正则表达式基础
Posted sheng-yang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正则表达式基础相关的知识,希望对你有一定的参考价值。
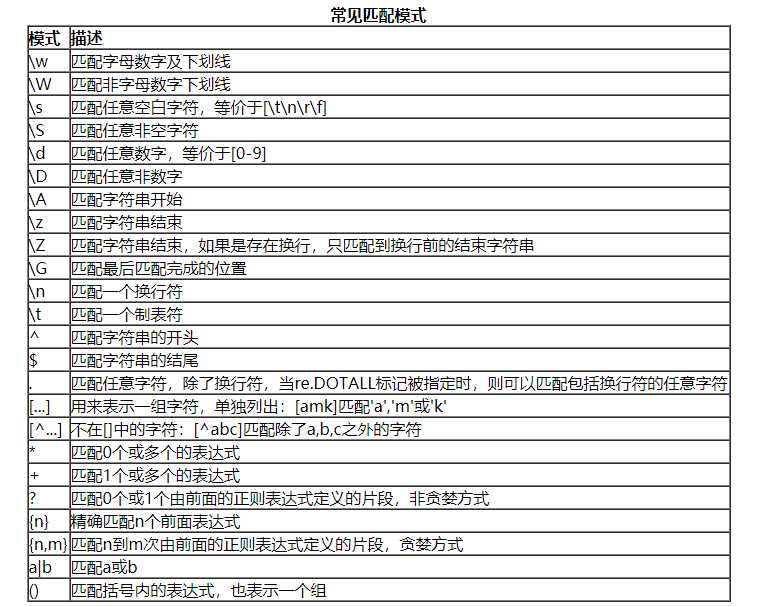
re.match
尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none
re.match(pattern,string,flags=0)
第一个参数是正则表达式
第二个参数表示要匹配的字符串
第三个参数是标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等
1、最常规的匹配
import re content = ‘Hello 123 4567 World_Have a good mood every day‘ #print(len(content)) result = re.match(‘^Hellosdddsd{4}sw{10}.*day$‘,content) print(result) print(result.group()) print(result.span())
输出结果为:
<_sre.SRE_Match object; span=(0, 47), match=‘Hello 123 4567 World_Have a good mood every day‘>
Hello 123 4567 World_Have a good mood every day
(0, 47)
PS:
group() == group(0) == 所有匹配的字符,与括号无关,这个是API规定,而m.groups() 返回所有括号匹配的字符
span():表示匹配结果的范围
2、泛匹配
import re content = ‘Hello 123 4567 World_Have a good mood every day‘ result = re.match(‘^Hello.*day$‘,content) print(result) print(result.group()) print(result.span())
输出结果为:(同上)
<_sre.SRE_Match object; span=(0, 47), match=‘Hello 123 4567 World_Have a good mood every day‘>
Hello 123 4567 World_Have a good mood every day
(0, 47)
3、匹配目标
import re content = ‘Hello 1234567 World_Have a good mood every day‘ result = re.match(‘^Hellos(d+)sWorld.*day$‘,content) print(result) print(result.group(1)) print(result.span())
输出结果:
<_sre.SRE_Match object; span=(0, 46), match=‘Hello 1234567 World_Have a good mood every day‘>
1234567
(0, 46)
PS:
group(1):输出第一个括号匹配的所有字符,2、3以此类推
4、贪婪匹配
import re content = ‘Hello 1234567 World_Have a good mood every day‘ result = re.match(‘^He.*(d+).*day$‘,content) print(result) print(result.group(1))
输出结果:
<_sre.SRE_Match object; span=(0, 46), match=‘Hello 1234567 World_Have a good mood every day‘>
7
PS:123456被 .* 匹配掉了,.*会匹配尽可能多的字符,因为后面有(d+)它至少要匹配一个数字,所以最后输出结果是一个7
5、非贪婪匹配
import re content = ‘Hello 1234567 World_Have a good mood every day‘ result = re.match(‘^He.*?(d+).*day$‘,content) print(result) print(result.group(1))
输出结果:
<_sre.SRE_Match object; span=(0, 46), match=‘Hello 1234567 World_Have a good mood every day‘>
1234567
PS:加上?指定模式是非贪婪匹配,会匹配尽可能少的字符,.*?(d+)表示如果发现 .*?后面匹配的是数字,它会把前面无关内容匹配掉
6、匹配模式
import re content = ‘‘‘Hello 1234567 World_Have a good mood every day‘‘‘ result = re.match(‘He.*?(d+).*?day$‘,content,re.S) print(result) print(result.group(1))
输出结果:
<_sre.SRE_Match object; span=(0, 47), match=‘Hello 1234567 World_Have a
good mood every day‘>
1234567
PS:a后面有换行符,.(点)不能匹配换行符,加上re.S 就可以正常输出
7、转义
import re content = ‘price is $5.00‘ result= re.match(‘price is $5.00‘,content) print(result) result= re.match(‘price is $5.00‘,content) print(result)
输出结果:
None
<_sre.SRE_Match object; span=(0, 14), match=‘price is $5.00‘>
PS:尽量使用泛匹配,使用括号得到匹配目标,尽量使用非贪婪模式,有换行符就用 re.S
re.search
扫描整个字符串并返回第一个成功的匹配
import re content = ‘Extra strings Hello 1234567 World_Have a good mood every day Extra strings‘ result = re.match(‘Hello.*?(d+).*?day‘,content) print(result) result = re.search(‘Hello.*?(d+).*?day‘,content) print(result) print(result.group(1))
输出结果:
None
<_sre.SRE_Match object; span=(14, 60), match=‘Hello 1234567 World_Have a good mood every day‘>
1234567
PS:为匹配方便,能用search就不用match
re.findall
搜索字符串,以列表形式返回全部能匹配的子串
import re html = ‘‘‘<div class="over"> <ul class="product_ul "> <li class="line1 "> <a class="img" href="http://product.dangdang.com/26515962.html" title="我有预感明天也会喜欢你"> <img alt="我有预感明天也会喜欢你" src="http://img3m2.ddimg.cn/0/23/26515962-1_l_4.jpg"/> </a> <p class="name" > <a href="http://product.dangdang.com/26515962.html" title="我有预感明天也会喜欢你"> 我有预感明天也会喜欢你 </a> </p> <p class="author">张一然、么么晗,白马时光 出品</p> <p class="price">¥27.40</p> </li> <li class="line2 "> <img alt="都挺好(套装共两册)" src="http://img3m5.ddimg.cn/70/28/26445445-1_l_4.jpg"/> <p class="name">都挺好(套装共两册)</p> <p class="author">阿耐</p> <p class="price">¥68.70</p> </li> <li class="line3 "> <a class="img" href="http://product.dangdang.com/26514792.html" title="林徽因传:人生从来都靠自己成全"> <img alt="林徽因传:人生从来都靠自己成全" src="http://img3m2.ddimg.cn/18/0/26514792-1_l_10.jpg"/> </a> <p class="name"> <a href="http://product.dangdang.com/26514792.html" title="林徽因传:人生从来都靠自己成全"> 林徽因传:人生从来都靠自己成全 </a> </p> <p class="author">程 碧</p> <p class="price">¥51.60</p> </li> </ul> </div> ‘‘‘ results = re.findall(‘<li.*?href="(.*?)".*?title="(.*?)">.*?author.>(.*?)...>‘,html,re.S) print(results) print(type(results)) for result in results: #print(result) print(result[0],result[1],result[2])
输出结果:
[(‘http://product.dangdang.com/26515962.html‘, ‘我有预感明天也会喜欢你‘, ‘张一然、么么晗,白马时光 出品‘), (‘http://product.dangdang.com/26514792.html‘, ‘林徽因传:人生从来都靠自己成全‘, ‘程 碧‘)]
<class ‘list‘>
http://product.dangdang.com/26515962.html 我有预感明天也会喜欢你 张一然、么么晗,白马时光 出品
http://product.dangdang.com/26514792.html 林徽因传:人生从来都靠自己成全 程 碧
PS:结果中没有 都挺好 的相关内容
用以下代码可以解决:
results = re.findall(‘<li.*?alt="(.*?)"s.*?(<a.*?>)?.*?author.>(.*?)...>‘,html,re.S) for result in results: #print(result) print(result[0])
输出结果:
我有预感明天也会喜欢你
都挺好(套装共两册)
林徽因传:人生从来都靠自己成全
PS: (<a.*?>)? ()内代表一个整体,这个地方的意思是匹配0个或者1个a标签
多说一句:例如 <li.*?>s*? 匹配0个或多个空白符(有或没有都可匹配)
re.sub
替换字符串中每一个匹配的子串后返回替换后的字符串
import re content = ‘Extra strings Hello 1234567 World_Have a good mood every day Extra strings‘ content = re.sub(‘d+‘,‘‘,content) print(content) content = ‘Extra strings Hello 1234567 World_Have a good mood every day Extra strings‘ content = re.sub(‘d+‘,‘Replacement‘,content) print(content) content = ‘Extra strings Hello 1234567 World_Have a good mood every day Extra strings‘ content = re.sub(‘(d+)‘,r‘1 8910‘,content) print(content)
输出结果:
Extra strings Hello World_Have a good mood every day Extra strings
Extra strings Hello Replacement World_Have a good mood every day Extra strings
Extra strings Hello 1234567 8910 World_Have a good mood every day Extra strings
PS:替换的目标是原字符串本身或者包含原字符串,把 d+ 加上括号,括号里面的内容可以用group(1)拿到,用 1 拿到匹配内容,用 r 表示原生字符串,也就是说 1 就是把第一个括号里的内容取到,最后做一下替换
re.compile
将正则字符串编译成正则表达式对象,以便于复用该匹配模式
import re content = ‘‘‘Hello 1234567 World_Have a good mood every day‘‘‘ pattern = re.compile(‘Hello.*day‘,re.S) result = re.match(pattern,content) print(result)
输出结果:
<_sre.SRE_Match object; span=(0, 47), match=‘Hello 1234567 World_Have a good mood every day‘>
最后分享一个 在线正则表达式测试网站 http://tool.oschina.net/regex/#
以上是关于正则表达式基础的主要内容,如果未能解决你的问题,请参考以下文章