***列表和字典在底层中 谁更快***
Posted jiazeng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了***列表和字典在底层中 谁更快***相关的知识,希望对你有一定的参考价值。
字典生成慢,查找快。
列表生成快,查找慢。
如果是数据多,经常需要查询,务必使用字典。
请看??
思路:
生成一个很大的文本文件 分别用列表和字典来存储数据,然后读取并搜索数据 考察列表和字典做为数据结构的时候,存储的时间,搜索和访问的时间 计算两种方案的消耗时间 1.创建百万字符文件 我们需要一个较大的文件,来证明我们的猜想!干脆直接生成一个有百万行的字符串乱码文件。 1).产生一串随机字符: 取一些随机的字符,包括数字,字符,标点和符号等等,一共95个随机字符
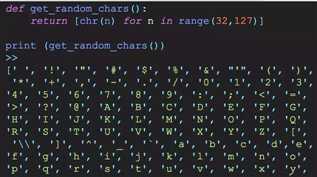
2).把字符序列,进行随机化分布 def create_random_nums(nums=None): random.shuffle(nums) return nums 直接用random模块,把字符串序列随机化. 3).随机100万行的字符序列,写入文件 def create_file(): chars=get_random_chars() for i in range(1000000): with open(‘data.txt‘,‘at‘) as f: data=create_random_nums(chars) f.writelines(data) f.write(‘ ‘) 用个大循环把随机的字符串写入文件中,大概有一百万行,文件大小在100M左右,这里只是试例代码,其实可以用并发写更快一点。
2.用列表做数据结构
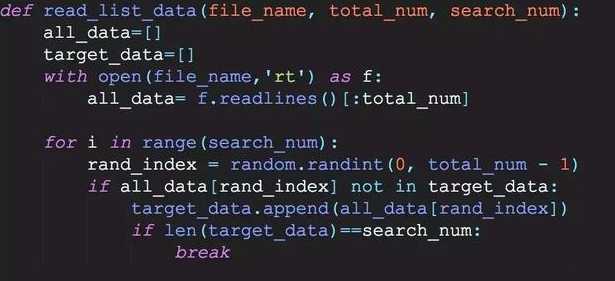
先从百万行随机字符串文件中,读取一定数量的数据(10000行数据), 存入10000行放入all_data列表 接着从10000行all_data列表里面随机取1000行 放到一个target_data列表 最后搜索这个target_data列表 3.用字典做数据结构 我们用相同的场景,用字典作为数据结构容器,从百万文件中来读取数据。 考察字典的存储数据的时间,以及字典中的搜索数据的时间。
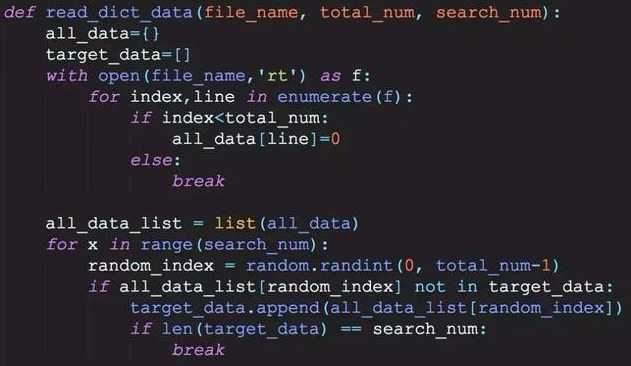
后面跟个 return all_data,target_data
先从百万行字符串文件中,读取一定数量的字符(假如为10000行)
存到到字典里面,把每一行做为key
接着提取这个字典里面的key,把这个10000行的数据,转为列表
从10000行里面随机取1000行出来,放到target_data列表
4.计算运行时间
我们计算两种数据结构运行的时间,为了更准确。我们运行100次求均值
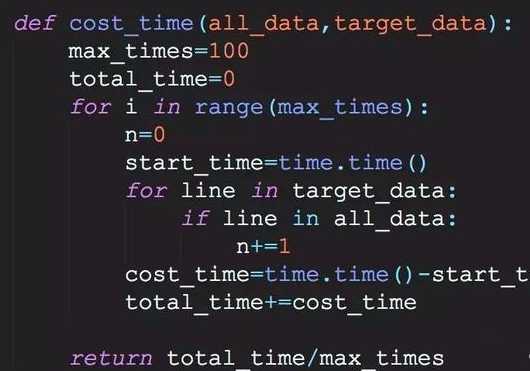
看一下用列表消耗的时间: all_data, target_data = read_list_data(file_name, 100000, 1000) cost=cost_time(all_data,target_data) print (cost) 0.09532666921615601秒 看一些用字典消耗的时间: all_data, target_data = read_dict_data(file_name, 100000, 1000) cost=cost_time(all_data,target_data) print (cost) 0.00016084909439086914秒 字典的性能是列表的600倍,可见字典作为数据结构,会快快快很多!尤其是非常大的数据存储和读取的时候。 既然字典这么快,那么线性增加搜索,看看耗时如何,刚才是1×××面搜1千,现在我们从二十万搜1千看看,1百×××面搜1千看看。 all_data, target_data = read_dict_data(file_name, 200000, 1000) cost=cost_time(all_data,target_data) print (cost) 0.00014181852340698243 all_data, target_data = read_dict_data(file_name, 1000000, 1000) cost=cost_time(all_data,target_data) print (cost) 0.00022308111190795897 发现消耗的时间差不多 结论: 为啥字典性能比列表快这么多?这要从字典和列表的原理说起,字典其实是散列表或者说是哈希表!内部存储的时候是根据hash地址来搜索的,搜索的时候不需要从头开始搜索,这也就是为啥哈希表变大,20万和100万的查询的速度差不多! 而列表是什么,Python列表是一种顺序线性表,好处是插入,移除比较快速,但是搜索会慢很多! 综上所述,由于Python中字典的性能远高于列表,Python源码中很多底层的对象都是用字典类型,只要重载hash魔法函数,让它返回一个可哈希的对象,这样的对象就可以用做字典的key。小伙伴今天是不是又学到一招!
以上是关于***列表和字典在底层中 谁更快***的主要内容,如果未能解决你的问题,请参考以下文章