同步和协调机制
- 服务器节点动态上下线
- 统一配置管理
- 负载均衡
- 集群管理等
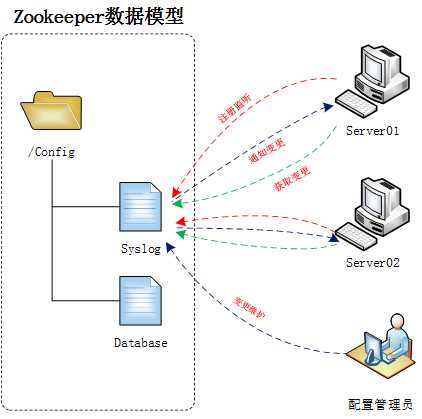
1)典型应用场景 – 数据发布与订阅
(1)集中式配置中心(推 + 拉)
(2)应用启动时主动到Zookeeper上获取配置信息,并注册Watcher监听。
(3)配置管理员变更Zookeeper配置节点的内容。
(4)Zookeeper推送变更到应用,触发Watcher回调函数。
(5)应用根据逻辑,主动获取新的配置信息,更改自身逻辑。
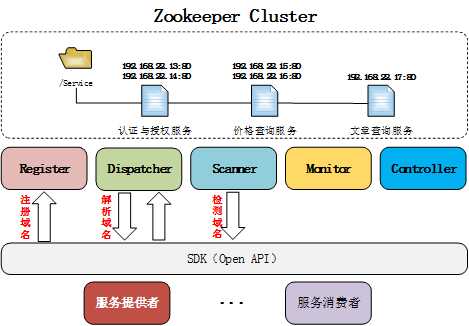
2)典型应用场景 – 软负载均衡
(1)Register负责域名的注册,服务启动后将域名信息通过Register注册到Zookeeper相对应的域名服务下。
(2)Dispatcher负责域名的解析。可以实现软负载均衡。
(3)Scanner通过定时监测服务状态,动态更新节点地址信息。
(4)Monitor负责收集服务信息与状态监控。
(5)Controller提供后台Console,提供配置管理功能。
3)典型应用场景 – 集群管理
- 有多少机器在工作?
- 每台机器的运行状态收集
- 对集群中设备进行上下线操作。
- 分布式任务的状态汇报
- …
1.3. 下载地址
1)官网首页:
https://zookeeper.apache.org/
2)下载截图
二、Zookeeper实战篇(一)
2.1 本地模式安装部署
1)安装前准备:
(1)安装jdk,见博客 https://www.cnblogs.com/xuejiale/p/10504845.html
(2)下载zookeeper并上传到Linux环境上,我下载的是 zookeeper-3.4.12.tar.gz(也可以下载最新稳定版本)
(3)将 zookeeper-3.4.12.tar.gz 解压到指定目录,我指定的目录是 /opt/module
[[email protected] module]# tar -zxvf zookeeper-3.4.12.tar.gz -C /opt/module/
2)配置修改
将/opt/module/ zookeeper-3.4.12/conf这个路径下的zoo_sample.cfg修改为zoo.cfg;
进入zoo.cfg文件:vim zoo.cfg
修改dataDir路径为
dataDir=/opt/module/ zookeeper-3.4.12/data/zkData
在/opt/module/ zookeeper-3.4.12/这个目录中创建data/zkData文件夹
mkdir -p data/zkData
3)操作zookeeper
(1)启动zookeeper
[[email protected] zookeeper-3.4.12]# ./bin/zkServer.sh start
启动结果:

(2)查看进程是否启动
[[email protected] zookeeper-3.4.12]# jps
查看结果:
JPS 名称: jps - Java Virtual Machine Process Status Tool 命令用法: jps [options] [hostid] options:命令选项,用来对输出格式进行控制 hostid:指定特定主机,可以是ip地址和域名, 也可以指定具体协议,端口。 [protocol:][[//]hostname][:port][/servername] 功能描述: jps是用于查看有权访问的hotspot虚拟机的进程. 当未指定hostid时,默认查看本机jvm进程,否择查看指定的hostid机器上的jvm进程,
此时hostid所指机器必须开启jstatd服务。 jps可以列出jvm进程lvmid,主类类名,main函数参数, jvm参数,jar名称等信息。
(3)查看状态:
[[email protected] zookeeper-3.4.12]# ./bin/zkServer.sh status
查看结果:

(4)启动 zookeeper 客户端并操作 zookeeper:
[[email protected] zookeeper-3.4.12]# ./bin/zkCli.sh
客户端命令行操作:
|
命令基本语法 |
功能描述 |
|
help |
显示所有操作命令 |
|
ls path [watch] |
使用 ls 命令来查看当前znode中所包含的内容 |
|
ls2 path [watch] |
查看当前节点数据并能看到更新次数等数据 |
|
create |
普通创建 -s 含有序列 -e 临时(重启或者超时消失) |
|
get path [watch] |
获得节点的值 |
|
set |
设置节点的具体值 |
|
stat |
查看节点状态 |
|
delete |
删除节点 |
|
rmr |
递归删除节点 |
- 显示所有操作命令
[zk: localhost:2181(CONNECTED) 0] help ZooKeeper -server host:port cmd args stat path [watch] set path data [version] ls path [watch] delquota [-n|-b] path ls2 path [watch] setAcl path acl setquota -n|-b val path history redo cmdno printwatches on|off delete path [version] sync path listquota path rmr path get path [watch] create [-s] [-e] path data acl addauth scheme auth quit getAcl path close connect host:port
- 查看当前znode中所包含的内容
[zk: localhost:2181(CONNECTED) 1] ls / [cluster, controller_epoch, brokers, zookeeper, admin, isr_change_notification, consumers, log_dir_event_notification, latest_producer_id_block, config]
- 查看当前节点数据并能看到更新次数等数据
[zk: localhost:2181(CONNECTED) 2] ls2 / [cluster, controller_epoch, brokers, zookeeper, admin, isr_change_notification, consumers, log_dir_event_notification, latest_producer_id_block, config] cZxid = 0x0 ctime = Thu Jan 01 08:00:00 CST 1970 mZxid = 0x0 mtime = Thu Jan 01 08:00:00 CST 1970 pZxid = 0x192 cversion = 34 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 0 numChildren = 10
- 创建普通节点
[zk: localhost:2181(CONNECTED) 0] create /normalNode normalData Created /normalNode
- 获得节点的值
[zk: localhost:2181(CONNECTED) 1] get /normalNode normalData cZxid = 0x1b5 ctime = Sat Apr 06 15:26:16 CST 2019 mZxid = 0x1b5 mtime = Sat Apr 06 15:26:16 CST 2019 pZxid = 0x1b5 cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 10 numChildren = 0
- 创建短暂节点
[zk: localhost:2181(CONNECTED) 3] create -e /tempNode 0000
Created /tempNode
(1)在当前客户端是能查看到的
[zk: localhost:2181(CONNECTED) 4] ls /
[cluster, controller_epoch, brokers, zookeeper, admin, isr_change_notification, consumers, log_dir_event_notification, tempNode, latest_producer_id_block, config]
(2)退出当前客户端然后再重启启动客户端并查看根目录下短暂节点已经删除
[zk: localhost:2181(CONNECTED) 0] ls /
[cluster, controller_epoch, brokers, zookeeper, admin, isr_change_notification, consumers, log_dir_event_notification, latest_producer_id_block, config]
- 创建带序号的节点
(1)先创建一个普通的根节点 /rootNode,数据为 rootData
[zk: localhost:2181(CONNECTED) 1] create /rootNode rootData
Created /rootNode
(2)创建带序号的节点
[zk: localhost:2181(CONNECTED) 2] create -s /rootNode/sonSort 000
Created /rootNode/sonSort0000000000
[zk: localhost:2181(CONNECTED) 3] get /rootNode/sonSort
Node does not exist: /rootNode/sonSort
[zk: localhost:2181(CONNECTED) 4] get /rootNode/sonSort0000000000
000
cZxid = 0x19e
ctime = Sat Apr 06 15:14:14 CST 2019
mZxid = 0x19e
mtime = Sat Apr 06 15:14:14 CST 2019
pZxid = 0x19e
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 3
numChildren = 0
[zk: localhost:2181(CONNECTED) 5] create -s /rootNode/sonSort1 001
Created /rootNode/sonSort10000000001
[zk: localhost:2181(CONNECTED) 6] create -s /rootNode/sonSort2 002
Created /rootNode/sonSort20000000002
注意:如果原节点下有1个节点,则再排序时从1开始,以此类推。
[zk: localhost:2181(CONNECTED) 12] create /parentNode root
Created /parentNode
[zk: localhost:2181(CONNECTED) 13] create /parentNode/sonNode son
Created /parentNode/sonNode
[zk: localhost:2181(CONNECTED) 14] create -s /parentNode/sonNode son1
Created /parentNode/sonNode0000000001
- 修改节点数据值
[zk: localhost:2181(CONNECTED) 2] set /normalNode newNormalData cZxid = 0x1b5 ctime = Sat Apr 06 15:26:16 CST 2019 mZxid = 0x1b6 mtime = Sat Apr 06 15:28:16 CST 2019 pZxid = 0x1b5 cversion = 0 dataVersion = 1 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 13 numChildren = 0 [zk: localhost:2181(CONNECTED) 3] get /normalNode newNormalData cZxid = 0x1b5 ctime = Sat Apr 06 15:26:16 CST 2019 mZxid = 0x1b6 mtime = Sat Apr 06 15:28:16 CST 2019 pZxid = 0x1b5 cversion = 0 dataVersion = 1 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 13 numChildren = 0
- 节点的值变化监听
起一个客户端1 注册监听 /normalNode 节点数据变化:
[zk: localhost:2181(CONNECTED) 5] get /normalNode watch newNormalData cZxid = 0x1b5 ctime = Sat Apr 06 15:26:16 CST 2019 mZxid = 0x1b6 mtime = Sat Apr 06 15:28:16 CST 2019 pZxid = 0x1b5 cversion = 0 dataVersion = 1 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 13 numChildren = 0
再开启另一个客户端2,修改 /normalNode 节点数据:
[zk: localhost:2181(CONNECTED) 0] set /normalNode modifyNewData cZxid = 0x1b5 ctime = Sat Apr 06 15:26:16 CST 2019 mZxid = 0x1bb mtime = Sat Apr 06 15:31:36 CST 2019 pZxid = 0x1b5 cversion = 0 dataVersion = 2 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 13 numChildren = 0
再来观察客户端1收到数据变化的监听:
[zk: localhost:2181(CONNECTED) 6] WATCHER:: WatchedEvent state:SyncConnected type:NodeDataChanged path:/normalNode
- 节点的子节点变化监听(路径变化)
起一个客户端1,注册监听 /normalNode 子节点变化:
[zk: localhost:2181(CONNECTED) 10] ls /normalNode watch []
再开启另一个客户端2,创建 /normalNode/sonNode 子节点,数据为 sonData:
[zk: localhost:2181(CONNECTED) 2] create /normalNode/sonNode sonData Created /normalNode/sonNode
再来观察客户端1收到数据变化的监听:
[zk: localhost:2181(CONNECTED) 11] WATCHER:: WatchedEvent state:SyncConnected type:NodeChildrenChanged path:/normalNode
- 删除节点
[zk: localhost:2181(CONNECTED) 7] ls /normalNode [sonNode] [zk: localhost:2181(CONNECTED) 8] delete /normalNode/sonNode [zk: localhost:2181(CONNECTED) 9] ls /normalNode []
- 递归删除节点
[zk: localhost:2181(CONNECTED) 10] create /normalNode/sonNode2 sonData2 Created /normalNode/sonNode2 [zk: localhost:2181(CONNECTED) 11] ls /normalNode [sonNode2] [zk: localhost:2181(CONNECTED) 12] delete /normalNode Node not empty: /normalNode [zk: localhost:2181(CONNECTED) 13] ls / [cluster, controller_epoch, brokers, zookeeper, normalNode2, admin, isr_change_notification, consumers, log_dir_event_notification, latest_producer_id_block, normalNode, config] [zk: localhost:2181(CONNECTED) 14] rmr /normalNode [zk: localhost:2181(CONNECTED) 15] ls / [cluster, controller_epoch, brokers, zookeeper, normalNode2, admin, isr_change_notification, consumers, log_dir_event_notification, latest_producer_id_block, config] [zk: localhost:2181(CONNECTED) 16]
- 查看节点状态
[zk: localhost:2181(CONNECTED) 16] create /app appData Created /app [zk: localhost:2181(CONNECTED) 17] stat /app cZxid = 0x1ce ctime = Sat Apr 06 15:49:23 CST 2019 mZxid = 0x1ce mtime = Sat Apr 06 15:49:23 CST 2019 pZxid = 0x1ce cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 7 numChildren = 0
注意:rmr为递归删除,delete只能删除没有子节点的节点。
(5)退出客户端:
[zk: localhost:2181(CONNECTED) 0] quit Quitting... 2019-04-06 11:46:49,313 [myid:] - INFO [main:[email protected]687] - Session: 0x1000048aefc0004 closed 2019-04-06 11:46:49,315 [myid:] - INFO [main-EventThread:[email protected]521] - EventThread shut down for session: 0x1000048aefc0004
(6)停止zookeeper
[[email protected] zookeeper-3.4.12]# ./bin/zkServer.sh stop
查看结果:

2.2 配置参数解读
解读zoo.cfg 文件中参数含义
# The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataDir=/opt/module/zookeeper-3.4.12/data/zkData # the port at which the clients will connect clientPort=2181 # the maximum number of client connections. # increase this if you need to handle more clients #maxClientCnxns=60 # # Be sure to read the maintenance section of the # administrator guide before turning on autopurge. # # http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance # # The number of snapshots to retain in dataDir #autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature #autopurge.purgeInterval=1
1)tickTime:通信心跳数,Zookeeper服务器心跳时间,单位毫秒
Zookeeper使用的基本时间,服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个tickTime时间就会发送一个心跳,时间单位为毫秒。
它用于心跳机制,并且设置最小的session超时时间为两倍心跳时间。(session的最小超时时间是2*tickTime)
2)initLimit:LF初始通信时限
集群中的follower跟随者服务器(F)与leader领导者服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量),用它来限定集群中的Zookeeper服务器连接到Leader的时限。
投票选举新leader的初始化时间
Follower在启动过程中,会从Leader同步所有最新数据,然后确定自己能够对外服务的起始状态。
Leader允许F在initLimit时间内完成这个工作。
3)syncLimit:LF同步通信时限
集群中Leader与Follower之间的最大响应时间单位,假如响应超过syncLimit * tickTime,
Leader认为Follwer死掉,从服务器列表中删除Follwer。
在运行过程中,Leader负责与ZK集群中所有机器进行通信,例如通过一些心跳检测机制,来检测机器的存活状态。
如果L发出心跳包在syncLimit之后,还没有从F那收到响应,那么就认为这个F已经不在线了。
4)dataDir:数据文件目录+数据持久化路径
保存内存数据库快照信息的位置,如果没有其他说明,更新的事务日志也保存到数据库。
5)clientPort:客户端连接端口
监听客户端连接的端口
三、Zookeeper理论篇(二)
3.1 数据结构
ZooKeeper数据模型的结构与Unix文件系统很类似,整体上可以看作是一棵树,每个节点称做一个ZNode。
很显然zookeeper集群自身维护了一套数据结构。这个存储结构是一个树形结构,其上的每一个节点,我们称之为"znode",每一个znode默认能够存储1MB的数据,每个ZNode都可以通过其路径唯一标识。
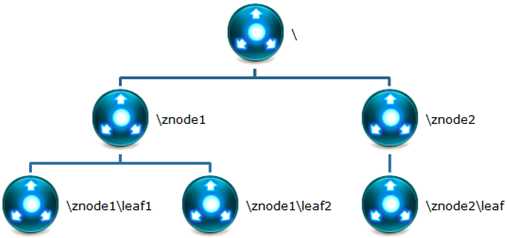
数据结构图
3.2 节点类型
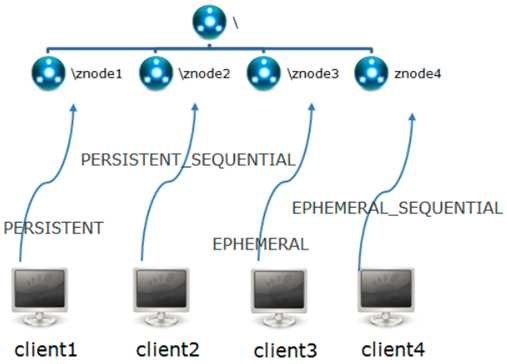
1)Znode有两种类型:
短暂(ephemeral):客户端和服务器端断开连接后,创建的节点自己删除
持久(persistent):客户端和服务器端断开连接后,创建的节点不删除
2)Znode有四种形式的目录节点(默认是persistent )
(1)持久化目录节点(PERSISTENT)
客户端与zookeeper断开连接后,该节点依旧存在
(2)持久化顺序编号目录节点(PERSISTENT_SEQUENTIAL)
客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
(3)临时目录节点(EPHEMERAL)
客户端与zookeeper断开连接后,该节点被删除
(4)临时顺序编号目录节点(EPHEMERAL_SEQUENTIAL)
客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
3)创建znode时设置顺序标识,znode名称后会附加一个值,顺序号是一个单调递增的计数器,由父节点维护
4)在分布式系统中,顺序号可以被用于为所有的事件进行全局排序,这样客户端可以通过顺序号推断事件的顺序
3.3 特点
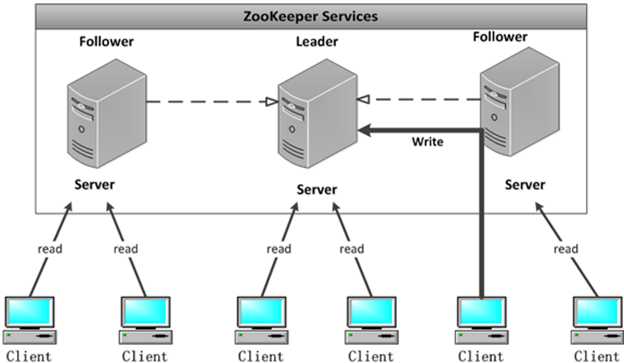
1)Zookeeper:一个领导者(leader),多个跟随者(follower)组成的集群。
2)Leader负责进行投票的发起和决议,更新系统状态
3)Follower用于接收客户请求并向客户端返回结果,在选举Leader过程中参与投票
4)集群中只要有半数以上节点存活,Zookeeper集群就能正常服务。
5)全局数据一致:每个server保存一份相同的数据副本,client无论连接到哪个server,数据都是一致的。
6)更新请求顺序进行,来自同一个client的更新请求按其发送顺序依次执行。
7)数据更新原子性,一次数据更新要么成功,要么失败。
8)实时性,在一定时间范围内,client能读到最新数据。
3.4 选举机制
1)半数机制:集群中半数以上机器存活,集群可用。所以zookeeper适合装在奇数台机器上。
2)Zookeeper虽然在配置文件中并没有指定master和slave。但是,zookeeper工作时,是有一个节点为leader,其他则为follower,Leader是通过内部的选举机制临时产生的
3)以一个简单的例子来说明整个选举的过程。
假设有五台服务器组成的zookeeper集群,它们的id从1-5,同时它们都是最新启动的,也就是没有历史数据,在存放数据量这一点上,都是一样的。假设这些服务器依序启动,来看看会发生什么。
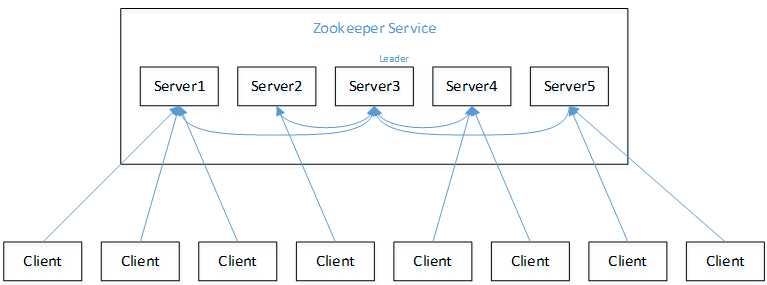
(1)服务器1启动,此时只有它一台服务器启动了,它发出去的报没有任何响应,所以它的选举状态一直是LOOKING状态。
(2)服务器2启动,它与最开始启动的服务器1进行通信,互相交换自己的选举结果,由于两者都没有历史数据,所以id值较大的服务器2胜出,但是由于没有达到超过半数以上的服务器都同意选举它(这个例子中的半数以上是3),所以服务器1、2还是继续保持LOOKING状态。
(3)服务器3启动,根据前面的理论分析,服务器3成为服务器1、2、3中的老大,而与上面不同的是,此时有三台服务器选举了它,所以它成为了这次选举的leader。
(4)服务器4启动,根据前面的分析,理论上服务器4应该是服务器1、2、3、4中最大的,但是由于前面已经有半数以上的服务器选举了服务器3,所以它只能接收当小弟的命了。
(5)服务器5启动,同4一样当小弟。
3.5 stat结构体
1)czxid- 引起这个znode创建的zxid,创建节点的事务的zxid(ZooKeeper Transaction Id)
每次修改ZooKeeper状态都会收到一个zxid形式的时间戳,也就是ZooKeeper事务ID。
事务ID是ZooKeeper中所有修改总的次序。每个修改都有唯一的zxid,如果zxid1小于zxid2,那么zxid1在zxid2之前发生。
2)ctime - znode被创建的毫秒数(从1970年开始)
3)mzxid - znode最后更新的zxid
4)mtime - znode最后修改的毫秒数(从1970年开始)
5)pZxid-znode最后更新的子节点zxid
6)cversion - znode子节点变化号,znode子节点修改次数
7)dataversion - znode数据变化号
8)aclVersion - znode访问控制列表的变化号
9)ephemeralOwner- 如果是临时节点,这个是znode拥有者的session id。如果不是临时节点则是0。
10)dataLength- znode的数据长度
11)numChildren - znode子节点数量
3.6 监听器原理

监听器是一个接口,我们的代码中可以实现Wather这个接口,实现其中的process方法,方法中即我们自己的业务逻辑
监听器的注册是在获取数据的操作中实现:
getData(path,watch?)监听的事件是:节点数据变化事件
getChildren(path,watch?)监听的事件是:节点下的子节点增减变化事件
四、Zookeeper实战篇(二)
4.1 分布式安装部署
待续
4.2 API应用
待续
监听服务器节点动态上下线案例:
1)需求:某分布式系统中,主节点可以有多台,可以动态上下线,任意一台客户端都能实时感知到主节点服务器的上下线
2)需求分析
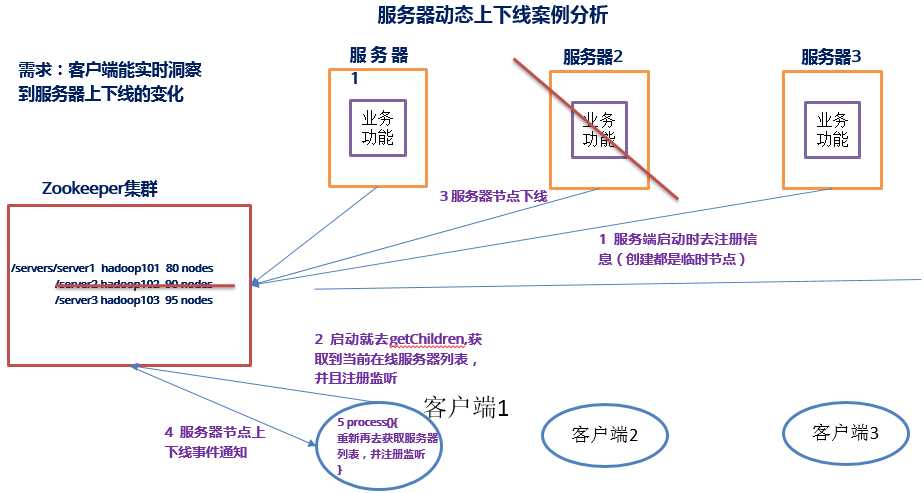
3)具体实现
待续
参考文献:
- www.atguigu.com (来自互联网尚硅谷的大数据培训word文档学习)
- https://blog.csdn.net/liyiming2017/article/details/83035157 (很好的博客,很通俗易懂。可以参考学习)
- http://zookeeper.apache.org/doc/r3.4.14/index.html (官网也是最好的学习资料)
以上是关于ZooKeeper的主要内容,如果未能解决你的问题,请参考以下文章