cs20_6-1
Posted ls1314
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了cs20_6-1相关的知识,希望对你有一定的参考价值。
1. ConvNet
1.1 一些小知识点
tf中的tf.nn.conv2d的几个新感悟
tf.nn.conv2d( input, filter, strides, padding, use_cudnn_on_gpu=True, data_format='NHWC', dilations=[1, 1, 1, 1], name=None ) Input: Batch size (N) x Height (H) x Width (W) x Channels (C) Filter: Height x Width x Input Channels x Output Channels (e.g. [5, 5, 3, 64]) Strides: 4 element 1-D tensor, strides in each direction (often [1, 1, 1, 1] or [1, 2, 2, 1]) Padding: 'SAME' or 'VALID' Dilations: The dilation factor. If set to k > 1, there will be k-1 skipped cells between each filter element on that dimension. Data_format: default to NHWC- Strides often [1,x, x, 1]: 因为stride 分别指定:batch, w, h, c 四个方向上的滑动,一般情况下我们肯定不想跳过某些batch和channel,所以1-th, 4-th一般是1. w & h 方向就根据情况来(但是现在一般是1 or 2)
- Padding: ‘SAME‘ or ‘VALID‘, SAME指的是通过 pad zero 来确保卷积前后的w x h 不变;VALID就是不确保,按照那个cs231n公式来计算卷积后结果
- Dilations: 用来实现膨胀卷积,一般 1-th, 4-th 都是1,原因同上面的stride(一般不想跳过某些batch, channel),就算膨胀卷积运算,一般也只是跳过 w, h 方向上的一些值
更多类型的conv
conv2d/depthwise_conv2d/separable_conv2d
一个卷积核滤波的例子:学习使用 tf.image 和 传统DIP的滤波操作
本实验主要用到是:tf.nn.xxx,定位是:中层API (middle-level)
1.2 CNN with MNIST
网络结构图
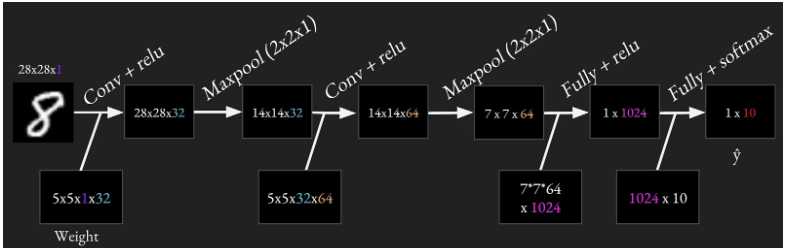
之前的一些知识点
It’s also important to use variable scope so we can have variables with the same names for different layers (scope都有隔离变量作用域的功能): e.g. ‘conv1/weights’, ‘conv2/weights’
公用的功能要写成重用的方式:函数func/类class/乃至更高的抽象
由Conv/Pool进FC之前,应该把feature volume拉直为一个1-d vector(flattern),又因为一般是一个batch输入,所以应该是 2-d tensor(第一维是batch_size, 第二维为拉直的vector)
Conv后紧跟着relu, FC后面也可以接relu, Dropout紧跟在FC后面(除了最后一层加了softmax用于分类的FC除外)
在实践中何时validation ? :往往是刚刚training一个epoch后立刻做下validation,甚至交替时间更短:During training, we alternate between training an epoch and evaluating the accuracy on the test set(有时候也在val set上做validation). We will track both the training loss and test accuracy on Tensorboard.
eval: Count the number of right predictions in a batch
tf.argmax() 的使用:
# tf.argmax(vector, 1):返回的是vector中的最大值的索引号,如果vector是一个向量,那就返回一个值,如果是一个矩阵,那就返回一个向量,这个向量的每一个维度都是相对应矩阵行的最大值元素的索引号。 import tensorflow as tf import numpy as np A = [[1,3,4,5,6]] B = [[1,3,4], [2,4,1]] with tf.Session() as sess: print(sess.run(tf.argmax(A, 1))) # [4] print(sess.run(tf.argmax(B, 1))) # [2 1]
上次以及这次一些奇怪的错误
tensorboard中的logdir,要么完全使用全路径(从根/开始),要么使用(.., . 这样的)相对路径,即使tensorboard命令执行的路径当前有dir_A,也不知道直接写 "dir_A",也必须写 "./dir_A"
关于这个bug,我感觉是tensorboard里面实现问题,反正按照上述要求写就不会错
还有一个是tf(我是tf 1.12)的非常容易犯的错误(由于saver和旧的ckpt的不一致导致的):
Key conv_1/bias not found in checkpoint我第一次训练的时候,写的variable_scope name是conv1,所以对应有conv1/bias,然后training的结果ckpt也保存了。第二次我想要再次训练这个model,所以直接加载上次的ckpt,但是再次训练前我修改了variable_scope name为 conv_1, 所以计算图现在是conv_1/bias,而上一次training的ckpt是 conv1/bias,所以显示旧的ckpt上的tensor在目前的计算图上找不到。
所以,解决方案有2:(1)把所有的tensor都改回去,和旧的ckpt中的graph定义完全一致;(2)清空旧的ckpt,不加载旧的ckpt,从零开始再训练一次
想起之前遇到pycharm的一个bug: A.py引入同目录下B.py但是pycahrm现实找不到B,解决方法:把A,B所在目录右键,然后 "mark directory as Resource Root" (感觉这算是pycharm的一个小bug ?)
关于coding中,个人对于 l (小写L)和 1(数字1), 个人感觉:如果非要写 conv 1 ,就写成 conv_1提醒自己后面的是数字1,不然很容易混淆 数字 1 和 小写L的l
1.3 tf.layer
- 定位:Higher level libraries like Keras, Sonnet
- 一些api初步熟悉:tf.layers.conv2d, tf.layers.max_pooling2d, tf.layers.dense, tf.layers.dropout
- 有点奇怪:几乎一样的逻辑,Layer版的抖动很大,而且loss偏小,难道tf.nn与tf.layer两个版本代码有啥根本区别吗?有时间再对比下,TODO
1.4 参考
以上是关于cs20_6-1的主要内容,如果未能解决你的问题,请参考以下文章