数据分析之numpy
Posted qq631243523
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据分析之numpy相关的知识,希望对你有一定的参考价值。
一,介绍
NumPy是Python语言的一个扩展程序库。支持高端大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
ndarray 数据结构:
NumPy的核心功能是"ndarray"(即n-dimensional array,多维数组)数据结构。这是一个表示多维度、同质并且固定大小的数组对象。而由一个与此数组相关系的数据类型对象来描述其数组元素的数据格式(例如其字符组顺序、在存储器中占用的字符组数量、整数或者浮点数等等)。
二,使用
1,创建ndarray
import numpy as np
使用np.array()
a1 = np.array([1,2,3,4,5]) a1 # array([1, 2, 3, 4, 5]) a2 = np.array([1,2.123]) a2 # array([ 1. , 2.123]) 创建np的时候,可以赋值不同类型的数组元素。创建成功数组元素一定会被统一 str 》 float 》int
二维数组创建
a3 = np.array([[3,6,9],[3,6,9],[3,6,5]])
a3
array([[3, 6, 9],
[3, 6, 9],
[3, 6, 5]])
注意: numpy默认ndarray的所有元素的类型是相同的 如果传进来的列表中包含不同的类型,则统一为同一类型,优先级:str>float>int
属性:
shape的使用:shape返回的是ndarray的数组形状。返回值的数据个数表示的就是数组的维度
a3.shape # (3, 3)
import numpy as np
arr1 = np.array([1,2,3,4,5])
arr1 # array([1, 2, 3, 4, 5])
arr2 = np.array([1, "sdf", 2])
arr2 # array([‘1‘, ‘sdf‘, ‘2‘], dtype=‘<U11‘)
arr4 = np.array([1, 2, 3], dtype=‘float‘)
arr4 # array([1., 2., 3.])
arr5 = arr4.astype(‘int64‘)
arr5 # array([1, 2, 3], dtype=int64)
arr6 = np.linspace(1, 10, 20) # 1到10,生成20个数,之间为等差数列
arr6
# array([ 1. , 1.47368421, 1.94736842, 2.42105263, 2.89473684,
3.36842105, 3.84210526, 4.31578947, 4.78947368, 5.26315789,
5.73684211, 6.21052632, 6.68421053, 7.15789474, 7.63157895,
8.10526316, 8.57894737, 9.05263158, 9.52631579, 10. ])
arr7 = np.arange(1, 20)
arr7
# array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17,
18, 19])
- 二维数组的创建
np.array([[1,2], [2, 5]])
array([[1, 2],
[2, 5]])
arr8 = np.array([[1,2,3], [4,5,6],[7,8,9]]).astype(‘float‘)
arr8
# array([[1., 2., 3.],
[4., 5., 6.],
[7., 8., 9.]])
arr8.shape
# (3, 3)
np.zeros((5,5), dtype=‘int‘)
# array([[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0]])
np.ones((3, 4), dtype=‘float‘)
#
array([[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]])
a1 = np.full((3, 4), 1.1)
a1
# array([[1.1, 1.1, 1.1, 1.1],
[1.1, 1.1, 1.1, 1.1],
[1.1, 1.1, 1.1, 1.1]])
a2 = np.random.randint(1, 20, size=(3,4))
a2
# array([[19, 17, 3, 9],
[19, 18, 16, 4],
[ 9, 16, 5, 17]])
np.random.seed(10) #该行可以将随机数进行固定
np.random.random((5,6))
# array([[0.77132064, 0.02075195, 0.63364823, 0.74880388, 0.49850701,
0.22479665],
[0.19806286, 0.76053071, 0.16911084, 0.08833981, 0.68535982,
0.95339335],
[0.00394827, 0.51219226, 0.81262096, 0.61252607, 0.72175532,
0.29187607],
[0.91777412, 0.71457578, 0.54254437, 0.14217005, 0.37334076,
0.67413362],
[0.44183317, 0.43401399, 0.61776698, 0.51313824, 0.65039718,
0.60103895]])
np.empty((4, 4))
array([[6.23042070e-307, 4.67296746e-307, 1.69121096e-306,
1.06810879e-306],
[8.34441742e-308, 1.78022342e-306, 6.23058028e-307,
9.79107872e-307],
[6.89807188e-307, 7.56594375e-307, 6.23060065e-307,
1.78021527e-306],
[8.34454050e-308, 1.11261027e-306, 1.15706896e-306,
1.33512173e-306]])
np.eye(5)
#
array([[1., 0., 0., 0., 0.],
[0., 1., 0., 0., 0.],
[0., 0., 1., 0., 0.],
[0., 0., 0., 1., 0.],
[0., 0., 0., 0., 1.]])
arr9 = np.arange(12).reshape(3, 4)
arr9
# array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
索引和切片
arr9 = np.arange(12).reshape(3, 4)
arr9
# array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
arr9[1][1]
# 5
arr9[1,1]
# 5
arr9[1:, :2]
# array([[4, 5],
[8, 9]])
arr9[:,::-2]
# array([[ 3, 1],
[ 7, 5],
[11, 9]])
import random
li = [random.randint(1, 10) for _ in range(10)]
li
# [2, 1, 6, 6, 5, 4, 2, 6, 5, 1]
# 选出li中大于5的数
arr10 = np.array(li)
arr10
# array([2, 1, 6, 6, 5, 4, 2, 6, 5, 1])
arr10>5
# array([False, False, True, True, False, False, False, True, False,
False])
arr10[arr10 >4] # 使用布尔索引
# array([6, 6, 5, 6, 5])
arr10[(arr10 > 4) & (arr10%2 ==0)] # 大于4 并且是偶数
# array([6, 6, 6])
arr10[(arr10 > 4) | (arr10%2==0)] # 大于4 或者 是偶数
# array([2, 6, 6, 5, 4, 2, 6, 5])
arr9
# array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
arr9[:, [0,1]] # 花式索引
# array([[0, 1],
[4, 5],
[8, 9]])
arr9[arr9[:,0] % 2 == 0, 2:]
# 注意,切片:前面为行,使用布尔索引时,有几行就对应个bool值
# array([[ 2, 3],
[ 6, 7],
[10, 11]])
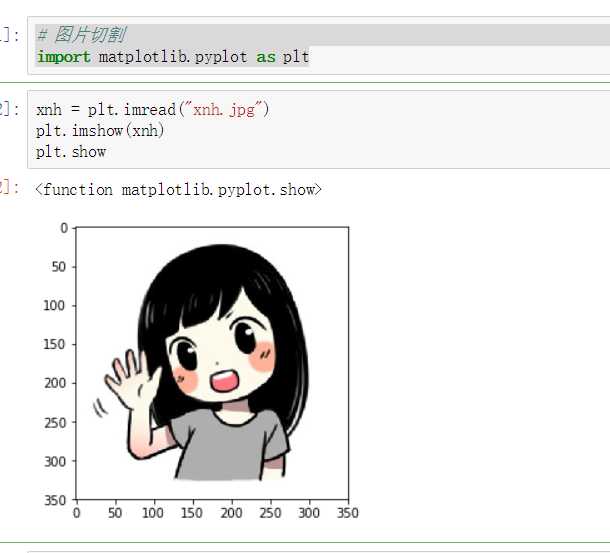
利用索引,切片操作图片
# 图片切割
import matplotlib.pyplot as plt
xnh = plt.imread("xnh.jpg")
plt.imshow(xnh)
plt.show
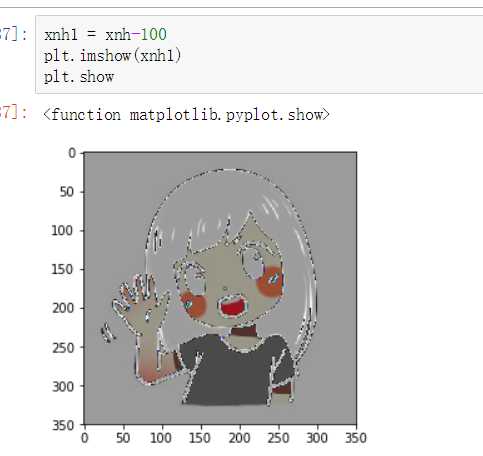
xnh.shape # 前两个表示像素,后面一个表示色度 # (350, 350, 3) xnh1 = xnh-100 plt.imshow(xnh1) plt.show
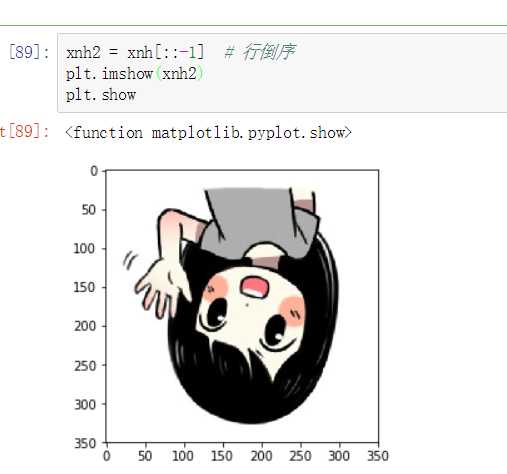
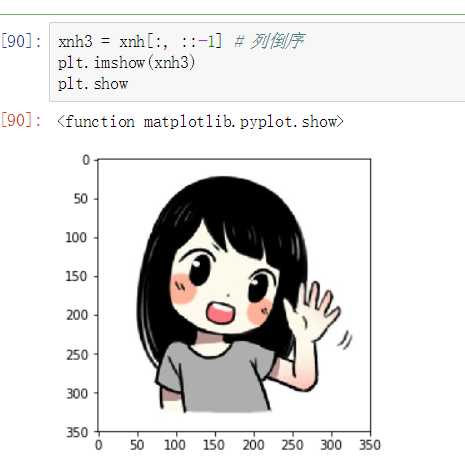
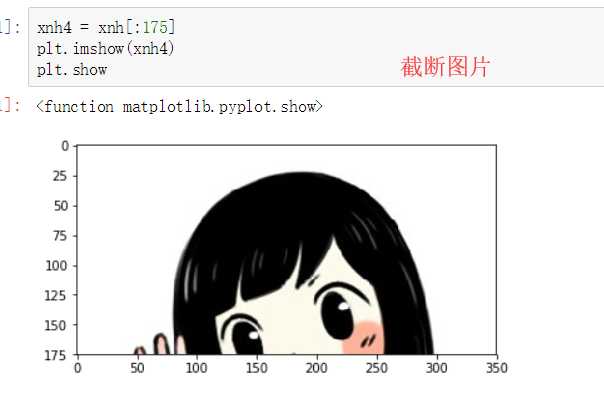
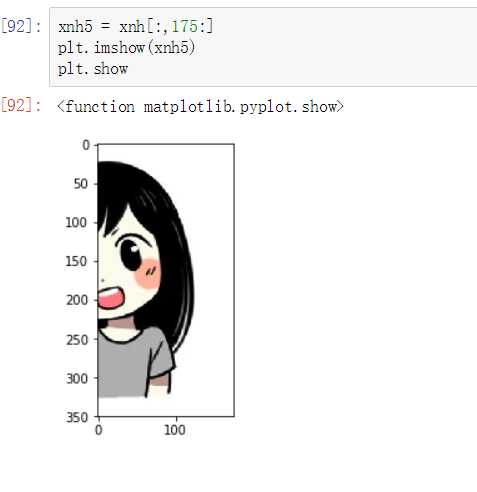
级联
np.concatenate()
# 1.一维,二维,多维数组的级联,实际操作中级联多为二维数组
a1 = np.random.randint(0,100,size=(3,))
a2 = np.random.randint(0,100,size=(3,3))
a1
# array([23, 94, 11])
a2
#array([[28, 74, 88],
[ 9, 15, 18],
[80, 71, 88]])
np.concatenate((a1,a1),axis=0)
# array([23, 94, 11, 23, 94, 11])
np.concatenate((a2,a2),axis=1)
#array([[28, 74, 88, 28, 74, 88],
[ 9, 15, 18, 9, 15, 18],
[80, 71, 88, 80, 71, 88]])
利用级联合并图片
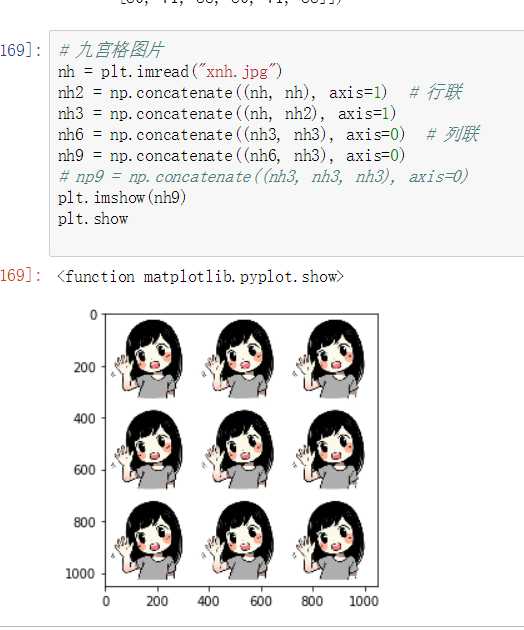
#级联需要注意的点: 级联的参数是列表:一定要加中括号或小括号 维度必须相同 形状相符:在维度保持一致的前提下,如果进行横向(axis=1)级联,必须保证进行级联的数组行数保持一致。如果进行纵向(axis=0)级联,必须保证进行级联的数组列数保持一致。 可通过axis参数改变级联的方向
分割
aa = np.random.randint(1, 50,size=(7,7))
aa
# array([[41, 47, 33, 31, 23, 6, 46],
[19, 49, 45, 2, 44, 14, 19],
[28, 20, 38, 8, 25, 40, 16],
[ 7, 45, 10, 1, 45, 5, 15],
[46, 5, 7, 43, 10, 45, 49],
[37, 27, 39, 21, 10, 41, 17],
[12, 40, 18, 40, 34, 12, 15]])
np.split(aa, [2,4,6], axis=1)
# [array([[41, 47],
[19, 49],
[28, 20],
[ 7, 45],
[46, 5],
[37, 27],
[12, 40]]), array([[33, 31],
[45, 2],
[38, 8],
[10, 1],
[ 7, 43],
[39, 21],
[18, 40]]), array([[23, 6],
[44, 14],
[25, 40],
[45, 5],
[10, 45],
[10, 41],
[34, 12]]), array([[46],
[19],
[16],
[15],
[49],
[17],
[15]])]
聚合运算
Function Name NaN-safe Version Description np.sum np.nansum Compute sum of elements np.prod np.nanprod Compute product of elements np.mean np.nanmean Compute mean of elements np.std np.nanstd Compute standard deviation np.var np.nanvar Compute variance np.min np.nanmin Find minimum value np.max np.nanmax Find maximum value np.argmin np.nanargmin Find index of minimum value np.argmax np.nanargmax Find index of maximum value np.median np.nanmedian Compute median of elements np.percentile np.nanpercentile Compute rank-based statistics of elements np.any N/A Evaluate whether any elements are true np.all N/A Evaluate whether all elements are true np.power 幂运算
np.max(aa, axis=1) # array([47, 49, 40, 45, 49, 41, 40]) np.mean(aa) # 26.3265306122449 np.any(aa) # True 有一个True就是True
广播机制
m = np.ones((2, 3))
a = np.arange(3)
m
# array([[1., 1., 1.],
[1., 1., 1.]])
a
# array([0, 1, 2])
m + a
# array([[1., 2., 3.],
[1., 2., 3.]])
a = np.arange(3).reshape((3, 1))
b = np.arange(1,4)
a + b # 缺失元素用已有值填充
array([[1, 2, 3],
[2, 3, 4],
[3, 4, 5]])
【重要】ndarray广播机制的三条规则:缺失维度的数组将维度补充为进行运算的数组的维度。缺失的数组元素使用已有元素进行补充。 规则一:为缺失的维度补1(进行运算的两个数组之间的维度只能相差一个维度) 规则二:缺失元素用已有值填充 规则三:缺失维度的数组只能有一行或者一列
排序

math相关
以上是关于数据分析之numpy的主要内容,如果未能解决你的问题,请参考以下文章