RDD动作算子(action)
Posted jiajiaba
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RDD动作算子(action)相关的知识,希望对你有一定的参考价值。
RDD的动作算子
reduce(func)
通过func函数聚集RDD中的所有元素,这个功能必须是可交换且可并联的。(符合结合律和交换律),func输入为两个元素,返回为一个元素。
def add(x,y): return x+y sc.parallelize([1, 2, 3, 4, 5]).reduce(add) #结果 15collect()
以列表的形式返回数据集的所有元素
sc.parallelize([1, 2, 3, 4, 5]).collect() #结果 [1,2,3,4,5]count()
返回RDD的元素个数
sc.parallelize([2, 3, 4]).count() #结果 3first()
返回RDD的第一个元素(类似与take(1))
sc.parallelize([2,3,4]).first() #结果 2take(n)
返回一个由数据集的前n个元素组成的数组
sc.parallelize([1,2,3,4,5]).take(3) #结果 [1,2,3]foreach(func)
将一个函数应用于此RDD的所有元素。
def f(x): print(x) sc.parallelize([1,2,3]).foreach(f) #结果 1 2 3top(num)
返回RDD内部元素的前n个最大值
sc.parallelize([2,3,4]).top(2) #结果 [4,3]saveAsTextFile(path)
将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本
sc.parallelize([2,3,4]).saveAsTextFile('/home/hadoop/0444') cd 0444/ cat part-00000 #结果 2 3 4aggregate(zeroValue, seqOp, combOp)
操作的初始值是zeroValue,seqOp是聚合各分区中的元素,combop是将聚合各分区中元素的结果再次进行聚合
rdd1 = sc.parallelize([1,2,3,4,5],2)
result2 = rdd1.aggregate(0,lambda x,y:max(x,y),lambda x,y:x+y)
print(result2)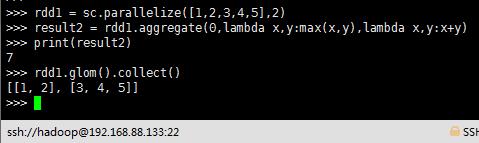
result3 = rdd1.aggregate(0,lambda x,y:x+y,lambda x,y:x+y)
print(result3)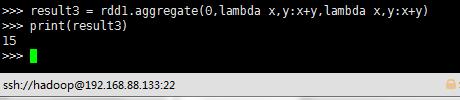
result4 = rdd1.aggregate(10,lambda x,y:max(x,y),lambda x,y:x+y)
print(result4)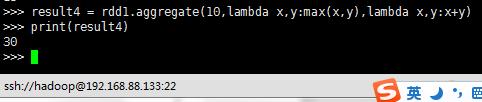
rdd1 = sc.parallelize(["a","b","c","d","e","f"],2)
result5 = rdd1.aggregate("",lambda x,y:x+y,lambda x,y:x+y)
print(result5)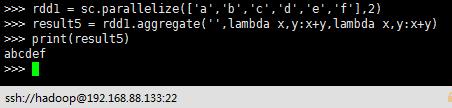
result6 = rdd1.aggregate("|",lambda x,y:x+y,lambda x,y:x+y)
print(result6)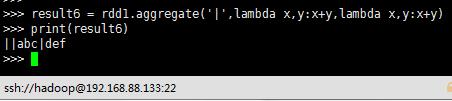
rdd7=sc.parallelize(["12","23","345","4567"],2)
rdd7.aggregate('',lambda x,y:max(len(str(x)),len(str(y))),lambda x,y:str(x)+str(y))
以上是关于RDD动作算子(action)的主要内容,如果未能解决你的问题,请参考以下文章