扫盲记-第三篇--图像分割
Posted jeshy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了扫盲记-第三篇--图像分割相关的知识,希望对你有一定的参考价值。
学习内容来源于网络
图像分割
图像分割是什么?如果下学术定义,就是把图像分割成想要的语义上相同的若干子区域,看上面的自动驾驶的分割任务,路是路,车是车,树是树。这些子区域,组成图像的完备子集,相互之间不重叠。图像分割可以被看作是一个逐像素的图像分类问题。

传统办法:
- 边缘与阈值法
简单的边缘检测曾被用于图像分割,但需要做复杂后处理。阈值法的基本思想是基于图像的灰度特征来计算一个或多个灰度阈值,并将图像中每个像素的灰度值与阈值相比较。最广泛使用也最具有代表性质就是OTSU方法,它是用于灰度图像分割的方法,核心思想是使类间方差最大化。OTSU方法非常简单,要求被分割的物体颜色纹理比较紧凑,类内方差小,只适合一些文本图像的处理,比如车牌、指纹等。
- 区域增长,分裂
对于类内方差较大的目标OTSU方法分割结果不理想,OTSU方法没有利用好像素的空间信息,导致分割结果极其容易受噪声干扰,经常出现断裂的边缘,需要后处理。区域生长法出它通过一些种子点,再加上相似性准则来不断扩充区域直至达到类别的边界,使得分割的结果具有很强的连续性。区域分裂则是反过程。区域生长法的代表是分水岭算法。分水岭算法对于弱边缘有不错的响应,因此常被用于材料图像的分割,以及产生超像素用于提高其他方法的分割效率。超像素归为图像分割的方法,SLIC,Meanshift等都是非常经典的方法配合其他方法一起使用,往往产生惊人的效果。

- 图割
以graphcut为代表的图割方法,是传统图像分割里面鲁棒性最好的方法,graphcut是一种概率无向图模型(Probabilistic undirected graphical model),又称之为Markov random field-MRF马尔可夫随机场。
Graphcut的基本思路,首先建立一张图,其中以图像像素或者超像素作为图像顶点,然后优化的目标是要找到一个切割,使得各个子图不相连从而实现分割,前提是移除边和权重最小。
随后图割方法从MRF发展到CRF,即条件随机场。CRF通常包含两个优化目标,一是区域的相似度,被称为区域能量项,即piecewise能量;另一个是被切断边的相似度,被称为边缘能量项,即pairwise能量。CRF追求区域能量项的最大化以及边缘能量的最小化,即区域内部越相似越好,区域间相似度越低越好。图割方法很通用,对于纹理比较复杂的图像分割效果很不错。图割方法缺点,时间复杂度和空间复杂度较高,因此通常使用超像素进行加速计算。
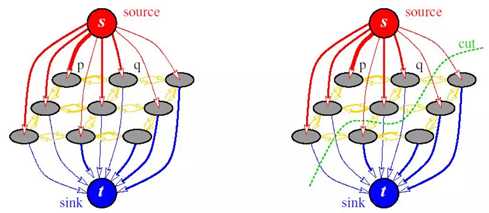
Grabcut是graphcut的迭代版本。Grabcut它的基本思路:使用混合高斯模型(Gaussian Mixture Model,GMM)替代了graphcut基于灰度的模型,初始的混合高斯模型的构建,通过用户交互来指定,只需要指定确定性的背景像素区域即可,通常画一个框来指定。CRF与MRF的区别可以参考【Discriminative fields for modeling spatial dependencies in natural images】,图割方法很实用,是图像分割领域中的研究者必须掌握的技能。

- 轮廓模型
轮廓模型的基本思想是使用连续曲线来表达目标轮廓,并定义一个能量泛函,其自变量为曲线,将分割过程转变为求解能量泛函的最小值的过程。数值实现可通过求解函数对应的欧拉(Euler-Lagrange)方程来实现。轮廓模型包括以snake模型为代表的参数活动轮廓模型和以水平集方法为代表的几何活动轮廓模型。当能量达到最小时的曲线位置就处于正确的目标轮廓。
基于轮廓模型分割方法具有以下几个显著的特点:
(1) 由于能量泛函是在连续状态下实现,所以最终得到的图像轮廓可以达到较高的精度;
(2) 通过约束目标轮廓为光滑,同时融入其它关于目标形状的先验信息,算法可以具有较强的鲁棒性;
(3) 使用光滑的闭合曲线表示物体的轮廓,可获取完整的轮廓,从而避免传统图像分割方法中的预/后处理过程。
缺点就是比较敏感,容易陷入局部极值。
深度学习办法:
第一篇采用深度学习方法来做图像分割的是FCN【Fully Convolutional Networks for Semantic Segmentation】,分类任务到了最后,图像被表征成了一个一维的向量,而分割任务则需要恢复一张与原图大小相等的图,所以全连接自然是不行的。
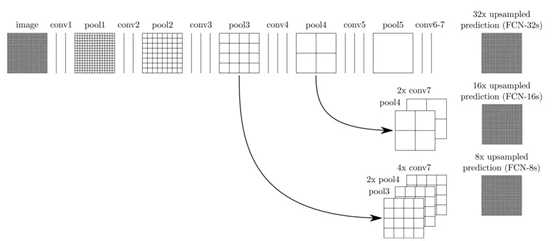
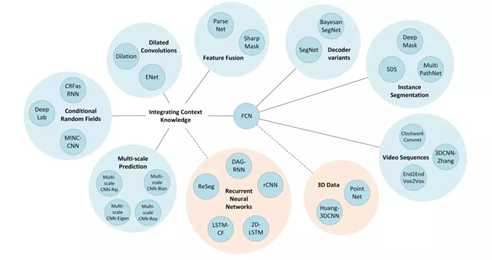
在从最小分辨率的feature map上采样的过程中,融合了卷积过程中同一分辨率大小的特征图,这种将网络浅层和深层信息融合的思想是分割网络的必备。一种对称和优美的网络结构【Bayesian segnet: Model uncertainty in deep convolutional encoder-decoder architectures for scene understanding】:
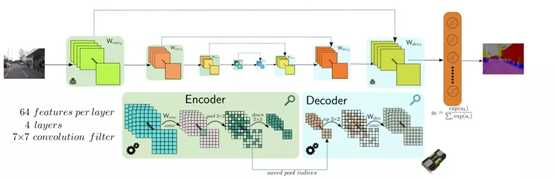
基于FCN的改进的许多方法采用了不同的上采样办法,带孔卷积等增加感受野的方法、图片与特征的多尺度信息融合、增加CRF等后处理的方法等。但万变不离其宗,最终分割结果的好坏往往取决于网络的表征能力、问题的简化、好的标注数据等。
分割不仅仅是分类问题
前文所述的,都是将分割当成一个分类问题来对待的,将每个像素要被归为明确的类别。然而分割的终极目标不只是归类,比如为了做背景替换的抠图(image matting)。对于分类问题,产生的分割背景和前景不能够完美融合,因此需要一种带透明度通道的分割或者先分割再利用泊松融合等技术进行边缘融合的解决办法,这就是一个image matting问题。
image matting问题可以用一个简单的数学表达式表达:
I = aF + (1-a)B
其中F是前景,B是背景,a是透明度,一张图可以看作在透明度图像的控制下,前景和背景的线性融合。解这个问题有点病态,对于三通道的RGB图像,只有3个方程,却需要解出6个变量。所以像closed matting等方法都要做局部区域颜色不变的约束才能求出解析解。
随着技术的进步image matting问题从传统方法发展到了深度学习,对主流方法进行了比较请参见:http://www.alphamatting.com/index.html。
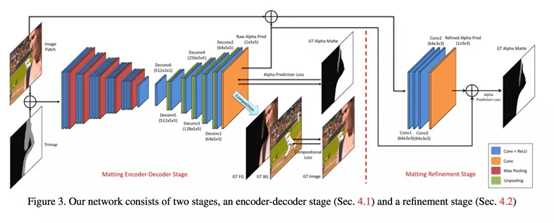
一种end to end的方案deep image matting
谱分割(spectral segmentation),Laplacian矩阵,soft transitions与layers,SLIC等。
谱分割与laplacian矩阵是graphcut的归一化版本Normalized Cut的核心,而soft transitions与layers是photoshop最核心的思想,SLIC则是用于减少计算量的超像素方法。将这些方法和加上深度学习相互融合使用,就会图像分割效果极好的图像分割效果。【Semantic Soft Segmentation】
学习内容来源 言有三(微信号:Longlongtogo) https://mp.weixin.qq.com/s?__biz=MzA3NDIyMjM1NA==&mid=2649029723&idx=1&sn=555a2d45fa210a1c5c5c703de54899a4&chksm=87134226b064cb30f070ea5a2368f1c5bb6679d0f13e7e84b3f6374be33c549ce81a665d6e25&token=872571663&lang=zh_CN#rd
以上是关于扫盲记-第三篇--图像分割的主要内容,如果未能解决你的问题,请参考以下文章