hbase coprocessor 二级索引
Posted xiguage119
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hbase coprocessor 二级索引相关的知识,希望对你有一定的参考价值。
Coprocessor方式二级索引
1.
Coprocessor提供了一种机制可以让开发者直接在RegionServer上运行自定义代码来管理数据。
通常我们使用get或者scan来从Hbase中获取数据,使用Filter过滤掉不需要的部分,最后在获得的数据上执行业务逻辑。但是当数据量非常大的时候,这样的方式就会在网络层面上遇到瓶颈。客户端也需要强大的计算能力和足够大的内存来处理这么多的数据,客户端的压力就会大大增加。但是如果使用Coprocessor,就可以将业务代码封装,并在RegionServer上运行,也就是数据在哪里,我们就在哪里跑代码,这样就节省了很大的数据传输的网络开销。
2. Coprocessor有两种:Observer和Endpoint
EndPoint主要是做一些计算用的,比如计算一些平均值或者求和等等。而Observer的作用类似于传统关系型数据库的触发器,在一些特定的操作之前或者之后触发。
Observer Coprocessor的使用场景如下:
2.1. 安全性:在执行Get或Put操作前,通过preGet或prePut方法检查是否允许该操作;
2.2. 引用完整性约束:HBase并不直接支持关系型数据库中的引用完整性约束概念,即通常所说的外键。但是我们可以使用Coprocessor增强这种约束。比如根据业务需要,我们每次写入user表的同时也要向user_daily_attendance表中插入一条相应的记录,此时我们可以实现一个Coprocessor,在prePut方法中添加相应的代码实现这种业务需求。
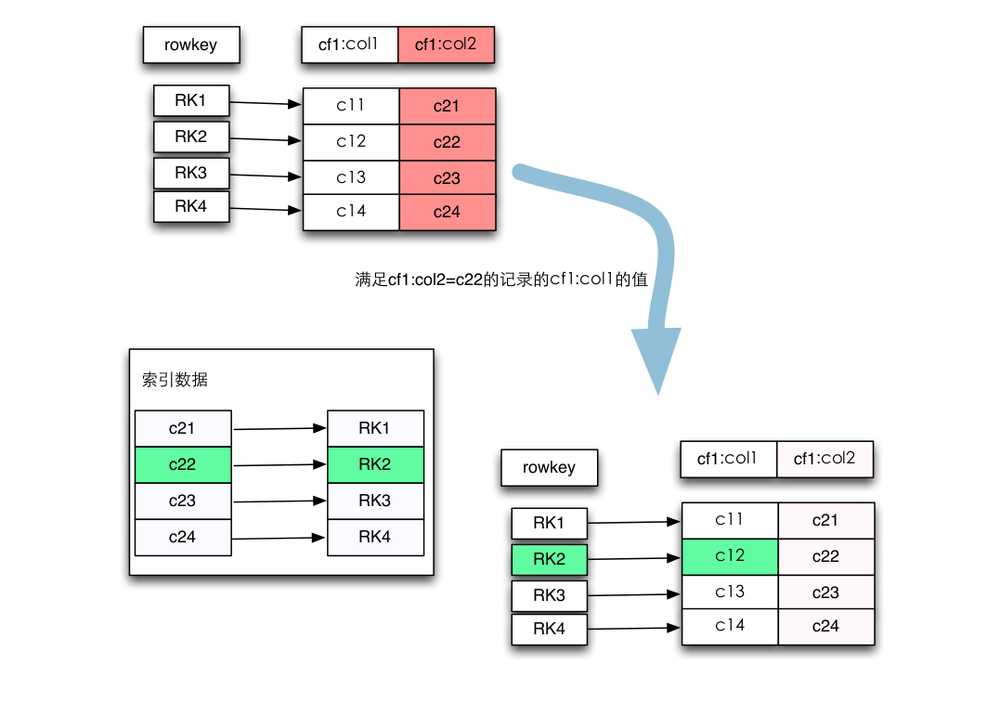
2.3. 二级索引:可以使用Coprocessor来维持一个二级索引。正是我们需要的
Vi hs2.java
import java.io.IOException; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.client.HBaseAdmin; import org.apache.hadoop.hbase.client.HTable; import org.apache.hadoop.hbase.HColumnDescriptor; import org.apache.hadoop.hbase.HTableDescriptor; import org.apache.hadoop.hbase.util.Bytes; import org.apache.hadoop.hbase.client.Put; public class hs2{ public static void main(String[] args){ HBaseConfiguration config = new HBaseConfiguration(); config.set("hbase.zookeeper.quorum", "h201,h202,h203"); String tablename = new String("user1"); try{ HBaseAdmin admin = new HBaseAdmin(config); if(admin.tableExists(tablename)){ admin.disableTable(tablename); admin.deleteTable(tablename); } HTableDescriptor tableDesc = new HTableDescriptor(tablename); tableDesc.addFamily(new HColumnDescriptor("cf1")); admin.createTable(tableDesc); admin.close(); HTable table = new HTable(config, Bytes.toBytes("user1")); Put put1 = new Put(Bytes.toBytes("101")); put1.add(Bytes.toBytes("cf1"),Bytes.toBytes("name"),Bytes.toBytes("zs1")); Put put2 = new Put(Bytes.toBytes("102")); put2.add(Bytes.toBytes("cf1"),Bytes.toBytes("name"),Bytes.toBytes("ls1")); table.put(put1); table.put(put2); table.close(); } catch(IOException e) { e.printStackTrace(); } } }
Vi hs3.java
import java.io.IOException; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.client.HBaseAdmin; import org.apache.hadoop.hbase.client.HTable; import org.apache.hadoop.hbase.HColumnDescriptor; import org.apache.hadoop.hbase.HTableDescriptor; import org.apache.hadoop.hbase.util.Bytes; import org.apache.hadoop.hbase.client.Put; public class hs3{ public static void main(String[] args){ HBaseConfiguration config = new HBaseConfiguration(); config.set("hbase.zookeeper.quorum", "h201,h202,h203"); String tablename = new String("user2"); try{ HBaseAdmin admin = new HBaseAdmin(config); if(admin.tableExists(tablename)){ admin.disableTable(tablename); admin.deleteTable(tablename); } HTableDescriptor tableDesc = new HTableDescriptor(tablename); tableDesc.addFamily(new HColumnDescriptor("cf1")); admin.createTable(tableDesc); admin.close(); HTable table = new HTable(config, Bytes.toBytes("user2")); Put put1 = new Put(Bytes.toBytes("zs1")); put1.add(Bytes.toBytes("cf1"),Bytes.toBytes("id"),Bytes.toBytes("101")); Put put2 = new Put(Bytes.toBytes("ls1")); put2.add(Bytes.toBytes("cf1"),Bytes.toBytes("id"),Bytes.toBytes("102")); table.put(put1); table.put(put2); table.close(); } catch(IOException e) { e.printStackTrace(); } } }
创建两张表
User1
Rowkeycf1:name
101 zs1
102 ls1
User2
Rowkeycf1:id
zs1 101
ls1 102
动态加载
RegionObserver类提供的所有回调函数都需要一个特殊的上下文作为共同的参数: ObserverContext类,它不仅提供了访问当前系统环境的入口,同时也添加了一些关键功能用以通知协处理器框架在回调函数完成时需要做什么。
ObserverContext类提供的方法
|
E getEnvironment() |
返回当前协处理器环境的应用 |
|
void bypass() |
当用户代码调用此方法时,框架将使用用户提供的值,而不使用框架通常使用的值 |
|
void complete() |
通知框架后续的处理可以被跳过,剩下没有被执行的协处理器也会被跳过。这意味着当前协处理器的响应是最后的一个协处理器 |
|
boolean shouldBypass() |
框架内部用来检查标志位 |
|
boolean shouldComplete() |
框架内部用来检查标志位 |
|
void prepare(E env) |
使用特定的环境准备上下文。这个方法只供内部使用。它被静态方法createAndPrepare使用 |
|
static <T extends CoprocessorEnvironment> ObserverContext<T> createAndPrepare( |
初始化上下文的静态方法。当提供的context参数是null时,它会创建一个新实例 |
Vi Ic.java
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.Cell; import org.apache.hadoop.hbase.KeyValue; import org.apache.hadoop.hbase.client.Durability; import org.apache.hadoop.hbase.client.HTable; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.coprocessor.BaseRegionObserver; import org.apache.hadoop.hbase.coprocessor.ObserverContext; import org.apache.hadoop.hbase.coprocessor.RegionCoprocessorEnvironment; import org.apache.hadoop.hbase.regionserver.wal.WALEdit; import org.apache.hadoop.hbase.HBaseConfiguration; import java.io.IOException; import java.util.Iterator; import java.util.List; public class Ic extends BaseRegionObserver { @Override public void prePut(ObserverContext<RegionCoprocessorEnvironment> e, Put put, WALEdit edit, Durability durability) throws IOException { HBaseConfiguration config = new HBaseConfiguration(); config.set("hbase.zookeeper.quorum", "h201,h202,h203"); HTable table = new HTable(config, "user2"); List<Cell> kv = put.get("cf1".getBytes(), "name".getBytes()); Iterator<Cell> kvItor = kv.iterator(); while (kvItor.hasNext()) { Cell tmp = kvItor.next(); final byte[] value = tmp.getValue(); Put indexPut = new Put(value); indexPut.add("cf1".getBytes(), "id".getBytes(), tmp.getRow()); table.put(indexPut); } table.close(); } }
[[email protected] hhh]$ /usr/jdk1.7.0_25/bin/javac Ic.java
[[email protected] hhh]$ /usr/jdk1.7.0_25/bin/jar cvf Icc.jar Ic*.class
[[email protected] hhh]$ hadoop fs -put Icc.jar /
加载:
[[email protected] hbase-1.0.0-cdh5.5.2]$ bin/hbase shell
1.hbase(main):001:0> disable ‘user1‘
2.hbase(main):002:0> alter ‘user1‘ ,METHOD=>‘table_att‘,‘coprocessor‘=>‘hdfs://h201:9000/Icc.jar|Ic|1001‘
***1001为优先级****
3.hbase(main):003:0> enable ‘user1‘
验证:
User1 插入一条数据
hbase(main):005:0> put ‘user1‘,‘105‘,‘cf1:name‘,‘ww1‘
发现user2的表中也多出了一条 ww1 105
以上是关于hbase coprocessor 二级索引的主要内容,如果未能解决你的问题,请参考以下文章