浏览器加载解析渲染网页原理
Posted zheoneandonly
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浏览器加载解析渲染网页原理相关的知识,希望对你有一定的参考价值。
- 浏览器加载网页资源的原理
- JS与CSS阻塞
- 重排与重绘
一、浏览器加载网页资源的原理
1、html支持的组要资源类型
在浏览器内核有一个管理资源的对象CachedResource类,在CachedResource类下有很多子类来分工不同的资源管理,这些资源管理子类分别是:
| 资源 | 资源管理类 |
| HTML | MainResource ===> CachedRawResource |
| javascript | CachedScript |
| CSS | CachedCSStyleSheet |
| 图片 | CachedImage |
| SVG | CachedSVGDocument |
| CSS Shader | CachedShader |
| 视频、音频、字幕 | CachedTextTrack |
| 字体文件 | CachedFont |
| XSL样式表 | CachedXSLStyleSheet |
2、资源缓存
资源的缓存机制是提高资源使用效率的有效方法。基本思想就是建立一个资源缓存池,当web需要请求资源时,会先从资源池中查找是否存在相应的资源,如果有的话就直接取缓存,如果没有就创建一个新的CachedResource子类的对象,并发送请求给服务器(由网络模块完成),请求回来的资源会被添加到资源池,并且将资源(数据信息:比如在资源池中的物理地址)设置到该资源的对象中去,以便下次使用。
下面是一个缩减版的资源请求原理图:
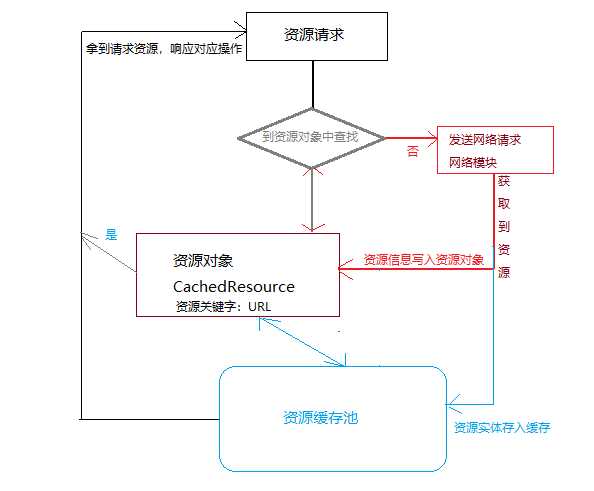
实质上的操作是在资源对象中找到对应资源的物理地址(url),然后返回给渲染引擎,渲染引擎在渲染页面时根据url获取物理内存中的资源数据。由于资源的唯一特性是url,所以当两个资源有不同的url,但是他们的内容完全相同时,也不会被认定是同一个资源。
注:这里所说的缓存是内存,不是磁盘。
3、资源加载器
在WebKit中共有三种类型的资源加载器,分别是:
3.1针对每种资源类型的特定加载器,用来加载某一类资源。例如“image”这个元素,该元素需要图片资源,对应的顶资源加载器是ImageLoader类。
3.2资源缓存机制的资源加载器,特点是所有特定加载器都共享它来查找并插入缓存资源——CachedResourceLoader类。特定加载器是通过缓存机制的资源加载器来查找是否有缓存资源,它属于HTML的文档对象。
3.3通用的资源加载器——ResourceLoader类,是在WebKit需要从网络或者文件系统获取资源的时候使用该类只负责获得资源的数据,因此被所有特定资源加载器所共享,它属于CachedResource类,与CachedResourceLoader类没有继承关系。
如果说资源缓存和网络资源是浏览器要渲染页面的资源实体,那资源加载器就是为浏览器实现页面渲染提供资源数据的搬运工。前面的资源请求相当于就是资源地址寻址的过程,真正为渲染提供资源的过程是下面这样的:
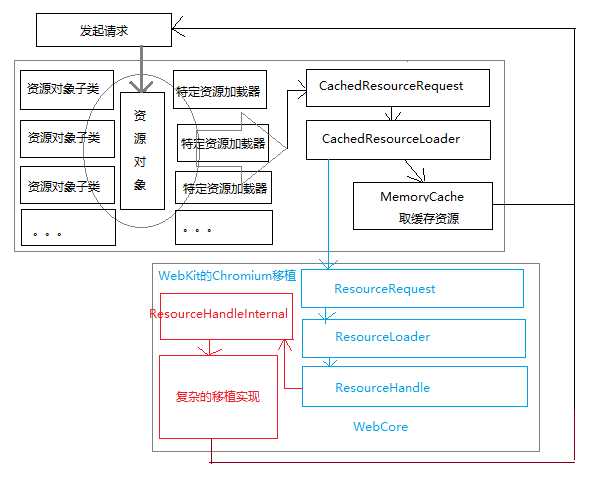
这个资源加载看起来很复杂,但是模块分工很明确,基于资源对象与内存资源缓存的对应关系(每个缓存资源在资源对象上有一个实例),当浏览器触发资源请求时先通过判断资源是否有缓存资源,如果有的话就就直接拿缓存资源给渲染引擎,如果没有就通过网络请求获取资源给渲染引擎,并且同时会将资源缓存到内存中。
同CachedResourceLoader对象一样,资源池也属于HTML文档对象,所以资源池不能无限大,对于资源容量不能无限大的问题浏览器的解决方法有两种:第一种是采用LRU(Least Recent Rsed最近最少使用原则)算法。第二种方法是通过HTTP协议决定是否缓存,缓存多久,以及什么时候更新缓存,然后我们开发时还可决定资源如何拆分,拆分可以让我决定哪些资源缓存,哪些资源不缓存。
当请求协议指定可以取缓存数据,请求资源会先判断内存中是否有资源,然后将资源的信息(版本,缓存时常等)通过HTTP报文一起发送给服务器,服务器通过报文判断缓存的资源是否是最新的,资源缓存是否超时来决定是否重新获取服务端的资源,如果不需要重新获取服务端的资源,服务器会返回状态码304,告诉浏览器取本地缓存资源。
下面通过Chrome浏览器来请求饿了吗官网,在控制台查看数据请求的资源加载过程,并且通过刷新页面查看当页面刷新时浏览器在缓存中取了哪些信息:
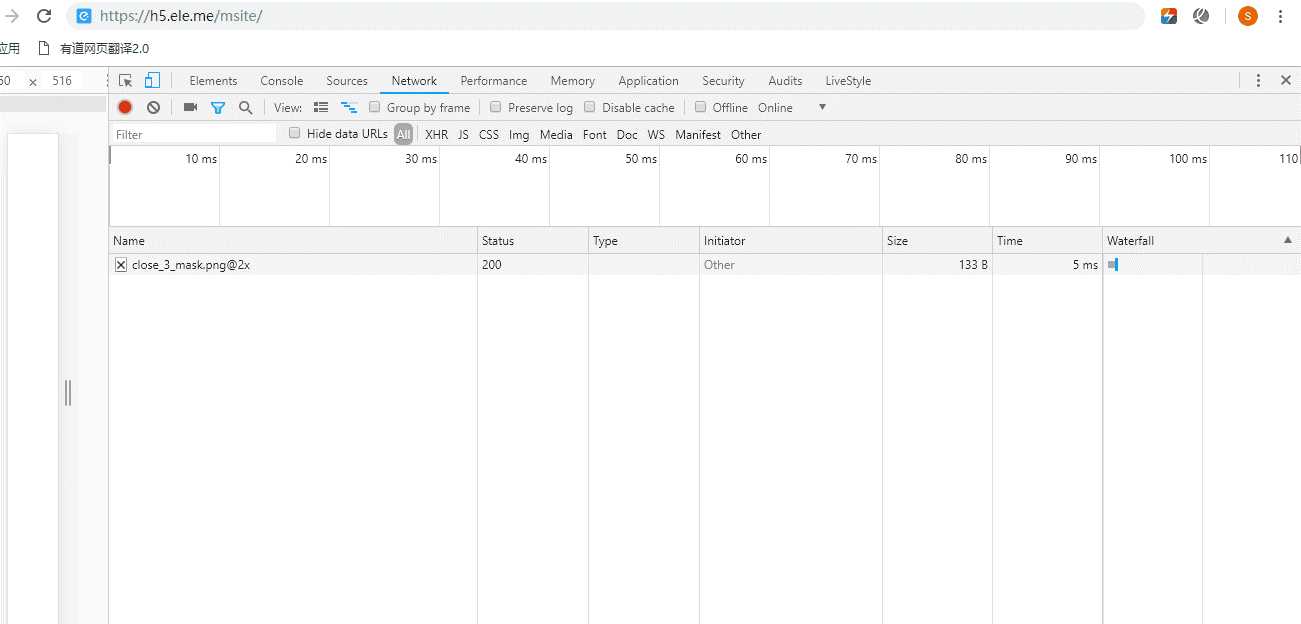
接着我们再来刷新页面看看取了哪些缓存数据:
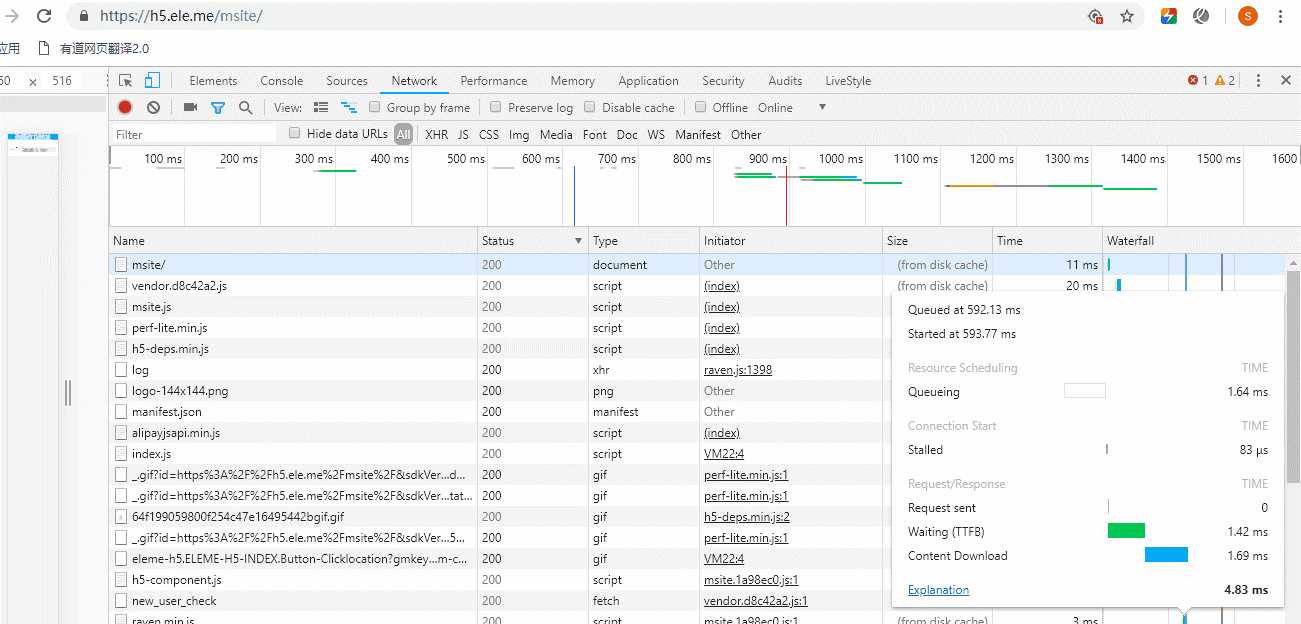
可以看到饿了吗官网的缓存机制是将document主文件和js文件做了缓存处理。这样的处理方式可以很大程度上提高页面性能和降低服务器请求压力,至于为什么就是接下来的内容了。
二、解析HTML标签和CSS样式表、生成DOMTree和CSSTree
前面介绍了浏览器资源请求与资源加载的基本原理,看上去好像是一个简单的线性步骤,但是实质上浏览器内部是多进程异步加载这些资源的,我们知道网页的效果是基于DOM结构和CSS样式表来完成基本的页面效果呈现,但是JS代码又可以对DOM节点进行增删该查操作,还可以修改DOM的CSS样式,那必然就是需要先有DOM结构,然后添加CSS样式,再就这两个资源的基础通过JS修改后才能呈现出来,但是什么时候加载(指的是下载资源,并不是前面的资源加载到页面上的整个过程)?什么时候执行?什么时候渲染页面?按照什么规则来完成这些工作呢。
通常我们给某个服务器发送一个web请求时,首先返回的是一个HTML资源。假设这个资源的内部代码如下:
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <title></title> <link rel="stylesheet" type="text/css" href=".../css/xxx.css"> </head> <body> <div> <p> <span></span> </p> <ul> <li><img src=".../image/xxx.png" alt=""></li> <li><img src=".../image/xxx.png" alt=""></li> <li><img src=".../image/xxx.png" alt=""></li> </ul> </div> <script src=".../javascripts/xxx.js" type="text/javascript"></script> </body> </html>
本地获取到了HTML资源后第一步就是解析HTML,也就是常说的DOM解析,首先是创建一个document对象,然后通过DOM解析出每个节点。通过DOM解析发现页面中有css外部样式表需要加载,就立即通过CSS加载器执行加载。解析到img元素发现需要加载图片,就立即通过图片加载器执行加载,这个过程不会等待前面加载的资源加载完成才启动第二个加载,而是通过异步的方法开启多个加载线程,并且浏览器底层会开启多个进程来处理这些线程(Chrome会开启五个进程)。同样解析到了script元素时发现需要外部js资源会立即加载js文件资源。
深度优先原则解析构建DOM树和CSS树:
深度优先原则就是对每一个结构顺着第一个内部节点一直往内部解析,直到结构尽头,然后再回退到上一个节点,再对第二个节点执行深入优先原则的解析构建。下图是上面示例请求到的HTML资源的解析流程图:
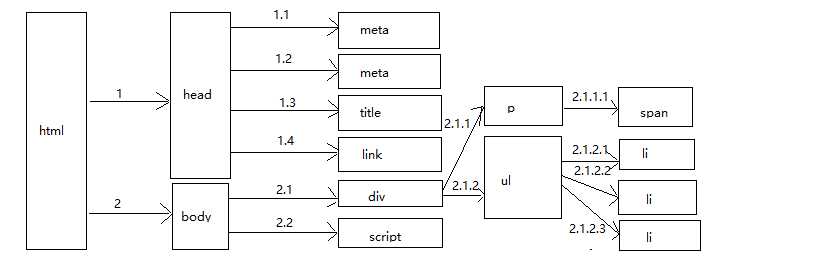
按照示例HTML解析流程图,根据编号顺序按照1-->1.1-->1.2-->1.3-->1.4-->2-->2.1-->2.1.1-->2.1.1.1-->2.1.2-->2.1.2.-->2.1.2.1-->2.1.2.2-->2.1.2.3-->2.2。用一句来表达这种解析原则就是一条道走到黑,开玩笑,但是的确很形象哈。CSS样式表解析和构建CSS树也同样使用这个原则。当DOMTree和CSSTree都构建完成以后就会被合并成渲染树(randerTree)。渲染树解析完毕以后就开始绘制页面。
三、JS与CSS阻塞
了解了DOMTree和CSSTree的构建原理,然后合成randerTree绘制页面,但是这个过程怎么能缺少JS呢?有了JS的参与,这个过程就会变得复杂了。首先,CSS资源是异步加载(下载),在CSS资源加载的过程中,DOM解析会继续执行操作。但是当遇到script标签的时候,如果是外部资源就要立即加载(下载),如果是内部资源就会立即执行JS代码,立即执行JS代码会阻断HTML的解析(因为JS会操作DOM节点增删改查什么的,还会操作元素样式),霸道总裁JS就这样让傻媳妇HTML傻呆着让它为所欲为了。就算是外部JS资源加载(下载)的过程HTML的解析也是被阻断的,这个过程是必须等到JS加载(下载)完,然后还要等他执行完才能继续解析HTML。
<img class="img1" src="https://img.baidu.com/search/img/baidulogo_clarity_80_29.gif" alt="Baidu" align="bottom" border="0"> <script type="text/javascript"> // 循环5秒钟 var n =Number(new Date()); var n2 = Number(new Date()); while((n2 - n) < (10*1000)){ n2 = Number(new Date()); } console.log(document.querySelectorAll(".img1"));//NodeList [img.img1] console.log(document.querySelectorAll(".img2"));//NodeList [] </script> <img class="img2" src="https://gss1.bdstatic.com/9vo3dSag_xI4khGkpoWK1HF6hhy/baike/w%3D268%3Bg%3D0/sign=7aa2c00bdd58ccbf1bbcb23c21e3db03/908fa0ec08fa513defeb0567316d55fbb3fbd9c2.jpg"> <script> var n3 = Number(new Date() - n2); console.log(n3);//13 console.log(document.querySelectorAll(".img1"));//NodeList [img.img1] console.log(document.querySelectorAll(".img2"));//NodeList [img.img2] </script>
由上面的示例可以说明js执行会阻塞DOMTree构建,不然在JS等待的10秒里足够解析一个img元素,但是10秒后只能查询到img1,img2查询不到(打印空DOM节点对象)。当第二次打印的时候两个img节点就都获取到了。接着我们来看看外部JS加载会不会阻塞DOMTree构建:
<script> var n =Number(new Date()); </script> <!-- 设置网速30kb/s测试js是否阻塞渲染 --> <script src="https://cdn.staticfile.org//vue/2.2.2//vue.min.js"></script> <script> var n3 = Number(new Date() - n); console.log(n3);//30~40秒 ---- 注释外部js加载代码测试时间差为0秒 </script>
测试结果是外部JS的加载也会阻塞HTML解析构建DOMTree。所以结论是JS的加载和执行都会阻塞DOMTree的构建,接着问题又来了,我们前面提到过JS代码会操作DOM还会操作CSS,所以从理论上讲JS肯定得需要等到CSS加载解析完才会执行,CSS阻塞JS执行是肯定的,再思考CSS的加载(下载)会阻塞JS的加载(下载)吗?
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Title</title> <link type="text/css" rel="stylesheet" href="https://cdn.staticfile.org/twitter-bootstrap/3.3.7/css/bootstrap.min.css" /> <script src="https://cdn.staticfile.org//vue/2.2.2//vue.min.js" type="text/javascript" charset="utf-8" async defer></script> </head> <body> </body> </html>
我们来看Chrome控制台的时间线:
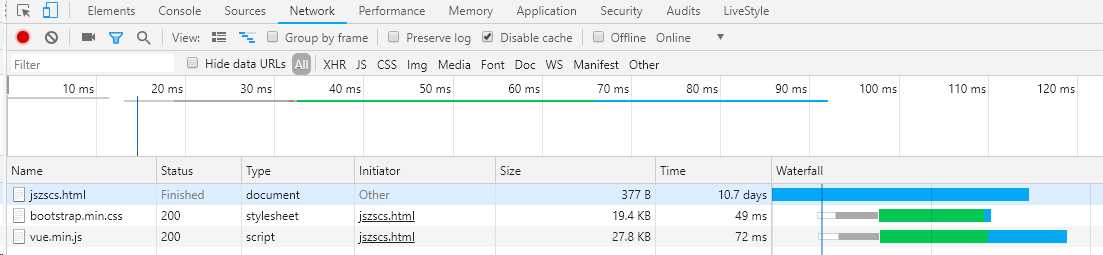
由Chrome控制台的时间线可以看到外部JS和外部CSS几乎是同时开始加载,CSS加载并没有阻塞JS的加载。既然这样我们再来测试以下CSS加载阻塞JS执行是否是真的?
<script> var n = Number(new Date()); </script> <link type="text/css" rel="stylesheet" href="https://cdn.staticfile.org/twitter-bootstrap/3.3.7/css/bootstrap.min.css" /> <script> console.log(Number(new Date()) - n);//外部CSS阻塞JS执行40~200毫秒 --- 注释外部CSS代码测试差值0~1毫秒 </script>
可能有人会疑惑我为什么不测试外部CSS会不会阻塞HTML解析,你想想如果CSS阻塞HTML解析那JS加载必须会被阻塞吧,所以CSS加载也就不会阻塞HTML解析了。但是,CSS会阻塞JS执行,也就间接的阻塞了JS后面的DOM解析。
其实相对来说JS与CSS阻塞还是比较好理解的,毕竟还有可参考的数值和可视的图像信息,接下来的问题就只能依靠逻辑推理了。
四、JS时间线
在阐述JS时间线之前,我另外总结了一部分非常重要的内容:JS的异步加载(JS异步加载的三种方案),JS异步加载与下面的内容相关联的内容比较多,建议在了解下面内容之前先了解一下JS异步加载。
在前面的内容中解析了访问网站获取资源的基本原理,然后资源被访问到本地后怎么解析,解析时发什么的异步资源加载,同步资源加载,同步执行等一系列内容。然后在JS异步加载中提到了script.onload事件、script.onreadystatechange事件、script.readyState状态,然后还有document.readyState="interactive"文档状态和docuement.readyState="complete"文档状态。这些内容都发生在打开网页的那一瞬间,但是这一瞬间不只是检验物理配置的性能、浏览器内核的性能以及网络的性能,还关系到web开发者基于这些已定的基础平台的代码优化,所以我们有必要对这整个过程有非常清晰的理解,才能实现友好的程序设计。下面我们就通过JS时间线来描述这个过程如何发生的:
页面加载的五个步骤和JS时间线的十个环节:
五个步骤:
- 解析HTML生成DOMTree
- 解释CSS样式表生成CSSTree
- 合并DOMTree和CSSTree生成randerTree
- randerTree生成完以后开始绘制页面
- 浏览器在解析页面时同时下载页面内容内容数据(异步:图片,src)
JS时间线之十个环节:
要说是JS时间线的话,可能不是很恰当,或者应该说是文档模型初始化构建过程的JS表示,能够操作DOM对象接口的语言有很多,这里就是用JS来表示DOM对象模型初始化的整个过程。
- 1.创建document对象,开始解析web页面。解析HTML原始和他们的文件内容添加Element对象和Text节点到文档中。阶段:document.readyState = "loading"。(表示可以触发一次document.onreadystatechange事件)
- 2.遇到link外部css,创建线程加载,并继续解析文档。
- 3.遇到script外部JS,并没有设置async、defer,浏览器加载,并阻塞,等待JS加载完成并执行脚本,完后继续解析文档。
- 4.遇到script外部JS,并且设置async、defer,浏览器创建线程加载,并继续解析文档。
- 5.遇到img等外部内容数据,先正常解析DOM结构,然后浏览器异步加载src,并且继续解析文档。
- 6.当文档解析完成后。document.readyState = "interactive"。(表示可以触发一次document.onreadystatechange事件)
- 7.文档解析完成后,所有设置有defer的脚本会按照顺序执行。(禁止使用document.wrlte())。
- 8.document对象触发DOMContentLoaded事件,这也标志着程序执行从同步执行阶段,转化为事件取动阶段。(这里开始绘制页面)
- 9.当所有async的脚本加载完成,img等加载完成后,document.readyState = "complete",window对象触发事件。(表示可以触发一次document.onreadystatechange事件或者标准浏览器可以触发window.onload事件了)
- 10.从此,以异步响应方式处理用户输入、网络事件等。
//readyState属性返回当前文档的状态
uninitialized - 还未开始载入
loading - 载入中
interactive - 已加载,文档与用户可以开始交互
complete - 载入完成--loaded
五、重排/回流与重绘
关于重排/回流(reflow)重绘(repaint)简单来说就是会将已经计算好的布局和构建好的渲染树(randerTree)重新计算和构建全部或者部分。这部分发生在DOMTree和CSSTree解析完成以后,也就是会发生在构建randerTree时和之后,这里我们重点关注发生在randerTree构建时的重排/回流和重绘问题,也是网页渲染除了JS、CSS阻塞之后的性能优化区间。
发生重排/回流与重绘其本质上重新布局和构建randerTree,如果将DOM之前的执行过程理解为同步,这个时候浏览器转为事件取动的异步阶段,浏览器内核在构建randerTree的同时JS也会被事件取动参与修改文档的结构和样式,也是触发重排/回流与重绘行为的关键所在,而本质上做的事情就是重新计算布局和构建randerTree树,所以在解析重排与重绘之前先来了解以下布局计算和randerTree构建:
布局
在构建randerTree时并不会把CSS样式表或者行内样式表示元素大小和位置的数据添加到RanderObject上,而是要基于样式设置(如):width、height、font-size、display、left、top、bottun、right还有borde、padding、margin的大小,结合上下文的相互作用(比如有子元素自适应父级元素大小和位置或者父元素基于子元素定义自身大小和位置),最后使用RanderObject上的layout()方法计算出确定的元素大小和位置,这个过程layout()方法是递归完成整个计算操作。
因为布局计算需要基于元素上下节点来进行,元素的大小和位置变化都有可能会影响到父级和子级的元素大小和位置变化,所以randerTree上的某个RanderObject的相关数据发生变化除了自身的layout()方法需要重新执行计算,还可能会触发上下级的节点的layout()方法的重新执行计算。
所以当构建randerTree的时候由document.onreadystatechange事件、defer的脚本、DOMContentLoaded事件还有不确定的src异步加载的JS脚本都可能在这时候修改元素的大小和位置,甚至修改DOM结构。
除了脚本的影响外,还有可能是浏览器窗口发生产生变化导致全局的randerTree重新布局计算,另外如果脚本修改了全局的样式也同样可能会触发全局的重新布局计算。
重排/回流(reflow)
有了前面对布局的介绍,重排/回流就一目了然了,当由于脚本执行或者浏览器窗口变化,引发RanderObject上的layout()方法重新计算机布局数据,就叫做重排/回流。从字面上的含义来理解重排很容易,就是由于元素的大小和位置变化页面重新排列布局。回流就存在一些逻辑上的理解了,在布局中因为元素节点的位置和大小是存在上下级和同级之间相互影响的,所以如果有脚本修改DOM节点或者大小位置样式,就会对相关连的元素进行判断查找修改的范围指定修改逻辑,制定layout()方法的递归顺序的最优方案,这个查询判断和修改过程就是需要在节点之间来回操作,这也就是回流。实质上重排/回流说的都是一回事。
重绘(repaint)
重绘不会影响布局,但是当脚本触发了样式修改,而修改的部分是背景(图片和颜色)、字体颜色、边框颜色等,而这些修改也存在嵌套的节点链级相互影响,所以也是需要遍历操作,重绘不至于影响到布局,但也是一个相对损耗性能的操作,毕竟都需要DOM文档和JS引擎结构之间的桥梁通道来执行操作。不过重绘相对于重排来说就要快的多了。
重排/回流与重绘是会发生在randerTree构造时,也会发生在randerTree构造结束后,都是相对损耗CPU甚至GPU的操作,只是页面首次渲染更值得的我们关注。
绘制(paint)

当randerTree构建完成以后就会开始绘制页面了,在绘制页面过程中仍然可能发生重排与重绘,但这里需要重点关注的是图层合并,绘制主要是基于CPU的计算来实现,同时浏览器基本上都采用GPU加速的混合模式,其实浏览器本身不需要操作图层合并,因为绘图不管是CPU还是GPU来实现都是基于元素的大小和位置将它们实现的图层,图们本身就在同一个位置,所以无需合并操作。
CPU主要负责randerTree的绘制工作,它与GPU的配合在不同浏览器内核中会略微不同,但是在同一个位置出现的图层越多,肯定是对性能的损耗就越大。而且由于CPU主要负责randerTree的绘制,多图层就会对GPU带来很大的工作负载,具体包括:CSS3 3D变形、CSS3 3D 变换、WebGL 和 视频。也有浮动,定位,溢出隐藏,z坐标重叠等都是在绘制过程中比较损耗性能的行为。

最后经过这样艰难的过程过后,网页终于呈现在我们桌面,但是注意window事件交互不会等待绘制完成,决定window事件交互的是资源是否全部加载完成,这里指的资源是HTML文档包含内容资源,并不包含外部脚本加载的资源。
(减少重排与重绘的一些要点)


1 1:不要通过父级来改变子元素样式,最好直接改变子元素样式,改变子元素样式尽可能不要影响父元素和兄弟元素的大小和尺寸 2 2:尽量通过class来设计元素样式,切忌用style 3 3:实现元素的动画,对于经常要进行回流的组件,要抽离出来,它的position属性应当设为fixed或absolute 4 4:权衡速度的平滑。比如实现一个动画,以1个像素为单位移动这样最平滑,但reflow就会过于频繁,CPU很快就会被完全占用。如果以3个像素为单位移动就会好很多。 5 5:不要用tables布局的另一个原因就是tables中某个元素一旦触发reflow就会导致table里所有的其它元素reflow。在适合用table的场合,可以设置table-layout为auto或fixed, 6 6:这样可以让table一行一行的渲染,这种做法也是为了限制reflow的影响范围。 7 7:css里不要有表达式expression 8 8:减少不必要的 DOM 层级(DOM depth)。改变 DOM 树中的一级会导致所有层级的改变,上至根部,下至被改变节点的子节点。这导致大量时间耗费在执行 reflow 上面。 9 9:避免不必要的复杂的 CSS 选择器,尤其是后代选择器(descendant selectors),因为为了匹配选择器将耗费更多的 CPU。 10 10: 尽量不要过多的频繁的去增加,修改,删除元素,因为这可能会频繁的导致页面reflow,可以先把该dom节点抽离到内存中进行复杂的操作然后再display到页面上。 11 11:请求如下值offsetTop, offsetLeft, offsetWidth, offsetHeight,scrollTop/Left/Width/Height,clientTop/Left/Width/Height,浏览器会发生reflow,建议将他们合并到一起操作,可以减少回流的次数。
以上是关于浏览器加载解析渲染网页原理的主要内容,如果未能解决你的问题,请参考以下文章